ミネソタ・ツインズにおける投球シナリオのスケーリング - Part 1

野球の試合における統計分析
メジャーリーグベースボール(MLB)では、投球フォーム、球種や回転数などの投球内容、各選手の打球の動作に至るまで、1 回の投球当たり数十メガバイトのデータが生成されています。1 試合、1 シーズンの間に、これらのデータからいかにして実践可能な気づきを導き出すのでしょうか。2019 年度アメリカン・リーグ中地区優勝チームのミネソタ・ツインズ内の BOG(Baseball Operations Group)は Databricks を導入しています。このブログでは、BOG が Databricks を活用して膨大なセンサーデータを収集し、各投球のシミュレーションを数千回、数万回と実行し、実践可能な気づきを迅速に導き出し、選手の成績の分析やパフォーマンスの改善、競合の偵察、才能評価の改善に役立てる方法を紹介します。ミネソタ・ツインズではさらに、分析サイクルを高速化し、得られた気づきを素速くコーチ陣に伝達することで、試合中の戦略におけるリアルタイム性を高める方法を模索しており、それについても解説します。
ミネソタ・ツインズのフロントオフィスでは、投球に関するデータを用いて数千回のシミュレーションを実行し、選手の評価モデルの改善に役立てています。Part 1 では、そのシミュレーションにおける課題を取り上げ、R による投球結果のモデル化・推論を行う際のトレードオフを明らかにし、R のユーザー定義関数を Spark で使用することを選択した理由を解説します。
Part 2 では、Spark での R のユーザー定義関数の使用をさらに掘り下げていきます。また、UDF 内での R の挙動に加えて、実行を指揮する Spark の挙動を確認することで、性能を最適化してスケーラビリティを向上させる方法をご紹介します。
Databricks 101: 実践入門

背景
打率や打点など、野球選手の成績評価に使用できる離散的な野球統計学はいくつかありますが、セイバーメトリクス野球コミュニティは、選手のチームへの総合的勝利貢献度を評価するWAR(総合評価指標)を開発して、選手の比較を容易にしました。FanGraphs.comより抜粋:
選手を評価する際には、複数の測定基準を設ける必要がありますが、WAR には全ての要素が含まれていて、選手の比較に役立つ基準点を設けています。WAR は期待値を利用して答えを出します。「この選手が負傷して、制約のないマイナーリーグの選手(X)、またはベンチ入りしているが AAAA 級の選手(Y)(マイナー以上メジャー未満の選手)と交代しなければならない場合、チームが失う価値はどのくらいか?」この値は勝利形式で表されます。チームに対する勝利貢献度に関して、選手Xの価値が+6.3 なのに対し選手 Y の価値は+3.5 の場合、選手 Xと 交代した方が勝利を期待できる可能性が高いことを示しています。
従来、数百回、数千回の投球データを使用して選手のWARを比較することが相対的な価値を測定する最善策でした。ミネソタ・ツインズでは、最終的な結果(ボール、ストライク、ヒットなど)以外にも球速、球種、打球の初速、選手のポジショニング、投手力(FIP)などの詳細なデータを含めて、1,500万を超える投球の分析に使用できるデータを保有していました。分析に使用する投球には、打者との相性や天候など、試合中の得点期待値に影響を及ぼす変動要素を考慮する必要があります。(例:強風の影響でホームランになるはずだったものがファウルボールになる)では、将来のパフォーマンスを正確に予測するには、どのように変動要素を調整したらよいでしょうか?
金融サービス業界などは、大数の法則に基づき、過去データを使用してモンテカルロシミュレーションを実行し、確率モデルの精度を高めています。野球でも同様に、シナリオが100倍に増えると、WARの期待値が10倍も正確になります。(1回の投球を1つのシナリオとしています)ミネソタ・ツインズは、得点期待値の精度を高めるために、膨大な数のシナリオを短時間で分析できるソリューションを探しました。データベース内の投球は最大20,000回のシミュレーション、または最大で合計3,000億のシナリオ(3,000億のシナリオ= 1,500万回の投球× 投球ごとに最大20,000回のシミュレーション)を生成します。この分析を単一ノードのBase Rを使用してオンプレミス環境で実行すると、過去データを算定するのに4年近く(投球ごとに20,000回のシミュレーションを行う時間約8秒×1,500万回の投球/年間3.15×107秒)かかる可能性があることが分かったのです。また、最終的に、得点価値やWARの期待値を使用した40,000を超える評価対象のシナリオが生成される試合における決定を最適化するには、以下の2点を改善する必要があることもわかりました。
- 大量のコンピューティング能力の起動にかかる時間
- 予測精度を向上し、リアルタイムで実用的な洞察を生成するために、新たな野球データを常に追加できるモデル
