Databricks SQL AI Functionsで大規模に顧客レビューに対して行動する
AIファンクションがLLMなどの力をDB SQLにもたらす

Original : Actioning Customer Reviews at Scale with Databricks SQL AI Functions
翻訳: junichi.maruyama
スーザンは毎朝、メッセージの嵐にさらされ、何から手をつけたらいいのかわからない!スーザンは、世界的な小売企業のカスタマーサクセススペシャリストです。彼女の主な目的は、顧客が問題に遭遇したときに、必ず満足し、個人的なサービスを受けられるようにすることです。
一晩で、ウェブサイト、アプリ、ソーシャルメディアへの投稿、電子メールなど、複数のチャネルで何百ものレビューやフィードバックが寄せられるようになりました。スーザンの1日の始まりは、これらのシステムにそれぞれログインし、同僚がまだ収集していないメッセージを拾い上げることから始まります。次に、これらのメッセージの意味を理解し、対応する必要があるものを特定し、お客さまへの回答を作成する必要があります。なぜなら、メッセージの形式はさまざまで、お客さまはそれぞれ独自のスタイルで意見を述べられるからです。
以下は、彼女が抱えている問題の一例です(この記事のために、Amazonのカスタマーレビューdatasetから抜粋して利用しています)

スーザンは、自分が常に一貫した方法でメッセージを解釈し、分類し、対応しているわけではないことを知り、不安を感じています。スーザンが最も恐れているのは、メッセージを適切に解釈しなかったために、うっかりお客様への対応を逃してしまうことです。スーザンだけではありません。彼女の同僚の多くがこのように感じています!
小売企業にとっての課題は、このような自由形式のフィードバックをどのように集約し、分析し、タイムリーに対応するかということです。最初の一歩は、レイクハウスを活用して、あらゆるシステムのすべてのメッセージをシームレスに1つの場所に集約することでしょう。しかし何をすればよいでしょう?
LLMsを導入
このようなシナリオには、大規模言語モデル(LLM)が最適です。その名の通り、複雑な非構造化テキストを理解する能力が非常に高いのです。また、議論された主要なトピックを要約し、感情を判断し、さらに応答を生成することにも長けています。しかし、すべての組織が独自のLLMモデルを開発し、維持するためのリソースや専門知識を持っているわけではありません。
幸いなことに、今日の世界では、Azure OpenAIのGPTモデルのような、サービスとして活用できるLLMがあります。問題は、これらのモデルをLakehouse内のデータにどのように適用するかということです。
このウォークスルーでは、Databricks Lakehouseにある非構造化データにAzure OpenAIのGPTモデルを適用して、構造化されたクエリ可能なデータに仕上げる方法を紹介します。カスタマーレビューを取り上げ、議論されたトピックとその感情を特定し、カスタマーサクセスチームからの応答が必要なフィードバックかどうかを判断します。さらに、カスタマーサクセスチームのためのメッセージも事前に生成しておきます!
スーザンの会社にとって解決すべき問題は以下の通りです:
- 企業のサポートやガバナンスも受けられるLLMの活用
- 自由形式のフィードバックに対して、一貫した意味を生成する
- 次のアクションが必要かを判断する
- 最も重要なことは、アナリストが使い慣れたSQLスキルを使ってLLMと対話できるようにすることです。
ウォークスルー: Databricks SQL AI Functions
AI Functionsは、非構造化データから意味を導き出すという困難なタスクを簡素化します。このウォークスルーでは、Azure OpenAIモデルのデプロイメントを活用して、自由形式のカスタマーレビューに会話ロジックを適用します。

前提条件
開始にあたり、以下のものが必要です。
- SQL AI Functionsのパブリックプレビューに申し込む
- Azure OpenAI key
- Databricks Secretsにキーを保存する(ドキュメント:AWS, Azure, GCP)
- Databricks SQL ProまたはServerless warehouse
プロンプト設計
生成モデルを最大限に活用するためには、意味のある答えを与えてくれる、整形されたプロンプト(モデルに問いかける質問)が必要です。さらに、その回答をデルタテーブルに簡単に読み込むことができる形式が必要です。幸い、JSONオブジェクトのフォーマットで分析を返すようモデルに指示することができます。
以下は、エンティティの感情を判断し、レビューにフォローアップが必要かどうかを判断するために使用するプロンプトです:
これを単体で実行すると、次のような応答が得られます。
同様に、お客様への返答を生成するために、次のようなプロンプトを使用します。
AI Functions
Azure OpenAIと対話するためのインターフェースとして、Databricks SQL AI Functionsを使用することにします。SQLを利用することで、3つの重要な利点があります:
- 利便性:Azure OpenAIのAPIとインターフェースす�るためのカスタムコードを実装する必要性を見送る。
- エンドユーザー: アナリストは、Databricks SQLと選択したBIツールで作業する際、SQLクエリでこれらの関数を使用できます。
- ノートブック開発者:SQLセルやspark.sql()コマンドでこれらの関数を使用することができます。
まず、プロンプトを処理する関数を作成します。Azure OpenAI API キーを Databricks Secret に格納し、SECRET() 関数でそれを参照します。さらに、Azure OpenAI のリソース名(resourceName)とモデルのデプロイメント名(deploymentName)を渡します。また、モデルの温度を設定する機能もあり、生成される出力のランダム性と創造性のレベルを制御することができます。ランダム性を最小化し、再現性を最大化するために、temperature を明示的に0に設定しています。
ここで、レビューにエンティティ(議論されたトピックなど)、エンティティの感情、フォローアップが必要かどうか、その理由などの注釈を付ける最初の関数を作成します。プロンプトは整形されたJSON表現を返すので、Deltaテーブルに簡単に挿入できるSTRUCTタイプを返すように関数に指示することができます。
クレームに対して、代替品を勧めるなどの対応策を生み出すために、同様の機能を作っています
APIコールとレイテンシーを最小限にするために、上記のロジックをすべて1つのプロンプトにまとめることができます。しかし、組織内の他のシナリオに再利用できるように、質問を細かいSQL関数に分解することをお勧めします。
MLOps のビッグブック

カスタマーレビューデータの分析
では、作った関数を試してみましょう!
