時系列予測ライブラリ Prophet と Spark との連携

1. 時系列予測と Prophet
時系列予測は、周期性や季節性変動がある事象に対して予測を行います。例えば、ある商品の毎月の売り上げを考えると、商品の特性で夏に売り上げが上がり、また、週末や休日前になると多く売れるなど、さまざまな季節性、周期性要因が売り上げに関与してきます。時系列予測では、こうした季節性、周期性要因をうまくモデル化することが求められます。
Prophet は、こうした時系列予測のためのオープンソースライブラリです。Facebook 社の Core Data Science チームが開発・リリースしており、年毎、週毎、日毎の周期性に加え、休日の影響などを考慮して非線形な傾向を持つ時系列データをシンプルにモデル化できるという特長があります。さらに、異常値や欠損データの扱いにも強く、また、人間が理解しやすいパラメタやドメイン知識などを加えることで、モデルの精度を向上させる機能も備えています。
Prophet は、R および Python で利用可能です。今回は、Python を使用した Prophet の使用方法の概要と、Spark との連携により Prophet をスケールさせる利用例について説明します。
2. Prophet の実行例と拡張性
ベースラインモデルの作成
Prophet の第一の特長は、シンプルに使用できる点にあります。Python の機械学習でよく用いられるライブラリである scikit-learn のモデル化の手順と同等になるような関数設計になっており、fit() でモデルを作成し、predict() で予測(スコアリング)する仕様になっています。
モデル作成において、入力として使用する学習データとしては単純に以下の 2 つのカラムを持つ DataFrame を用意します
- ds:日時もしくはタイムスタンプ
- y:予測を実施する数値(例:商品の売り上げ数)
ここでは、Prophet の git リポジトリに含まれるサンプルデータを使って実際のコードを見ていきます。
注意:下記の例では、既に Prophet および Pandas ライブラリが使用できるローカル環境を前提としています。Databricks 上での実行に関しては、後述します。
このデータを使って、Prophet の実行例を見ていきます。
上記のとおり、読み込んだデータは、ds カラムに日時、y カラムにターゲットとなる数値で構成されています。このデータについて、モデルを作成し、1 年先までを予測する例を見ていきます。
先述のとおり、Prophet は scilit-learn と同等の手順でモデル化ができるようになっています。 そのため、モデルのトレーニングには fit() を使用し、予測には predict() を使用します。
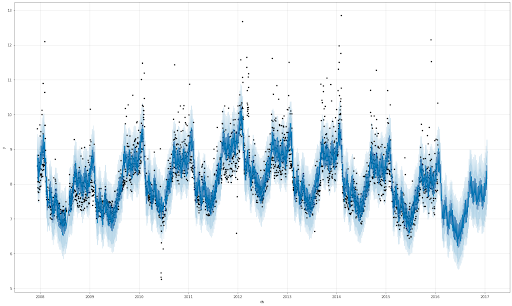
- fig1:青い実線、ライトブルーの領域、黒い点がそれぞれ推定値(yhat)、80% 不確定区間(yhat_upper, yhat_lower)、実値(トレーニングデータ)を表しています。2016年1月20日以降、1 年間の部分が予測期間になっています。
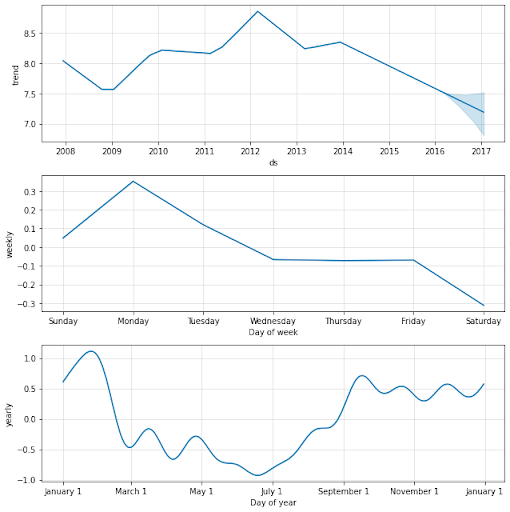
- fig2:予測した結果の要素(トレンド項、weekly�/yearly の季節性要素)を示しています。
上記のコードのみで時系列のモデル作成および、予測が実現可能です。もちろん、デフォルトのパラメタでモデル化を実施しているため、精度を高めるにはパラメタチューニングが必要になりますが、ベースラインとしては非常にシンプルなコードのみで時系列予測ができることがわかります
モデルのカスタム化
休日の設定
それでは、ここからモデル作成時に利用できる拡張性を見ていきます。
まず、一般的な季節性要因として考えられる大きな要素として「休日」が挙げられます。例えば、食品関係の売り上げ予測であれば、年間の季節性に加えて、休日が売り上げが上がる/下がるなどの大きな要因になるのは容易に想像できます。Prophet では、この「休日」を考慮に入れたモデルを容易に作成できます。
まずは、休日を表す DataFrame(holidays)を作成します。DataFrame の要素として、holiday カラムに休日の名前(この例でいえば jp_holiday)、ds カラムに休日の日時で構成します。注意点として、学習データ機関に加えて、予測する期間の休日も含める必要があります。
休日の DataFrame が構成できたら、Prophet のインスタンスを作成する際にオプションとして指定します。 それ以外は先ほどの実行例と同じコードになります。
季節性の周期指定
