機械学習プラットフォームの選択における 3 つの原則

機械学習のプラットフォーム、オペレーション、ガバナンスに関するブログシリーズの第二弾です。Rafi Kurlansik によるこのシリーズの第一弾、「Need for Data-centric ML Platforms」(データセントリックな機械学習プラットフォームの必要性)はこちらからお読みいただけます。
某サイバーセキュリティ企業でデータプラットフォーム部門のシニアディレクターを務めるお客様から、次のようなコメントをいただきました。
「機械学習のツールは目まぐるしく進化している。将来的にも投資を無駄にしない方法はあるのだろうか?」
これは多くの組織に共通する課題です。機械学習(ML)は、他の技術と比較して進化のスピードが速く、ライブラリの多くが開発後間もない段階で共有され、Databricks を含む多くのベンダーがそれぞれツールやプラットフォームを宣伝しています。会話を進めるうちに、このお客様は、データサイエンスや機械学習の取り組みへの投資を無駄にしない方法があることに気づきます。変化し続ける技術をサポートできるプラットフォーム、すなわち Databricks が、この課題の解決策だったのです。
私は、Databricks での経験の中で、多くの組織がデータサイエンスと機械学習チームを長期的にサポートする��ために、データプラットフォームを構築する現場を見てきました。これらの組織が直面する初期の課題は、いくつかの分野に分類できます。データプラットフォームと機械学習ツールの分断、エンジニアリングとデータサイエンス・機械学習のチーム間のコミュニケーションおよびコラボレーション不足、過去の技術選択による変革と成長の阻害などです。これらの組織では、新たなテクノロジーを選択することで、データサイエンスと機械学習プラットフォームの改善に成功しています。その際に組織が指針とした私の提言の概要を 3 つの原則にまとめ、よくある失敗とそのソリューションをこのブログ記事でご紹介します。
原則 1:機械学習のためのデータアクセスをシンプルにする
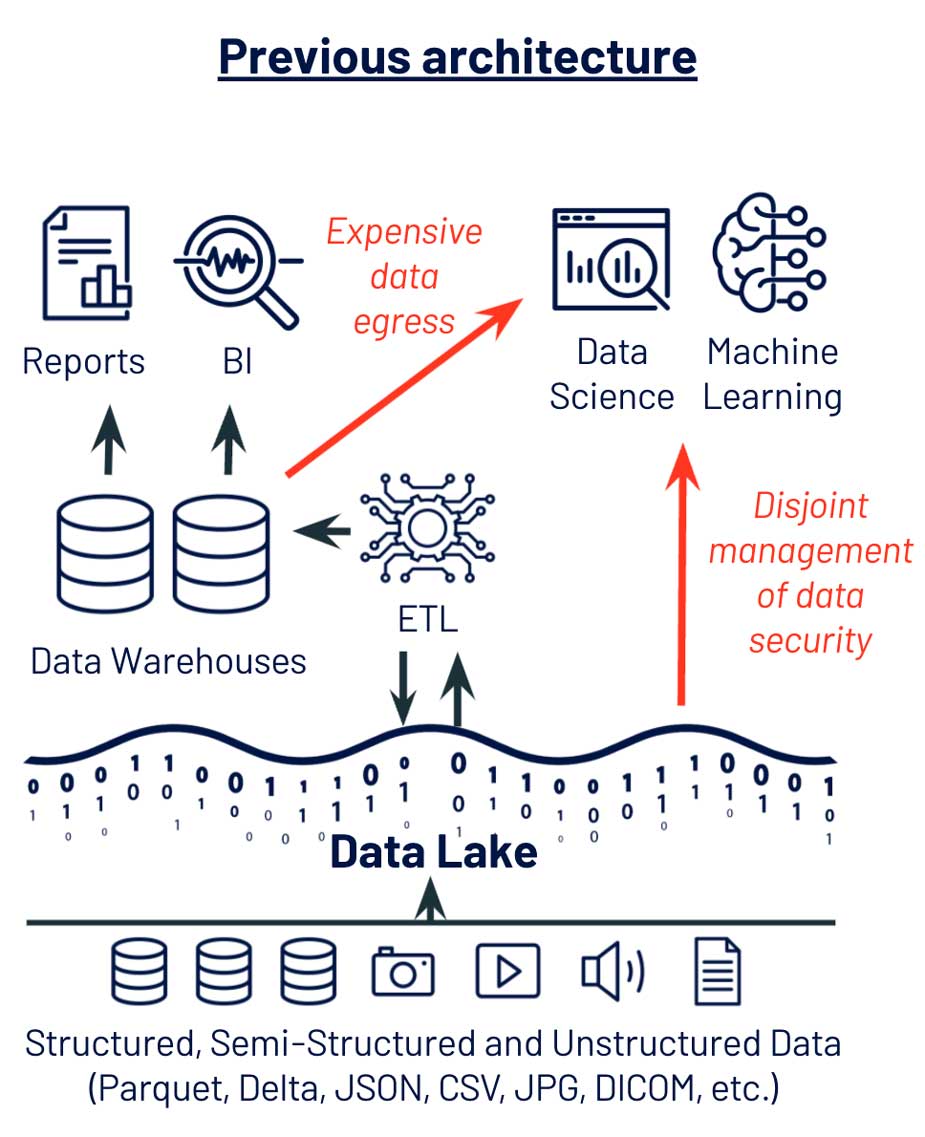
データサイエンスと機械学習では、データへの容易なアクセスが必要です。一般的な障壁として、独自のデータフォーマット、データ帯域幅の制限、ガバナンスの不整合などが挙げられます。
私が担当した、あるお客様の企業では、まさにこの課題に直面していました。この企業では、データエンジニアリングによってメンテナンスされたクリーンなデータを持つデータウェアハウスを保有していました。データサイエンティストはビジネスユニットと連携し、XGBoost や TensorFlow といった最新のツールを利用していました。しかし、データウェアハウスからデータサイエンスと機械学習のツールへのデータの取り込みが困難で、多くのプロジェクトに遅延が発生していました。さらに、データサイエンティストは、データを PC にコピーしなくてはならず、プラットフォームのインフラのチームは、セキュリティ�リスクが生じることを懸念していました。この企業のデータウェアハウスを中心に据えた機械学習へのアプローチの問題を解決すべく、私たちは課題を 3 つに分割しました。