LLM関数は構造化されたデータを返すので、これで簡単に問い合わせができるようになりました!
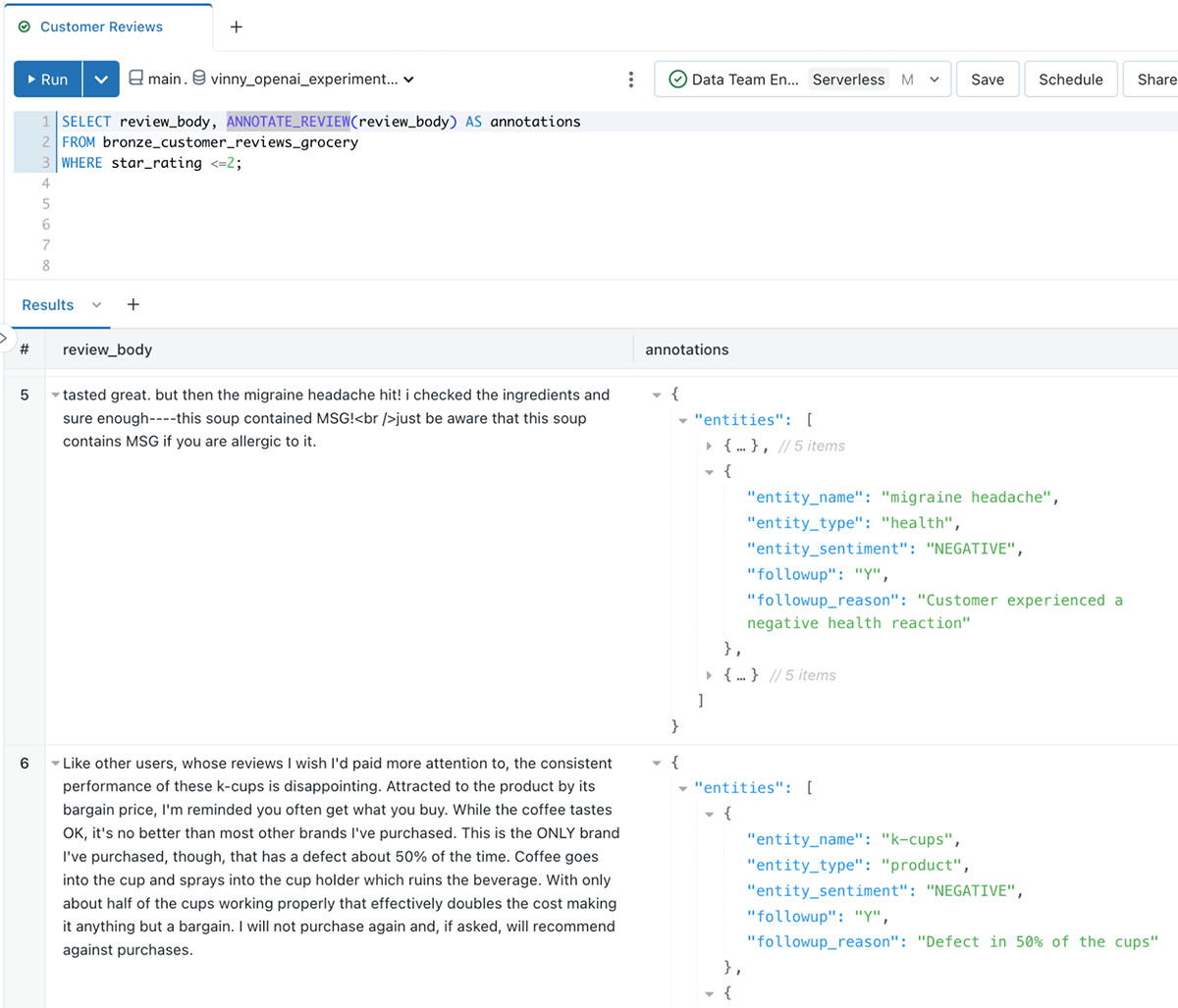
次に、BIツールで照会しやすい形式にデータを構造化します:
これで、レビューごとに複数の行ができ、各行が本文で議論されたエンティティ(トピック)の分析を表すようになりました
