Apache Spark™ 3.2 の概要
Databricks ランタイム 10.0 で利用可能に

公開日: 2021年10月19日
によって Gengliang Wang、Wenchen Fan、Hyukjin Kwon、Xiao Li 、 Reynold Xin(レイノルド・シン) による投稿
Apache Spark™ 3.2 が、Databricks ランタイム 10.0 の一部として Databricks 上で利用できるようになりました。Spark 3.2 のリリースにあたり、Apache Spark コミュニティの皆様の多大な貢献に感謝します。
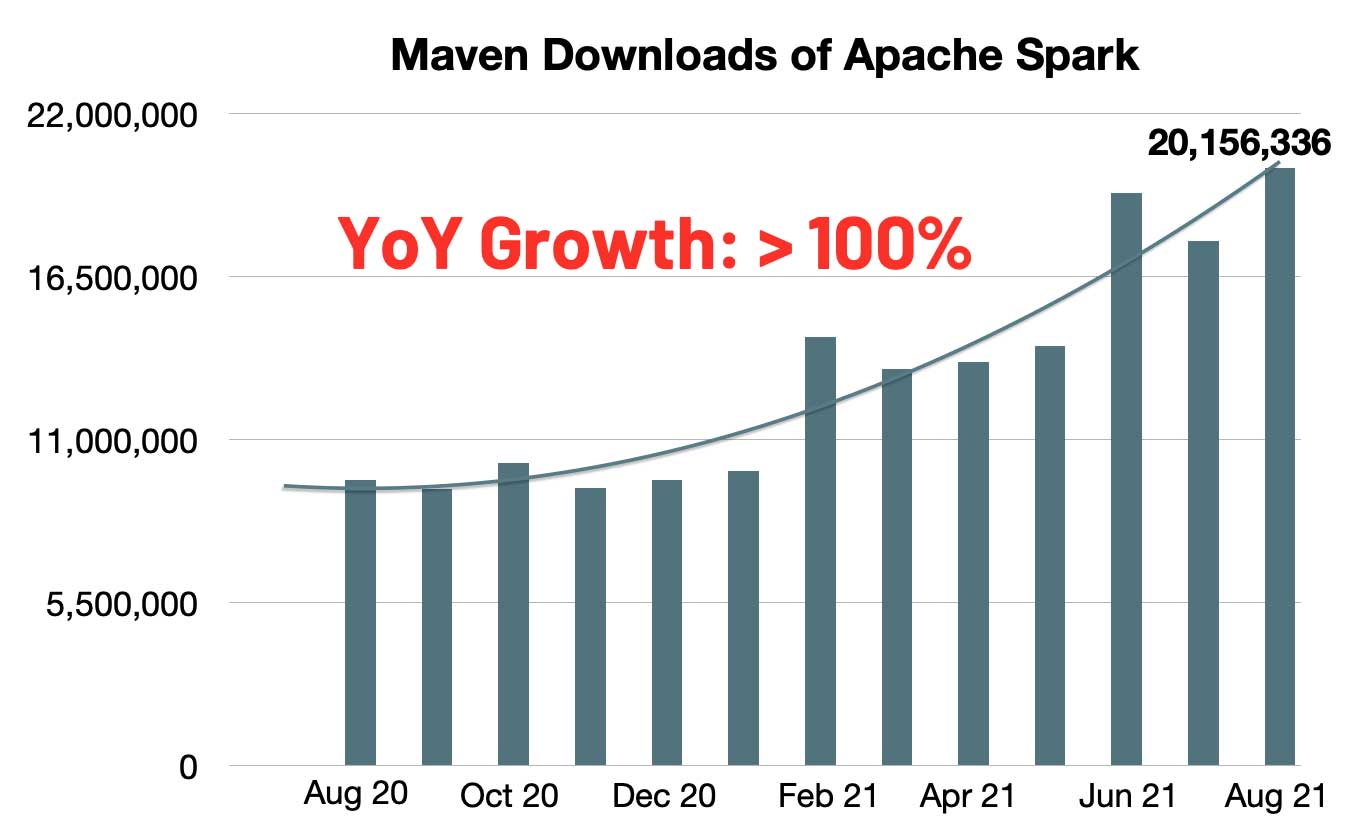
Maven での Spark のダウンロード数が急増しています。月間のダウンロード数は 2,000万に達し、対前年比では 2 倍の成長率を示しています。Spark は、シングルノードマシンあるいはクラスタ上で、データエンジニアリング、データサイエンス、機械学習を実行する際に最も広く活用されているエンジンとなりました。
Spark 3.2 では、Spark をさらに統合し、シンプルで高速、スケーラブルにするという目標を継続し、次の機能でその範囲を拡大しています。
- Apache Spark に pandas API を導入:小規模データAPIとビッグデータ API を統合します。(詳細はこちらのブログでご覧いただけます。)
- ANSI SQL 互換モードの完成:SQL ワークロードの移行をシンプルにします。
- アダプティブクエリエンジンをプロダクションに:Spark SQL の実行性能を高速化します。
- RockDB 状態ストアの導入:状態処理をよりスケーラブルにします。
この記事では、ハイレベルの機能と改善点を要約してご紹介します。機能の詳細は、今後の記事でご紹介する予定です。Spark コンポーネントにおける主要機能の包括的なリストと、解決された JIRA チケットに関しては、 Apache Spark 3.2.0 のリリースノートをご覧ください。
小規模データ API とビッグデータ API の統合