Python と R のためのオープンデータフォーマット
この企業での最初の問題は、独自のデータストアを使用していたことでした。データウェアハウスは独自のフォーマットを使用するため、データサイエンスや機械学習のためのデータ抽出には、高コストのデータ出力プロセスを必要とします。一方で、データサイエンスと機械学習のツールは SQL ではなく、Python や R をベースにしているのが一般的で、ディスク上の Parquet、JSON、CSV、メモリー上の Pandas、Spark データフレームなどを前提としています。 この課題は、画像や音声などの非構造化データの場合はさらに大きくなります。非構造化データは、データウェアハウスには格納できず、処理には専用のライブラリが必要だからです。
この企業では、データレイクストレージ(Azure ADLS、AWS S3、GCP GC)を中心にデータ管理を再構築することで、データエンジニアリングおよび、データサイエンスと機械学習のデータ管理を一元化し、データサイエンティストによる容易なデータへのアクセスを可能にしました。現在では、データサイエンティストは、Python や R を使用して、プライマリストレージからデータフレームにデータを直接ロードし、モデルのデプロイや反復を迅速に実行できます。また、画像や音声などの特殊なフォーマットも扱えるようになり、機械学習を活用した新たな製品の方向性を打ち出しています。
データの帯域幅と規模
データ��サイエンスと機械学習向けのフォーマットの他にも、データの帯域幅と規模に関する課題にも直面していました。データウェアハウスのデータを機械学習アルゴリズムに供給することは、小さなデータでは可能です。しかし、アプリケーションログや、画像、テキスト、IoT テレメトリなどのモダンなデータソースは、すぐにデータウェアハウスの容量を超えてしまい、データ保管のコスト増大、データサイエンスと機械学習アルゴリズムのためのデータ抽出の低速化を引き起こしていました。
この課題は、データレイクのストレージをプライマリデータレイヤーとすることで解決しました。この企業では、データの格納と移動に伴うコストを削減しながら、扱えるデータセットのサイズを 10 倍に増大できました。履歴データが増えたことで、モデルの精度が高まり、特に、レアな外れ値にも対応できるようになりました。
データセキュリティとガバナンスの統合
データ管理システムが原因で直面していた課題の中でも、最も複雑かつリスクが高かったのは、セキュリティとガバナンスでした。データアクセスを管理するチームは、テーブルベースのアクセスに精通しているデータベース管理者でした。しかし、データサイエンティストは、最新の機械学習ツールにデータを取り込むために、管理されているテーブルからデータセットをエクスポートする必要がありました。そのため、データサイエンティストが新たなデータソースへアクセスしたくても、この分断によるセキュリティ上の懸念や曖昧さが原因で、数か月単位の遅延が発生していました。
