Apache Spark™ と R によるユーザー定義関数の最適化と実用化 —ミネソタ・ツインズにおける投球シナリオのスケーリング–Part 2

序章
Part 1 では、ミネソタ・ツインズの BOG(Baseball Operations Group)が、選手の成績をより正確に評価するために、過去 1,500 万回の投球ごとに 2 万回、合計 3,000 億回のシミュレーションを実行する必要があったことをお話ししました。BOG のアイディアはシンプルです。 過去 1,500 万回の投球から選手の成績をイメージ化できれば、各選手の分布に従った 3,000 億球のシミュレーションデータからは、より鮮明なイメージと信頼性の高い評価が得られることが想定できます。 このデータは、より多くの勝利を生み出してクラブの収益を上げることを目的とするコーチや人事の決定に影響を与えます。
データを生成・記録するスクリプトと機械学習モデルは全て R で記述されており、これらのスクリプトをマルチスレッドのパッケージを使用して R で実行する場合でも、全てのシミュレーションを��処理するには時間が 3.8 年かかると推定しました。Apache Spark のユーザー定義関数(UDF)と Databricks を組み合わせることで、過去のデータセットの 3,000 億回のシミュレーションにかかるデータ処理時間が 2~3 日に短縮され、試合中のデータについては、ほぼリアルタイムで処理できます。試合中の投球をほぼリアルタイムで記録可能にすることで、ミネソタ・ツインズは最終的に、打者、天候、イニング、最終投球から読み取る速度と回転を組み合わせた測定値を仮定して最適な投手と投球を選択するなど、試合中のさまざまな条件に基づく出場メンバーと戦略決定の最適化を目指しています。
Rのパッケージの膨大なエコシステムにSparkの拡張性と並列性を組み合わせると、UDFはスポーツ以外のあらゆる業界におけるユースケースでも高い性能を発揮できます。ミネソタ・ツインズにおけるモデル推論のユースケースに加えて、以下の用途も検討していきます。
- Prophetのような時系列パッケージを使用した、何千種類もある消費財の販売予測の生成
- 金融ポートフォリオの運用パフォーマンスを数百件まとめてシミュレーション
- 車両群の輸送スケジュールのシミュレーション
- 何千ものハイパーパラメータを並行して検索して、最適なモデルを見つける
これらの用途は、非常に魅力的ではありますが、実現にはトレードオフを伴います。経験者に話を聞けば、容易に拡張できるUDFの導入がいかに困難であるかを教えてくれるでしょう。その理由は、クラスタのコア数とメ�モリ、ならびにその間の関係性の効率的な制御の必要性です。成功の鍵は、Sparkが線形にスケーリングできるようにジョブを構築することです。
この記事では、スケーラブルなUDFの作成に必要な要素を探求します。成功の鍵を握るのは、ストレージ、Spark、R、およびそれらの間の相互作用を理解することです。
Spark と R で UDF を理解する
SparkR や sparklyr を使う場合、R コードは通常、Spark の元来の言語である Scala に変換されます。このようなケースでは、R のプロセスが Spark クラスタのドライバノードに制限される一方で、残りのクラスタは Scala でタスクを完了します。ただし、ユーザー定義関数は各ワーカーがRのプロセスにアクセスできるようにして、Spark DataFrameの各グループか各パーティションにR関数を並列に適用させた後、結果を返します。
Spark はどのようにこれらを仕切るのでしょうか。下の図は、制御フローを示しています。
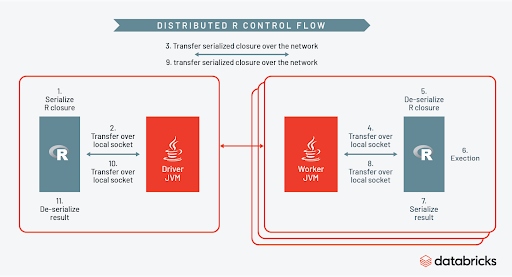
それぞれのタスクの一部として、Sparkは各ワーカーにRのセッションを一時的に作成し、Rのクロージャをシリアル化した後クラスタ全体にUDFを分配します。各ワーカーのRのセッションがアクティブである限り、Rのエコシステムのあらゆる能力をUDF内部で活用できます。Rコードが実行し�終わると、セッションは終了し、Sparkコンテキストに結果が返されます。さらなる詳細については、この講演とこのブログ記事を参照してください。
Databricks 101: 実践入門

UDF を正しく扱う
「やらないに越したことはない」 [1]
UDFの動作方法に関する基本的事項を理解したところで、次はシステムに起こりうる障害と、それらの障害を取り除く方法について詳しく見ていきましょう。これらの関数を記述する際に把握しておくべき4つの主要な事柄は以下のとおりです。
- データソース
- Spark内でのデータ転送
- SparkとR間でのデータ転送
- Rのプロセス
1. データソース:ストレージ I/O を極力抑える