Python は Spark で最も使用されている言語です。Spark をいっそう Pythonic にするために、Project Zen の一環として、pandas API が Spark に導入されました。(Data+AI サミット 2021 でご紹介した Project Zen: Making Data Science Easier in PySpark もご覧ください。)今では、pandas の既存ユーザーは 1 行の変更のみで pandas アプリケーションをスケールさせることができます。以下に示すように、Spark エンジンにおける洗練された最適化により、シングルノードマシン (左のグラフ参照)、マルチノードの Spark クラスタ(右のグラフ参照)の両方で性能が劇的に改善されます。
![Spark エンジンにおける洗練された最適化により、シングルノードマシン [左]、マルチノードの Spark クラスタ [右] の両方で性能が劇的に改善されます。](https://www.databricks.com/jp/wp-content/uploads/2021/10/Introducing-Apache-Spark-3.2-blog-img-3.jpg)
さらに、Python ユーザーは、SQL に対するクエリ、ストリーミング処理、スケーラブルな機械学習(ML)など、Spark によって提供される統合分析機能をシームレスに活用できます。また、新たな pandas API は、plotly バックエンドによって提供されるインタラクティブなデータの可視化機能も提供します。
詳細は、ブログ記事 Apache Spark™ 3.2 における Pandas API のサポートをご覧ください。
SQL の移行をシンプルに
さらなる ANSI SQL 機能(ラテラル結合のサポートなど)が追加されました。1 年以上の開発を経て、このリリースにて ANSI SQL モードが GA となりました。動作を損なうような大規模な変化を避けるために、spark.sql.ansi.enabled モードは、デフォルトでは無効化されたままとなります。ANSI モードには、以下に示すような主要な動作の変更が含まれます。
- SQL オペレーター/関数への入力が不正な際、null の結果でサイレントに無視するのではなく、ランタイムエラーをスロー(SPARK-33275)します。例えば、計算オペレーションにおける integer 値のオーバーフローエラー、文字列から数値/タイムスタンプ型にキャストする際のパーシングエラーです。
- 型強制の文法ルールの標準化(SPARK-34246)。新たなルールは特定のデー��タ型の値がデータ型の優先度リストに基づいて暗黙的に別のデータ型にプロモートできるかどうかを定義しており、デフォルトの非 ANSI モードよりもわかりやすくなっています。