これらの課題を解決�すべく、この企業では、データエンジニアやデータベース管理者と同じガバナンスモデルを使用して、データサイエンスと機械学習のツールがデータにアクセスできる統合プラットフォームを選択しました。これにより、サイエンティストは、膨大なデータセットを Pandas や PySpark のデータフレームに容易に取り込めるようになり、データベース管理者は、データアクセスをユーザー ID 単位で制御し、データの漏洩防止ができるようになりました。
データアクセスの簡素化に成功
この企業では、データサイエンスと機械学習のデータアクセスをシンプルにするために、 2 つの主要なテクノロジーの変更を実行しました。(1) データレイクストレージをプライマリデータストアとし、(2) データレイクストレージを利用して、テーブルとファイルに同じガバナンスモデルを実装したことです。これらの選択は、レイクハウスアーキテクチャの採用につながりました。Delta Lake により、データエンジニアリングにデータパイプラインの信頼性がもたらされ、データサイエンスには、機械学習に必要なオープンフォーマット、データ管理者には、セキュリティに必要なガバナンスモデルが提供されました。この近代化されたデータアーキテクチャによって、データサイエンティストは、これまでと比べて半分以下の時間で、新たなユースケースの価値を創出できるようになっています。
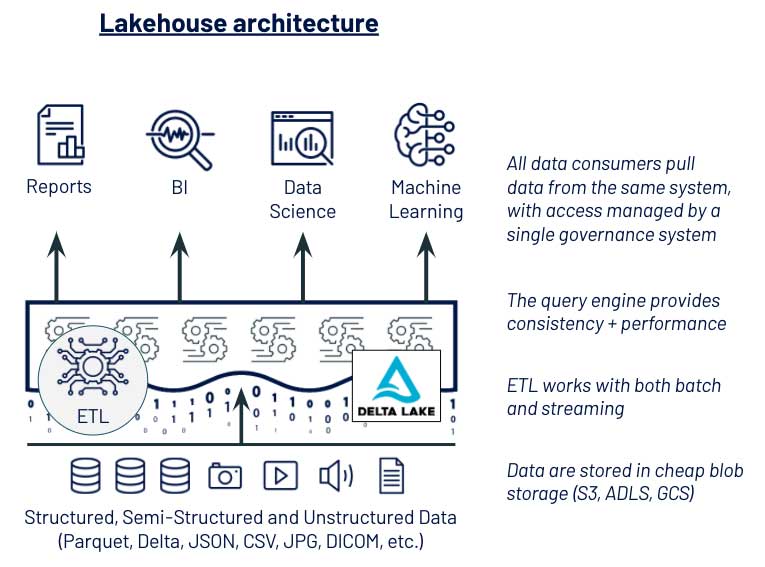
データアクセスの簡素化に成功したお客様導入事例をいくつかご紹介します。
- アウトリーチ社:機械学習エンジニアは、データにアクセスするためのパイプライン構築に時間を費やしていましたが、ETL と機械学習の両方をサポートするマネージドプラットフォームへ移行し、この問題を解決しました。
- エドモンズ社:データのサイロ化がデータサイエンティストの生産性の妨げていることが課題でしたが、Databricks を導入してデータドリブンな組織を実現しました。同社でエグゼクティブディレクターを務めるグレッグ・ロキタ氏は次のように述べています。「Databricks の導入により、デ��ータそのもの、データエンジニアリング、機械学習の民主化が実現し、組織内にデータ主導の原則を浸透させました。」
- シェル社:Databricks の導入により、データへのアクセスが民主化され、全ての部品や設備の在庫シミュレーションや、150 万人以上のお客様への推薦など、より大きなデータに対する高度な分析が可能になりました。
原則 2:データエンジニアリングとデータサイエンス間のコラボレーションを促進する