最初のステップとして、ストレージ内でデータをどのように整理するか計画を立てます。Rユーザーの多くはフラットファイルでの作業に慣れているかもしれませんが、重要な原則はUDFが正しく動作するよう必要なデータのみ取り込むことです。ジョブの大部分はストレージ間のI/Oで、現在のデータが(CSVのような)最適化されていないファイル形式ならば、Sparkはメモリにデータセット全体を読み取ることが必要となる場合があります。これは、あまりにも時間がかかり非効率です。特に該当ファイルの一部のコンテンツしか必要でないときは顕著です。
そのため、Delta Lake のようなスケーラブルなフォーマットにデータを保存することをお勧めします。Delta Lake は、ストレージのデータをパーティションに分割し、パーティションのサイズを最適化してZオーダーを使った二次索引を作成することで、Sparkへの取り込みを高速化します。こうした機能を組み合わせることで、UDF内でアクセスが必要なデータ量を制限しやすくなります。
理由はこうです。ストレージ内の野球データを投球のタイプ別に分けて、「カーブ」の行を読み取るよう Spark に指示を出したとします。この際にDelta Lake を使用することで、「カーブ」を除く全ての行の取り込みを省略でき、取り込むデータを少なくすることで、読み取り速度は飛躍的に向上できます。つまり、データの10%のみにカーブの投球が含まれている場合、実質的にデータセットの90%をメモリに読み込まずに済むのです。
Delta Lake のようなストレージレイヤとUDFで処理されるデータに対応するパーティション分割を使えば、強固な基盤を確立し、ジョブの滞在的なボトルネックを解消できます。
2a. Spark でのデータ転送:メモリ内のパーティションサイズの最適化
メモリ内のパーティションサイズは、特微量エンジニアリングやELTパイプライン、最終的にはUDF自体のパフォーマンスに影響を及ぼす可能性があります。多くの場合、Sparkが広範な変換(joinまたはgroup byなど)を実行せざるを得ないときには必ず、クラスタ全体でデータをシャッフルする必要があります。デフォルトではシャッフル後のパーティション数が任意で200個に設定されていて、シャッフル実行時にSpark DataFrameのデータが200個のパーティションに分割されることを意味します。
これでは、データのサイズによって非効率になるおそれがあります。データセットが小さい場合、200個のパーティションは作業を過剰に並列化することになり、オーバーヘッドに関する不要な計画やデータがほとんどないタスクが生じる可能性があります。データセットが大きい場合は、並列化が足りず、クラスタのリソースを効率的に使用できないかもしれません。
一般的な経験則として、シャッフル後のパーティションサイズを128~200 MBの間に保つと、ディスクへのデータ流出を回避��しつつ並列化を最大限に有効活用できます。シャッフル後に必要となるパーティション数を特定するには、Spark UIを使用して最長のジョブに対しシャッフル読み取りサイズを並び替えます。最大のシャッフル読み取りステージで128 MBごとにサイズを分割すれば、ジョブに対する最適なパーティション数を割り出せます。その後、spark.sql.shuffle.partitionsを次のようにSparkRに設定できます。
動的にパーティション変更したSpark DataFrameも、シャッフルが必要な上記の設定の影響を受けます。ご覧のとおり、この挙動は、ガベージコレクションやSparkとR間でのデータ転送のようなシステムの他の要素におけるメモリ負荷の制御に使用できます。
2b. Spark 内でのデータ転送:ガベージコレクションとクラスタサイズのスケーリング
ビッグデータの問題を抱えているのなら、ブルートフォース方式を採用して最大のワーカータイプを求めることは魅力的に感じる場合がありますが、解決策はそれほど簡単ではないかもしれません。Java仮想マシン(JVM)のガベージコレクションは、メモリ内に不要となった大きなオブジェクトが残っている場合、制御不能になる傾向があります。もともと大きなオブジェクトをいくつも作成できる空き容量が存在するため、どんなに大型のワーカーを使用しても、この問題を悪化させる可能性があります。したがって、メモリ内のオブジェクトサイズを制御することは、ソリューションアーキテクチャで��考慮すべき重要事項です。
こういった特殊なジョブにおいて、少数の大規模なワーカー、または多数の小規模なワーカーは、多数の中規模なワーカーと同様の機能は果たさないことがわかりました。大規模なワーカーはガベージコレクションを過剰に生成した結果ジョブを無期限にハングさせ、小規模なワーカーは単にメモリ不足になりました。
対応策として、JVMのガベージコレクションが適切に処理可能なRAMおよびCPUの中間域に入るまで、ワーカーのサイズを徐々に大きくしました。また、UDFへのSparkの入力データフレームをパーティション変更して、パーティションを増やしました。どちらの対策もJVMのオブジェクトサイズを制御する上で有効で、ガベージコレクションはSparkの実行プログラムごとにかかる総作業時間の10%未満に維持できました。さらに多くのレコードを記録する必要がある場合は、クラスタに中規模のワーカーを追加するだけで、入力データフレームのパーティション数を直線的に増やすことができます。