- 新たな明示的なキャスト文法ルール(SPARK-33354)。Spark クエリに不正な型キャスト(例:date/timestamp 型を numeric 型へのキャスト)が含まれる場合、コンパイル時エラーがスローされ、ユーザーに不正な変換が行われていることを通知します。
このリリースには、まだ完了していませんが、新たな取り組みも含まれています。例えば、Spark における例外メッセージの標準化(SPARK-33539)、ANSI のインターバル型の導入(SPARK-27790)、相関サブクエリの改善(SPARK-35553)などが挙げられます。
Spark SQL の実行速度の向上
このリリースで Adaptive Query Execution (AQE) はデフォルトで有効化されます(SPARK-33679)。パフォーマンスを改善するために、AQE は実行時に収集される正確な統計情報に基づき、クエリ実行計画を再度最適化できます。ビッグデータにおいては、統計情報の維持、事前収集のコストは大きいものになります。オプティマイザがどれだけ先進的なものであったとしても、正確な統計情報の欠如は非効率的な計画を作り出すことになります。このリリースでは、join の戦略、skew join とシャッフルパーティションの結合を再度最適化するために、AQE は全ての既存のクエリ最適化技術(例: Dynamic Partition Pruning)との互換性を担保します。
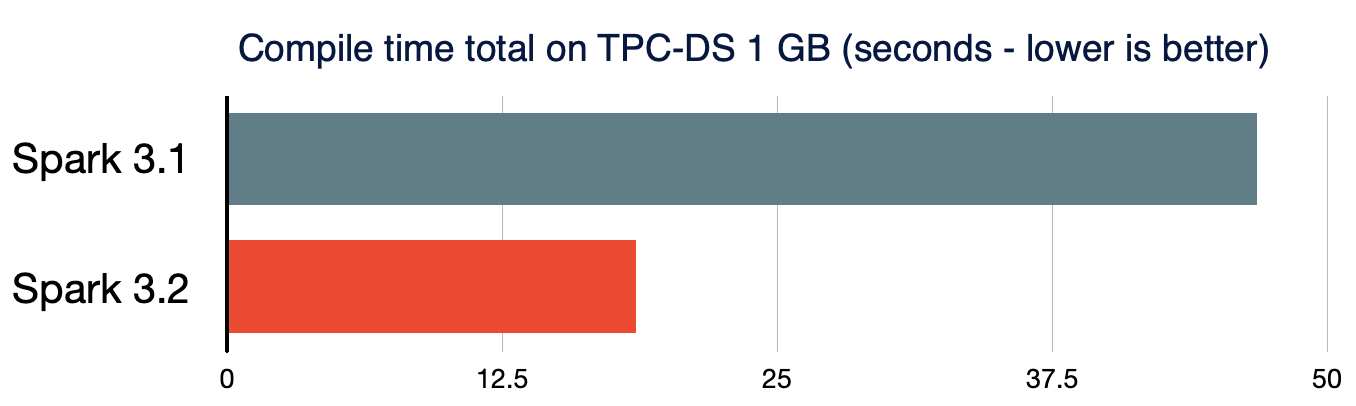
小規模データとビッグデータの両方は、統合されたデータ分析システムにおいて、高度に効率化された方法で処理されるべきです。短時間のクエリのパフォーマンスも重要なものとなります。処理データのサイズが非常に小さい場合、複雑なクエリにおける Spark クエリのコンパイルによるオーバーヘッドは重要となります。クエリのコンパイルのレイテンシをさらに削減するために、Spark 3.2.0 では、アナライザー/オプティマイザールールにおいて、不要なクエリプランのトラバーサルの削除(SPARK-35042、SPARK-35103)、新たなクエリプランの構築を高速化(SPARK-34989)します。��結果として、TPC-DS クエリのコンパイル時間は、Spark3.1.2 と比較して 61% 短縮されました。
ETL を実行する

状態処理ストリーミングをよりスケーラブルに