データプラットフォームは、データへのアクセスだけでなく、データエンジニアリングと、データサイエンスおよび機械学習チーム間のコラボレーションをシンプルにするものであるべきです。よくある障壁の原因は、この 2 つのグループが、それぞれ異なるプラットフォームを使用して、コンピューティングやデプロイ、データ処理、ガバナンスを実行していることです。
ここで、別のお客様の例を紹介します。このお客様の企業には、優秀なデータサイエンスチームがありましたが、データエンジニアリングチームとの連携がうまく取れていませんでした。データサイエンスチームでは、データサイエンス中心の任意のプラットフォームを使用し、Notebook やオンデマンドのクラウドワークステーション、機械学習ライブラリをサポートしていました。データサイエンスチームは、新たな価値あるモデルを構築し、そのモデルを、データエンジニアリングが Apache Spark ベースのプロダクションシステムに接続してバッチ推論を行うプロセスを確立していました。しかし、このプロセスは苦痛を伴うものでした。データサイエンスチームは、ワークステーションから Python や R を使用することに慣れていましたが、データエンジニアリングが使用する Java 環境やクラスタコンピューティングには不慣れでした。このギャップにより、Python と R のモデルを Java で書き換え、同一の動作であることを確認し、特徴量生成ロジックを書き直し、スプレッドシートに記録されたモデルのファイルを手作業で共有するという、煩雑なハンドオフのプロセスが発生しました。このようなやり方は、数か月の遅延、プロダクションエラーの発生を引き起こし、管理者も監視することができませんでした。
チーム間をまたぐ環境管理
この企業の最初の課題は、環境管理でした。機械学習モデルは分離したオブジェクトではなく、動向は環境に依存します。また、ライブラリのバージョンによって、モデルの予測値は変化するものです。この企業のチームでは、データエンジニアリングの本番環境に無理に合わせて、機械学習の開発環境を再現していました。最新の機械学習の世界には、Python (時には R)が必要です。彼らには、virtualenv や conda、Docker コンテナのような環境を再現するツールが必要でした。
この要件を考慮した結果、この企業では、MLflow を選択しました。MLflow は、内部でこれらのツールを使用しますが、複雑な環境管理をデータサイエンティストが行う必要はありません。MLflow を使用することで、データサイエンティストは、実運用までの時間を 1 か月以上短縮し、最新の機械学習ライブラリへの更新に悩むこともなくなりました。
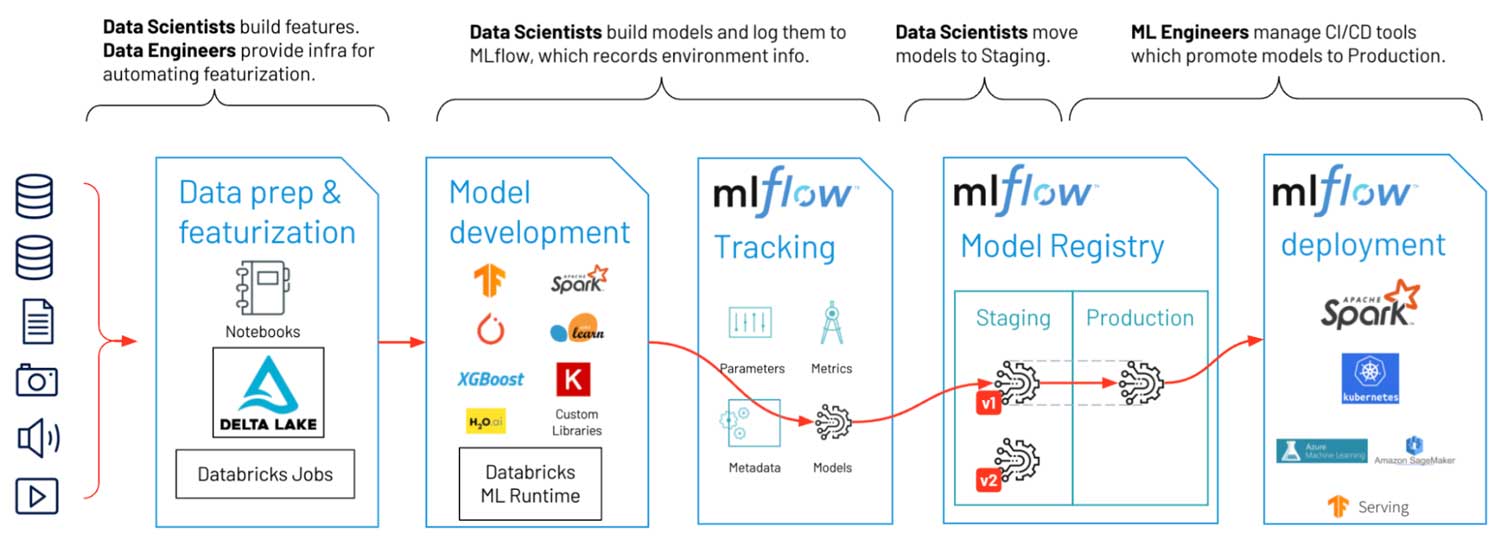
特徴量生成のためのデータ準備
データサイエンスおよび機械学習にとって、高品質のデータが全てです。そして、 ETL/ELT (多くは、データエンジニアの範囲)と、特徴量生成(多くは、データサイエンティストの範囲)の境界線は曖昧です。この企業では、データサイエンティストが、新たな特徴量、もしくは特徴量の改善を必要とした場合、データエンジニアにパイプラインの更新を依頼していました。この待ち時間の間に、ビジネスの優先順位が変更になり、作業が無駄になることもありました。