ミネソタ・ツインズは抱えていた課題を考慮した結果、構造化データと非構造化データのどちらも含む膨大なデータセットの取り扱いの実績を重視し、DatabricksとMicrosoft Azureの導入を選択しました。このソリューションの導入で、ミネソタ・ツインズはクラウドで利用可能なほぼ無制限のオンデマンドのコンピューティング能力の活用ができるようになり、過去データの分析時に生じる一時的なスパイクに備えた使用中のハードウェアのプロビジョニングを心配する必要がなくなりました。また、これまで44分程度かかっていた毎日の40,000回のシミュレーションは、DatabricksをAzureと連携させることで、データが生成される度にリアルタイムでの評価ができるようになりました。
投球シミュレーションの結果を100倍に拡大
投球結果をRでモデリング・推測する
データサイエンス部門は、投球結果をモデル化する際に、投球位置の座標に加えて、投手と打者の利き手やイニングなどのシーズンと試合の特徴を含め、1,500万行からなるトレーニングデータセットを作成し、モデル内に投球結果の非線形特性を取り込むRのエコシステムで利用可能なオープンソースパッケージの膨大なレポジトリを検討しました。
最終的には、非線形分布のモデル化に、優れた柔軟性と解釈性で特に有用なRのパッケージを選択しました。これにより、データサイエンティスト部門は、過去データに複雑なモデルを適合させることができ、予測因子が投球結果に与える正確な効果を理解することができます。これらのモデルは選手の成績やチーム構成の評価に役立つため、モデルの優れた解釈性はコーチおよび組織とって考慮すべき重要な事項でした。
さまざまな投球結果のモデル化を進めていくうちに、データ部門はデータセット内の各投球に対するX-Y座標の同時確率分布のシミュレーションにRを使用するようになりました。効果的に生成された追加レコードは、トレーニング済みモデルで評価できるようになり、シミュレーション済みの各投球に対する所定の投球結果を推測することで、選手に期待する成績のイメージの描写が可能になりました。シミュレーション数が増えれば、イメージはより鮮明になります。
過去のデータセット内にある1,500万行について、一つずつ20,000回のシミュレーションを生成する計画が立てられました。これにより、非線形モデルで推測可能な状態の3,000億のシミュレーション済み投球に関する最終データセットが得られ、選手をより正確に評価するデータが組織に提供されることになります。
しかし、このアプローチの問題は、本来Rはシングルスレッドで単一ノードの実行環境で機能することでした。オープンソースで利用可能なマルチスレッドのパッケージと、クラウド内のCPU使用率が高いVMを活用して正常に終了したとしても、コ��ード化が完了するまでに数か月程度かかることが予測されました。この問題は評価基準の一つとなりました。どうすれば、シミュレーションと論理的推論を3,000億行までスケーリングし、妥当な時間内にジョブを終了できるでしょうか?この問題を解決したのは、Apache Sparkを搭載したDatabricksの統合分析プラットフォームです。
SparkでRをスケーリングする
このシミュレーションのパイプラインをスケーリングする最初のステップは、SparkをRから利用可能にする2つのパッケージ(SparkRとsparklyr)のいずれかと連動させるために、特微量エンジニアリングコードのリファクタリングを行うことでした。幸いにも、一般的なデータ操作パッケージのdplyrを使った論理式で記述されていたので、sparklyrと密接に統合します。この統合により、sparklyrでのデータの読み取り時に作成されるtbl_sparkのオブジェクトにdplyr関数を使用できるようになります。この例では、いくつかのifelse()文をdplyr::mutate(case_when(...))に変換するだけで、その後、特微量エンジニアリングのコードがSparkで単一ノードプロセスを大規模な並列ワークロードに拡張されます。実際には、既存のdplyrコードのうちおよそ10%しか、Sparkと連動させるためのリファクタリングを必要としませんでした。今では、わずか数分で数十億の推測結果の行を生成できます。
この魔法のようなdplyrはどのように機能するのでしょう?この点を理解するには、まず、SparkへのRインターフェイスの構造を知ることが必要です。
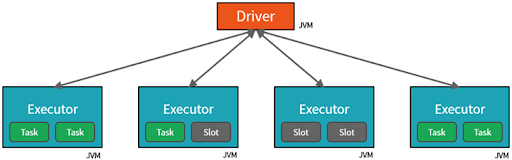
RコードはScalaに変換され、それらのコマンドは各ワーカーにタスクを割り当てるドライバのJVMに送られます。同じように、dplyr verbはSQL式に変換された後、SparkSQLを使ってSparkで評価されます。その結果、SparkとRのパッケージの組み合わせは、Scalaで予想しうる動作と同じパフォーマンスが得られるはずです。
Rのパッケージを使用した分散推論
Sparkで実行する特微量エンジニアリングのパイプラインによって、モデル推論のスケーリングに対して意識が向けられました。検討したのは、以下に示す3種類のアプローチです。
- Sparkで非線形モデルを再トレーニングする
- Rからモデル係数を抽出し、Sparkでスコア化する
