
Databricks では近年、独立した新しいデータ管理のためのオープンアーキテクチャである「データレイクハウス」を利用する多くのユースケースを見てきました。今回は、この新しいアーキテクチャと、かつてのアプローチであるデータウェアハウス(DWH: Data Warehouse)、データレイク(Data Lake)それぞれと比較して優れている点について解説します。
データウェアハウス(DWH)とは
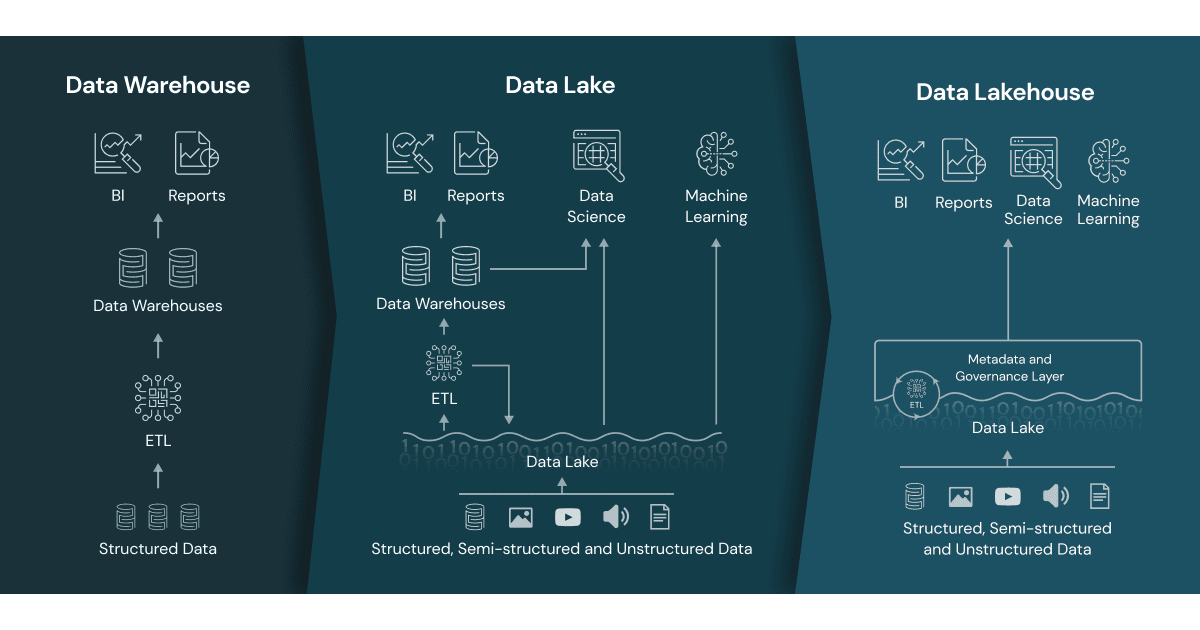
データウェアハウス(DWH)とは、膨大な量のデータを利用者の目的に応用しやすくするため、整理・格納する管理システムのことを指します。意思決定支援や BI(ビジネスインテリジェンス)アプリケーションにおいて広く利用されてきており、これには長い歴史があります。データウェアハウスの技術は、1980 年代後半の登場以来進化を続け、MPP アーキテクチャなどの並列処理技術の進歩によって、より大規模なデータ処理が可能なシステムがもたらされました。しかし、データウェアハウスには、エクセルで作成されたような構造化データ(あらかじめ決められた管理構造に従って格納されたデータ)の処理には適しているが、非構造化・半構造化データといったそのままでは利用できない複雑なデータ(文章や音声、画像など)の処理には適していないという問題があり、近代ビジネスが必要とする高速で多様なデータの大規模処理においては課題がありました。データウェアハウスは、そういった最新のデータ処理を前提としたユースケースには適しておらず、コスト効率的にも最適なソリューションではありません。
データレイク(Data Lake)とは
データレイクは、規模に関係なく、画像・動画・メールのログなどの非構造化データを、生データのまま格納できる場所のことを指します。
データウェアハウスの利用が進み、多くの企業で複数のソースからの膨大なデータ収集が可能になるにつれて、アーキテクトによる単一システムの構想が生まれました。さまざまな分析プロダクトやワークロードのデータを単一のシステムに集約するという構想です。そしておよそ 10 年前に多様な形式の生データ用レポジトリ(保管場所)である「データレイク(Data Lake)」の構築が始まりました。データレイクはデータの格納には適していました。しかし、重要な機能が欠けており、トランザクションのサポートやデータ品質の保証がありません。一貫性と分離性の欠如により、アペンド(データをファイルなどに追加する操作)と読み取り、バッチとストリーミングジョブ(データをリアルタイムで処理)を混在させることはほぼ不可能です。データレイクは、これらの理由から本来の目的の達成には至っておらず、データスワンプ(活用ができないデータが大量に溜まっている)状態となっているのが実情です。
一方で、柔軟で高性能なシステムに対するニーズは高まり続け、多くの企業が、SQL 分析、リアルタイムの監視、データサイエンス、機械学習など、多様なデータアプリケーションに対応するシステムを必要としています。AI を最大限に活用するには、非構造化データ(テキスト、画像、動画、音声など)の処理能力を高めることが不可欠ですが、非構造化データはまさに、データウェアハウスが得意としないデータ形式です。非構造化データの処理には、一般的に複数のシステムが使用されます。データレイクと複数のデータウェアハウスに加えて、ストリーミング、時系列、グラフ、画像データベースのような特殊システムなどが導入されます。複数のシステムの使用は複雑さを招き、さらに大きな問題となる遅延を引き起こします。異なるシステム間のデータの移動やコピーが必要になるためです。
このような状況から、データウェアハウスの分析力とデータレイクの拡張性の両方を持ち合わせた新しいアーキテクチャが求められています。
次世代のデータ管理システム
データレイクハウスとは