この企業は、新たなプラットフォームの選択基準に、データ処理ロジックのハンドオフをサポートするツールを優先しました。最終的に、ハンドオフのポイントとして Databricks のジョブを選択し、データサイエンティストは、Python や R のコードをユニット(ジョブ)にまとめ、データエンジニアは、既存のオーケストレーター(Apache AirFlow)と、CI/CD システム(Jenkins)使用して、それをデプロイできるようになりました。その結果、特徴量生成ロジックを更新する新たなプロセスは、ほぼ完全に自動化されまし��た。
機械学習モデルの共有
機械学習モデルは、膨大な量のデータと、ビジネス目標を簡潔なビジネスロジックにまとめたものです。このお客様と仕事をする過程で、私は、このような貴重なアセットが、ガバナンスなしで保管、共有されていることに、皮肉と恐ろしさを感じました。オペレーションの観点では、ガバナンスの欠如が原因で、ファイルやスプレッドシートなど、手間のかかるプロセスが発生し、チームリーダーやディレクターの見落としも引き起こしていました。
マネージド MLflow サービスへの移行は、このお客様にとって、革新的でした。このサービスによって、単一のモデルレジストリによるセキュアなアクセス制御の下で、機械学習モデルを共有し、本番環境に移行する仕組みが提供されました。ソフトウェアは、これまでの手作業のプロセスを自動化し、マネージメントは、モデルを本番環境に移行する過程を監視できます。
コラボレーション促進の成功
This customer’s key technology choices for facilitating collaboration were around a unified platform that supports both data engineering and data science needs with shared governance and security models. With Databricks, some of the key technologies that enabled their use cases were the Databricks Runtime and cluster management for their compute and environment needs, jobs for defining units of work (AWS/Azure/GCP docs), open APIs for orchestration (AWS/Azure/GCP docs) and CI/CD integration (AWS/Azure/GCP docs), and managed MLflow for MLOps and governance.