構造化ストリーミングにおける状態ストアのデフォルト実装では、保持される状態の数がエグゼキューターのヒープサイズによって制限されるためスケーラブルではありません。今回のリリースでは、Databricks は Spark コミュニティに対して、4 年以上にわたって Databricks の製品で使用されている RockDB ベースの状態ストアの実装に貢献しました。この状態ストアは、キーでソートすることでフルスキャンを回避し、エグゼキューターのヒープサイズに依存せずに、ディスクからデータをサーブします。
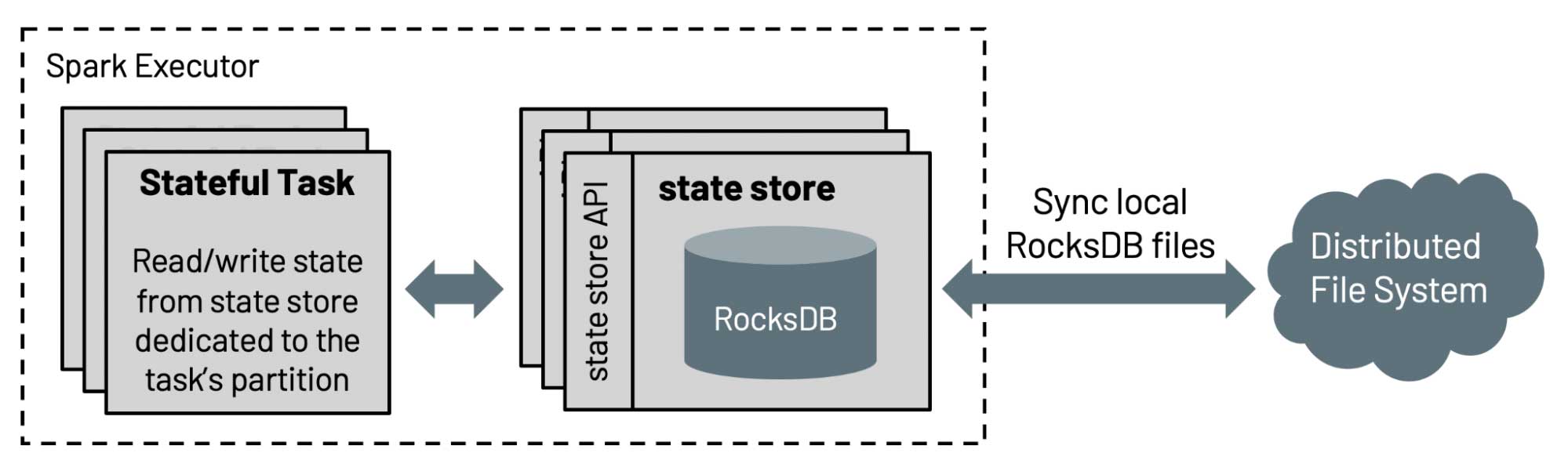
さらに、状態ストア API はプレフィクスマッチスキャン(SPARK-35861)に対する API で拡張され、イベント時間に基づくセッション化(SPARK-10816)を効率的にサポートし、ユーザーは on session windows over eventTime を用いた集計を行えるようになります。詳細は、ブログ記事 Spark 構造化ストリーミングにおけるセッションウィンドウのネイティブサポートをご覧ください。
Spark 3.2 のその他の最新情報
これらの新機能のリリースに加え、このリリースでは、使いやすさ、安定性、洗練性にフォーカスし、約 1,700 件の JIRA チケットを解決しました。これは、個人、そして、Databricks、Apple、Linkedin、Facebook、Microsoft、Intel、Alibaba、Nvidia、Netflix、Adobe などの企業を含む 200 以上のコントリビュータによる貢献によるものです。この記事では、Spark における SQL、Python、ストリーミングデータのキーとなる改善をハイライトしましたが、codegen のカバレッジの改善、コネクターのエンハンスメントなど、3.2 のマイルストーンでは多くの機能が追加されています。詳細はリリースノートをご覧ください。

今すぐ Spark 3.2 を使ってみる
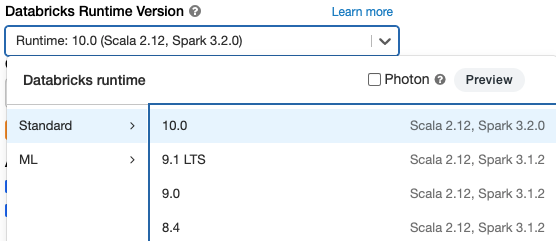
Databricks Runtime 10.0 で Apache Spark 3.2 をお試しいただけます。無料トライアルアカウントを取得してください。すぐに使用を開始できます。クラスタを起動させる際に、バージョン 10.0 を選択するだけで Spark 3.2 が使用できます。