データレイクの限界に挑む新しいシステムとして登場したデータレイクハウスは、データレイクとデータウェアハウスの優れた要素を取り入れた新しいオープンアーキテクチャです。新たなシステムデザインによって構築されており、データウェアハウスと類似のデータ構造とデータ管理機能を、オープンフォーマットで低コストのクラウドストレージに直接実装しています。データレイクハウスは、安価で信頼性の高いストレージ(オブジェクトストア形式)が利用可能になった今、最新のニーズに対応するデータウェアハウス構築のための最善策と言えるでしょう。
データレイクハウスの主な特徴は次のとおりです。
- トランザクションのサポート:エンタープライズにおけるデータレイクハウスでは、多くのデータパイプラインがデータの読み取り・書��き込みを同時に行います。ACID トランザクションのサポートにより、SQL などを利用したデータの読み取り・書き込みを複数のユーザーが同時に実行する場合でも一貫性が保たれます。
- スキーマの適用とガバナンス:データレイクハウスは、スタースキーマ、スノーフレークスキーマなどの DW スキーマのアーキテクチャをサポートし、スキーマの適用と進化をサポートすることを期待されています。システムはデータの整合性を判断する能力および、堅牢なデータガバナンスと監査メカニズムを備えていなければなりません。
- BI ツールをサポート:データレイクハウスでは、ソースデータに対して直接 BI (ビジネスインテリジェンス)ツールを使用できます。これにより、データの陳腐化の低減、最新性の向上、レイテンシー(データ転送における通信の遅延時間)の低減が可能になり、データレイクとデータウェアハウスの両方でデータコピーを重複して保持することによるコストを削減します。
- コンピューティングとストレージを分離:これは、ストレージとコンピューティングが別々のクラスタを使用することを意味します。したがって、同時に利用するユーザー数やデータサイズの増大にあわせた拡張が容易になります。最新のデータウェアハウスの中には、このような特徴を持つものもあります。
- オープン性:データレイクハウスでは、Parquet のようなオープンで標準化されたストレージ形式が使用されています。API ��を提供し、機械学習や Python/R ライブラリなど、さまざまなツールやエンジンからデータへの効率的な直接アクセスを可能にしています。
- 構造化・非構造化データのサポート:データレイクハウスは、構造化、非構造化、半構造化データをサポートし、画像、動画、音声、テキストなど、最近のデータアプリケーションに必要なデータ形式の保存、調整、分析、アクセスを可能にします。
- 多様なワークロードのサポート:データレイクハウスは、データサイエンス、機械学習、SQL、分析など、さまざまなワークロードをサポートします。ワークロードの種類によっては専用のツールが必要な場合もありますが、その場合でも、同じデータリポジトリが使用されます。
- エンドツーエンドのストリーミング:企業の多くがリアルタイムのレポート作成を当然のこととしています。データレイクハウスでは、ストリーミングがサポートされるため、リアルタイムのデータアプリケーション専用のシステムを別途用意する必要がありません。
データレイクハウスの上記のような特徴の他に、エンタープライズグレードのシステムでは追加機能が必要となります。例えば、セキュリティやアクセス制御の機能です。昨今のプライバシー規制に対応するための監査、保持、リネージなどのデータガバナンス機能は不可欠になっており、データカタログやデータ使用量指標などのデータを抽出するためのツールも必要です。データレイクハウスでは、このようなエンタープライズ機能を単一のシステムに対して実装、テスト、管理するだけですみます。
データレイクハウスの内部機能について詳しくは、研究論文をご参照ください。