Databricksの導入により、データエンジニアリングとデータサイエンス間のコラボレーションの改善に成功したお客様における事例をいくつかご紹介します。
- コンデナスト社:パイプラインを管理するチームと、高度な分析を管理するチームの間にある壁を取り除き、価値を創出できるようになりました。AI インフラ部門プリンシパルエンジニアのポール��・フライゼル氏は次のように述べています。「Databricks は極めて強力なエンドツーエンドのソリューションです。メンバーの専門分野や経験に関わらず、全員が大量のデータに容易にアクセスし、実用的な洞察をビジネス上の意思決定に活用することができます。」
- イテラブル社:データエンジニアリングとデータサイエンスの部門の分断が原因で、機械学習モデルのトレーニングやデプロイの反復ができないことが課題でした。部門間をまたがって機械学習ライフサイクルを効率化する共有プラットフォームへ移行したことにより、データチームによる、モデルやプロセスの再現がシンプルになりました。
- Showtime 局:マネージド MLflow ベースのプラットフォーム移行前までは、機械学習の開発とデプロイは手動で行われており、エラー発生の原因になっていました。Databricks の導入により、ワークフローから運用工数を削減でき、新たなモデルや特徴量の実運用化までの時間も短縮しました。
MLOps のビッグブック

原則 3:変化に備える
組織やテクノロジーは変化します。データサイズは成長し、チームのスキルセットや目標は進化します。テクノロジーは経時的に発展し、置き換えられていきます。一般的ではありますが、明らかな戦略上のミスとして、規模に備えたプランを立てないことが挙げられます。また、データや、ロジック、モデルに移植性のないテクノロジーを選択してしまうことも、目立ちはしませんが、よくある間違いです。
最後の原則を説明するために、また別のお客様の事例をご紹介します。コンテンツ分類のために、機械学習モデルを作成しようとしていた初期段階のお客様でした。このお客様は、Databricks を採択しましたが、専門知識も不足していたため、私たちのプロフェッショナルサービスに大きく依存していました。1 年後、このお客様のビジネスに初期の価値の成果を示すことができました。より専門的なデータサイエンティストの雇用を増やし、これまでに比べて、約 50 倍以上のデータを収集できるまでになりました。このお客様に必要だったのは、スケーラビリティ、分散型機械学習ライブラリへの切り替え、データチーム間の緊密な連携でした。
スケーリングに備える
このお客様が実感したように、データ、モデル、組織は時間の経過とともにスケールアップします。このお客様の企業のデータは、もともとデータウェアハウスに収まっていましたが、データサイズや分析のニーズの増大に伴い、別のアーキテクチャへの移行が必要になっていました。データサイエンスおよび機械学習チームは、最初はノートパソコン上で作業できていましたが、1 年後には、より強力なクラスタが必要となりました。このお客様は、レイクハウスアーキテクチャと、シングルマシンと分散型機械学習をサポートするプラットフォームを事前に準備したことで、急成長による対応を円滑に進めることができました。
移植性の必要性と、構築か購入の選択
移植性は、あまり目立たない課題です。企業では、「オープンソース技術を使用して自社でプラットフォームを構築すれば、カスタマイズが可能になり、ロックインを回避できる」もしくは、「既製で専用のツールセットを購入すれば、迅速なセットアップや進捗が得られる」というような、テクノロジー戦略の判断を「構築か購入か」に単純化しがちです。この議論の内容は、カスタムプラットフォームへの膨大な先行投資をするか、専用の技術にロックインされるかであり、どちらもよい選択肢とは言えません。