モデル化する現象の周期性が確定している、もしくは、明らかな場合は、オプションで指定できます。 例えば、2 週間ごと(14 日周期)に変動を繰り返すような場合は、以下のようなコードになります。
不確定区間(Uncertainty Interval)の変更
Prophet は、時系列予測の際に、確率分布を仮定して最尤推定によりモデルを学習していきます。そのため、予測結果に関しても、1 つの値が出力されるのではなく、確率分布の中央値(最大の確率をとる値 yhat)に加えて、確率=80% の区間(不確定区間、yhat_upper、yhat_lower)が出力されます。この不確定区間はオプションで変更可能です。例えば、不確定区間を 95% にするためのコードは以下のようになります。
その他のパラメタ、拡張可能な項目
Prophet は上記以外の要素に関して、例えば以下の項目についてチューニング可能になっています。
- 収束上限値がわかっている場合のモデル
- トレンドの変化点への追従感度
- 不確定区間のサンプリング方法
- 他の要素に依存する季節性の対応
- 異常値の対応
- 1 日より細かい粒度の時系列データの予測
- Cross Validation によるハイパーパラメタチューニング
詳細は、公式ドキュメントを参照してください。
3. Databricks 上での Prophet の利用と Spark との連携
インストール
Databricks のデフォルトのランタイ��ムには Prophet は含まれていません。そのため、Databricks 上で Prophet を利用するには、別途インストールが必要です。Databricks 上でのライブラリの導入には以下の 3 通りの方式があります。
- ワークスペース範囲のライブラリ:ワークスペース内で共有可能なライブラリのリポジトリ環境。オプションで全てのクラスタにライブラリを適用することが可能。Workspace ディレクトリ上からライブラリの設定が可能。
- クラスタ範囲のライブラリ:クラスタ毎にライブラリ環境が分離。Cluster 管理画面から Libraries メニューでライブラリを追加可能。
- Notebook 範囲のライブラリ: Notebook 毎にライブラリ環境が分離。Notebook 上で %pip コマンドなどでライブラリを追加可能。
ここでは Notebook 範囲で Prophet をインストールするには以下のコマンドを Notebook 上で実行します(その他の方式でもほぼ同様にインストールできます)。
これで、この Notebook 上で Prophet が利用できるようになります。上述のコードもそのまま動作します。
(注: Databricks Runtime for ML: 9.1 LTS以降はProphetは標準でインストールされていますので、上記のpip installは不要になります)
Spark との連携
Databricks の��最大のメリットは Spark を利用したクラスタ上での分散並列実行になります。一方で、上記の例では、単に 1 つの時系列データのモデル化・推定を実施している最もシンプルな場合のコードになり、Spark との連携はなく、シングルコンピュートでの実行になります。それではどのように Prophet と Spark が連携できるのか、またどういった場面でそのメリットを享受できるのでしょうか。
例えば、ある商品の売り上げを予想するモデルを作成する場面を考えてみましょう。 商品の売り上げは、次のようなさまざまな要素に依存して変化することは容易に想像できます。
- 商品の売られている場所、販売チャネル、店舗の立地
- 商品のバリエーション、サイズ
そのため、高精度に予測するには、それぞれの場合に分けて予測モデルを作成する必要が出てきます。そして、この場合の数は上記の要素の掛け算になるため、非常に多くのモデル学習が必要になります。通常のシングルコンピュート環境では、モデル学習・推定が現実的な時間内で不可能な状況が往々にして発生します。
こうした状況では、Prophet を Spark と連携させることで問題を解消できます。具体的には、過去の売り上げデータを Spark の DataFrame にロードし、Prophet のモデル学習・推定をユーザー定義関数(UDF)化することで、Spark による Prophet の学習・予測の並列分散化が可能になります。実際のコードなどについての詳細は、以下の記事および、それに含まれる Notebook を参照してください。
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


ニュース
December 24, 2024/2分で読めます