3. Spark と R 間でのデータ転送
検討すべき次のステップは、SparkとR間でどのようにデータが受け渡されるかでした。ここで、私たちは起こりうる障害を2つ特定しました。総I/Oとプロセス間で発生するシリアライズやデシリアライズです。
まず、UDFの適切な動作に必要なものを限定して入力します。ストレージからのI/O読み取りを最適化する方法と同様に、UDFに必要な該当の列のみを含めるようにSparkの入力データフレームをフィルタリングします。Spark DataFrameに30列あり、そのうち4列のみUDFに必要な場合、データを適宜サブセット化し入力として代わりに使用します。I/Oおよび関連するシリアライズやデシリアライズを減らすことで、動作速度が高速化されます。
入力データを適切にサブセット化してもメモリ不足の問題が解消しないときは、パーティション変更によってSparkとR間でのデータ転送量を制御しやすくなります。例えば、100個のパーティション全体で200ギガバイトのデータにUDFを適用すると、2ギガバイトのデータが各タスクのRに送られることになります。SparkRからrepartition()関数を使ってパーティション数を200個に増やすと、1ギガバイトが各タスクのRに送られます。パーティションを増やす場合のトレードオフは、JVMとR間でシリアライズやデシリアライズしたタスクが多くなることですが、各タスクのデータと結果的に生じるメモリ負荷は少なくなります。
標準的な14ギガバイトのRAMでは、Sparkのワーカーが空き容量を使って2ギガバイトのデータパーティションを処理できる可能性がありますが、実際にメモリ不足エラーを回避するには最低でも30ギガバイトのRAMが必要です。SparkとRでUDFを使い始めようと試みる多くの開発者にとって、この事実は青天の霹靂で、莫大なコストがかかる可能性があります。なぜ、ワーカーはそれほどまでにメモリを必要とするのでしょうか?
その答えは、メモリでのデータ表現がSparkとRでかなり異なるところにあります。SparkからRへのデータ転送時、コピーが作成され、続いてRが使用可能なインメモリ形式に変換されます。前述したUDFのアーキテクチャ概略図において、オブジェクトは2つのコンテキスト��間を移動するときに必ずシリアライズとデシリアライズを必要としたことを思い出してください。こういった状況では一般的に予想よりはるかに多くのメモリがワーカーに要求されるため、低速になり、しかも膨大なメモリオーバーヘッドが生じます。
Apache Arrowを使用して2つの異なるインメモリ形式を1つにまとめることで、この障害を軽減できます。Apache Arrowは、Parquetに似たカラムナフォーマットを使用してSparkとRのような別々のシステム間でのデータ転送を迅速かつ効率的にするよう設計されています。これにより、シリアライズとデシリアライズにかかる時間を省くと共に、増加したメモリオーバーヘッドも排除します。Apache Arrowの使用の有無でワークロードを比較すると、10~100倍の高速化が認められることがよくあります。UDFで作業する際に、こうした最適化機能のいずれかを使用することが重要であることは言うまでもありません。Spark 3.0にはSparkR でのApache Arrowに合わせたサポートが含まれ、こちらにある指示に従ってDatabricksのRにApache Arrowをインストールできます。Databricks ランタイムのSparkRで利用できる同様の革新的な最適化機能があることも注目に値します。
4. R のプロセス:R の特質を制御する
それぞれの言語には固有の特質があるため、私たちはここで、Rそのものに焦点を当てます。UDF の関数がワーカーに数百または数千回適用される場合があると考えれば、R がどのようにリソースを使用するかを考慮する必要があります。
投球に関するスコアリング関数を最適化する上で、ジョブに起こりうる障害として、モデルオブジェクトのロードと R の copy-on-modify の挙動を誘発するコマンドを特定しました。どうしてそのようなことができたのでしょうか。まずは、モデルオブジェクトのロードから始めて、これら2つについて詳細に確認していきましょう。
Rを使って十分に作業した場合、Rのパッケージの多くがモデルオブジェクトの一部としてトレーニングデータに含まれることに気付くでしょう。データが小さい場合はこれで問題ありませんが、データが大きくなると重大な問題に発展することが考えられます。実際に、投球モデルは 2 GB に近いサイズのモデルがいくつかありました。この場合、これらのモデルが各UDFを動作する際にメモリからロードおよびドロップすることに関連するオーバーヘッドは3,000億から3桁離れた3億行の規模に制限しました。
さらに、以下に示す広範なトレーニング用関数の一部としてモデルが保存されていたことがわかりました。
モデルオブジェクトのメモリへのロードと、copy-on-modifyの挙動の除去を効率的に行った結果、私たちはUDFにおけるRの実行を合理化しました。