そもそも、この議論は、データプラットフォームやインフラと、プロジェクトレベルのデータ技術を区別していないので、誤解を招く恐れがあります。データのストレージレイヤーや、オーケストレーションツール、メタデータサービスは、一般的なプラットフォームレベルの技術の選択肢であり、一方、データフォーマット、言語、機械学習ライブラリは、一般的なプロジェクトレベルの技術の選択肢です。変化に備える際には、この 2 つのタイプの選択肢を別々に取り扱う必要があります。データプラットフォームやインフラは、企業の特殊��なデータ、ロジック、モデルのための一般的なコンテナおよびパイプラインとして考えるとよいでしょう。
プロジェクトレベルの技術の変化に備える
プロジェクトレベルの技術は、入れ替えが容易であるべきです。新たなデータや機械学習による製品は、新たなデータソース、機械学習ライブラリ、サービスの統合を必要とする異なる要件を持つ可能性があります。このようなプロジェクトレベルの技術の変化への選択に柔軟性があれば、ビジネスに適応し、競争優位性を持つことができます。
プラットフォームは、この柔軟性を許容するものでなければなりません。理想的には、各チームが、データやモデルに、独自のツールやフォーマットの使用しなくても済むものであるべきです。このお客様の場合、以前は scikit-learn を使用していましたが、既存のプラットフォームや MLOps のツールを変更せずに、Spark ML および分散型 TensorFlow に切り替えることができました。
プラットフォームの変化に備える
移植性を許容するプラットフォームであるべきです。長期にわたり企業に貢献するプラットフォームは、ロックインを回避すべきです。プラットフォーム間のデータ、ロジック、モデルの移行がシンプルで安価である必要があります。データプラットフォームが企業の中核のミッションや強みでない場合、必要に応じてアセットを別の場所に移動できるような機敏な移植性がある限り、迅速性を優先し、プラットフォームを購入することは理にかなっています。
私のお客様の場合、scikit-learn、Spark ML、MLflow などのオープンなツールや、 API を利用できるプラットフォームの選択は、次の 2 点でメリットがありました。決定を変更できるという自信がプラットフォームの選択をシンプルなものにした点と、コードやモデルを別のプラットフォーム間で移動できるようになり、データチームの連携を可能にした点です。
| 変化の種類 | プラットフォームの要件 | プロジェクトレベルの技術の例 |
| スケーリング | ・スモール/ビッグデータの効率的な処理
・シングルノード、分散型コンピューティングの提供 |
・pandas → Apache Spark/Koalas への拡張
・scikit-learn → Spark ML への拡張 ・Keras → Horovod への拡張 |
| 新たなデータタイプ、アプリケーションドメイン | ・任意のデータタイプとオープンデータフォーマットに対応
・バッチとストリーミングの両方のサポート ・他のシステムとの容易な統合 |
・Delta、Parquet、JSON、CSV、TXT、JPG、DICOM、MPEGなどの使用、結合
・Web アプリのバックエンドからデータをストリームする |
| 新たなペルソナ、組織 | ・データサイエンティスト、データエンジニア、ビジネスアナリストのサポート
・スケーラブルなガバナンスとアクセス制御の提供 |
・(a)Notebook の plotly(b)プラグイン可能な BI ツールのダッシュボード、両方での可視化
・(a)カスタムコード(b)AutoML、両方での機械学習の実行 |
| プラットフォームの変更 | ・ユーザーによるデータと機械学習モデルの所有:移行の際の費用はなし
・ユーザーによるコードの所有:git との同期 |
・Keras や Spark ML などのオープンコード API を利用し、プロジェクトレベルのワークロードをプラットフォームから自立させる |
変化の備えに成功