- ユーザー定義関数にRのモデルを埋め込み、Sparkで並行実行する
各アプローチに関連する実現可能性とトレードオフについて、簡単に考察してみましょう。
Sparkで非線形モデルを再トレーニングする
最初のアプローチは、Rによるモデリング手法の実装がSparkの機械学習ライブラリ(SparkML)に存在するかどうかを確認することでした。ほとんどのケースで、モデルタイプの利用が可能であれば、性能、安定性、シンプルなデバッグといった点から、SparkMLは最高の選択です。RまたはPythonから始めた場合は、コードのリファクタリングが多少は必要かもしれませんが、スケーラビリティの向上で容易に価値を見出せます。
残念ながら、データ部門が選んだモデリング手法はSparkMLで利用できませんでした。学界ではこの手法を利用した前例もありますが、Sparkのコードベースに修正を加える必要があるので、他のアプローチに期待して、このアプローチは優先度を下げるよう方針を固めました。このコードのリファクタリングおよび維持するために必要な膨大な業務量を考慮すると、このアプローチの適用は論外でした。
モデル係数を抽出する
Sparkを再トレーニングできないのなら、Rモデルの学習係数をSparkのDataFrameに適用できるのではないか—2つめのアプローチの発想は、小規模な係数のDataFrameで特徴をインプットするDataFrameを予測値に届くまで乗算することで、推測を実行可能にすることです。しかしやはり、スケーラビリティと性能を向上させるには、RからSparkへの係数抽出をオーケストレーションするコードのリファクタリングが必要になるトレードオフが考えられます。
このタイプの非線形モデルと連動するアプローチには、モデル係数に加えて線形予測因子のマトリクスの抽出が必要です。使用中のRのパッケージの性質上、Rモデルのオブジェクト自体から新たなデータを渡さなければこのマトリクスを生成することはできません。3,000億行から線形予測因子のマトリクスを生成することはRでは実行不可能なため、この2つめのアプローチも断念せざるを得ませんでした。
Sparkのユーザー定義関数でRを並行実行する
データ部門は、このようなSparkでの特殊な非線形モデリングのアプローチに対する固有のサポートの欠如と、Rで3,000億行のマトリクスを生成する無益性を考え、次にSparkRとsparklyrのユーザー定義関数(UDF)に目を向けました。
UDFを理解するには、少し戻って前述したSparkとRの構造を見直す必要があります。
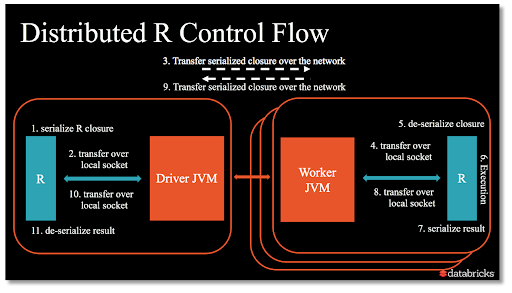
各ワーカーにUDFでRのプロセスを作成することで、クラスタ全体で任意のRコードを並列に実行できるようになります。これらの関数はSparkのDataFrameのパーティションまたはグループに適用でき、SparkのDataFrameとして結果を返します。別の見方をすると、各ワーカーがUDFでRのコンソールにアクセスできるようにして、そこでR関数をデータに適用する機能を使用し、結果をSparkに返します。
SparkMLで利用できないモデルタイプを有する数十億行の推測を実行するために、SparkのDataFrameにシミュレーションデータを読み込み、SparkR::dapplyを使って各パーティションにR関数を適用しました。関数の高度な構造は以下のとおりでした。
- Databricks ファイルシステム(DBFS)の記憶域にRモデルを読み込む
- Rで予測する
- 結果のデータフレームをSparkに返す
- SparkのDataFrameの結果に出力スキーマを指定する
DBFSはクラウドストレージを指すクラスタ内の各ノードにマウントされたパスで、Rからアクセス可能です。これにより、Sparkでネットワーク全体のモデルを変数としてブロードキャストすることなく、ワーカー自身にモデルを読み込みやすくなります。最終的には、3つめのアプローチが良い成果をもたらし、データサイエンティスト部門はSparkを活用して数十億行の分散推論に対してRでトレーニング済みのモデルをスケーリングできるようになりました。
まとめ
このブログ記事では、MLBチームのミネソタ・ツインズのためにRで記述されたシミュレーション、および選手評価のパイプラインのスケーリングするさまざまなアプローチを考察しました。また、各アプローチのトレードオフ、基幹的なSparkR/sparklyrとユーザー定義関数の機能の違いを確認して、何を選択すべきかを説明しました。
特微量エンジニアリングからモデルのトレーニング、係数の抽出、ユーザー定義関数に至るまで、Rのエコシステムの能力をビッグデータにスケーリングするための多くの選択肢が存在することは明らかです。
次回の投稿では、SparkでRを利用したユーザー定義関数について、さらに深く掘り下げます。また、UDF内でのRの挙動に加えて、実行を指揮するSparkの挙動を確認することで、性能を最適化してスケーラビリティを向上させる方法をご紹介します。
ミネソタ・ツインズのストーリーPart 2 を読む:Apache SparkとRによるユーザー定義関数の最適化