このお客様では、変化に適用するための主要なテクノロジーとして、レイクハウスアーキテクチャ、シングルマシンと分散型機械学習をサポートするプラットフォーム、MLOps のためのライブラリに依存しないフレームワークとして MLflow を選択しています。この選択により、データを 50 倍にスケールし、より複雑な機械学習モデルへの切り替え、チームの大きさとスキルセットの拡大に容易に対応できました。
変化への備えと移植性に関するお客様の成功事例をいくつかご紹介します。
- エドモンズ社:データチームは、最新の機械学習フレームワークなど、データ処理や機械学習の要件をサポートするインフラを必要としていました。また、このインフラを自社で維持するには、膨大な DevOps 工数がかかることが課題でした。この課題の解決に選択した Databricks のマネージドプラットフォームにより、柔軟性が提供され、DevOps 工数の削減も実現しています。
- Quby 社:従来のデータインフラには信頼性、スケーラビリティがなく、数ペタバイトにまで増大したデータ量、100 万以上の機械学習モデルを扱うことが困難でした。この課題の解決に、Delta Lake と MLflow への移行を採択し、スケーラビリティを得ることができました。また、データエンジニアリングとデータサイエンスのチームが必要とするさまざまなツールを Databricks がサポートしていたため、移行も容易でした。
- シェル社:シェル社でのデータチームのスキルと分析プロジェクト(160 件以上の AI プロジェクト)は多岐にわたります。Databricks を Shell.ai プラットフォームの基盤コンポーネントに採用することで、現在および将来のデータ要件に必要な柔軟性を得ています。
原則の適用
大きな原則を並べて、「実行しなさい!」というのは容易です。しかし、実装するには、自社の技術スタック、組織、ビジネスを評価し、計画を立てて実行することが求められます。Databricks は、データサイエンスおよび機械学習を支援するデータプラットフォームの構築における豊富な経験を活かし、お客様を支援します。
私たちが支援し、成功した組織は、いくつかのベストプラクティスを実践しています。これらの組織では、アーキテクチャの長期計画と同時に、成果と価値を短期的に実証すべきであることを認識しています。データサイエンスチームが、ビジネスユニットや優先されるユースケースと連携することで、その価値が経営幹部に伝えられます。組織間の連携は、プロセスの簡素化から、センターオブエクセレンス(CoE)の作成まで、組織の改善に役立ちます。
このブログでは、これらのトピックの表面に触れただけにすぎません。その他の資料として、以下の Web セミナーやイベントの動画、Web ページもご覧ください。
- イベント動画:Data + AI サミット基調講演
完全な機械学習ライフサイクルのための、データネイティブでコラボレーション可能な機械学習ソリューション「Databricks Machine Learning」を発表しています。 - Web セミナー:機械学習プラットフォームの構築
Databricks の CTO 兼共同創業者 マテイ・ザハリア、チーフデータサイエンティスト ベン・ロリカ、データサイエンス・機械学習部門 PM ディレクター クレメンス・メワルドによる Web セミナーの動画を登録して視聴いただけます。 - MLOps バーチャルイベント:大規模な機械学習の運用
Databricks の CTO 兼共同創業者 マテイ・ザハリアと、H&M社、J.B. Hunt Transport 社、Artis Consulting 社からのゲストスピーカーによる Web セミナーの動画を登録して視聴いただけます。 - Databricks の Web ページ:データサイエンス、マネージド ML flow
このシリーズの次の記事では、機械学習の運用について詳しく解説します。デプロイ後のモデルの監視・管理や、Databricks のプラットフォームを活用してモデルのライフサイクルの輪を完成させる方法をご紹介します。