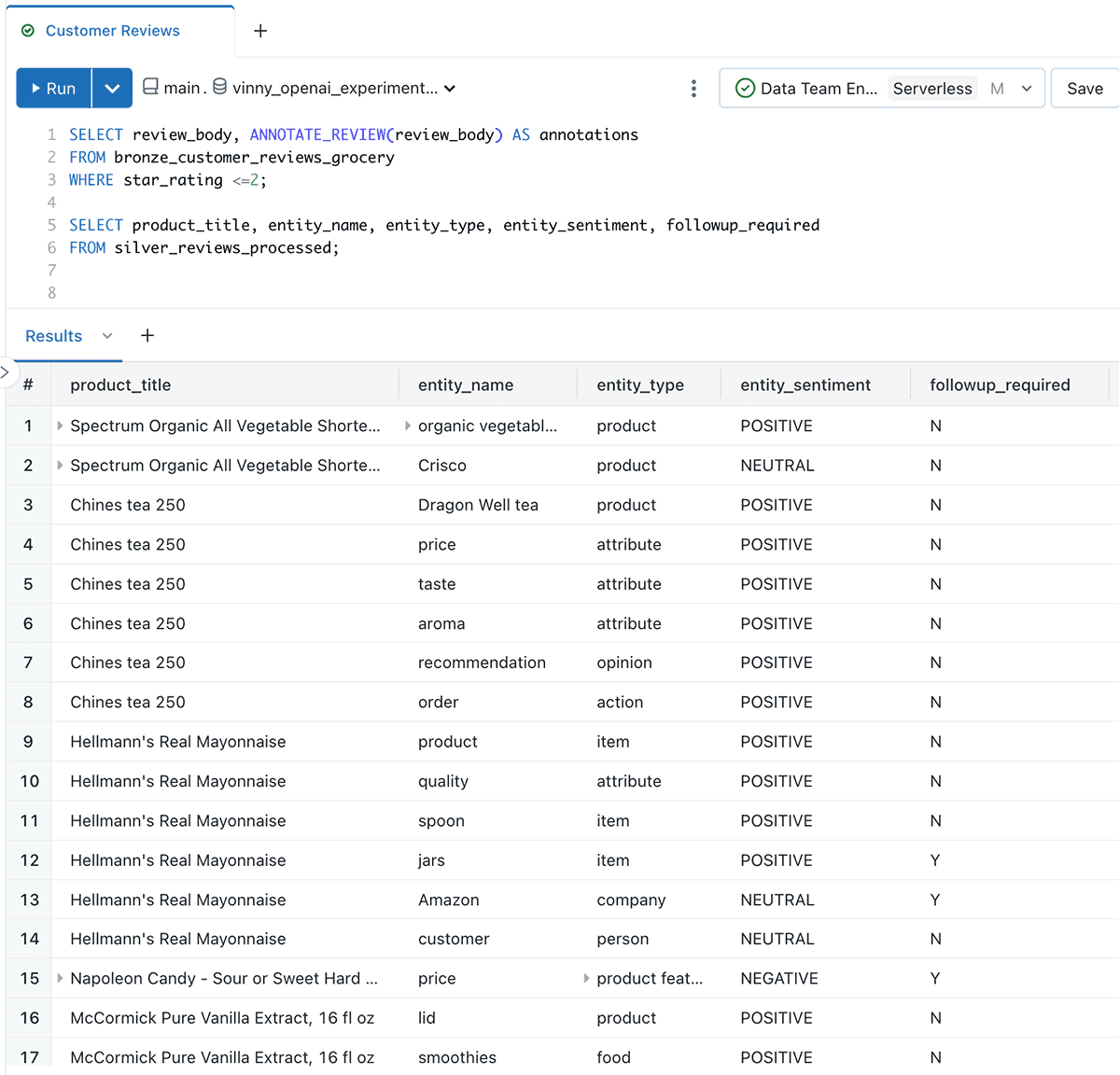
カスタマーサクセスチームへの回答メッセージの作成
カスタマーサクセスチームが、誰が返答を必要としているのか、返答の理由、そしてサンプルメッセージを特定できるようなデータセットを作成しましょう。
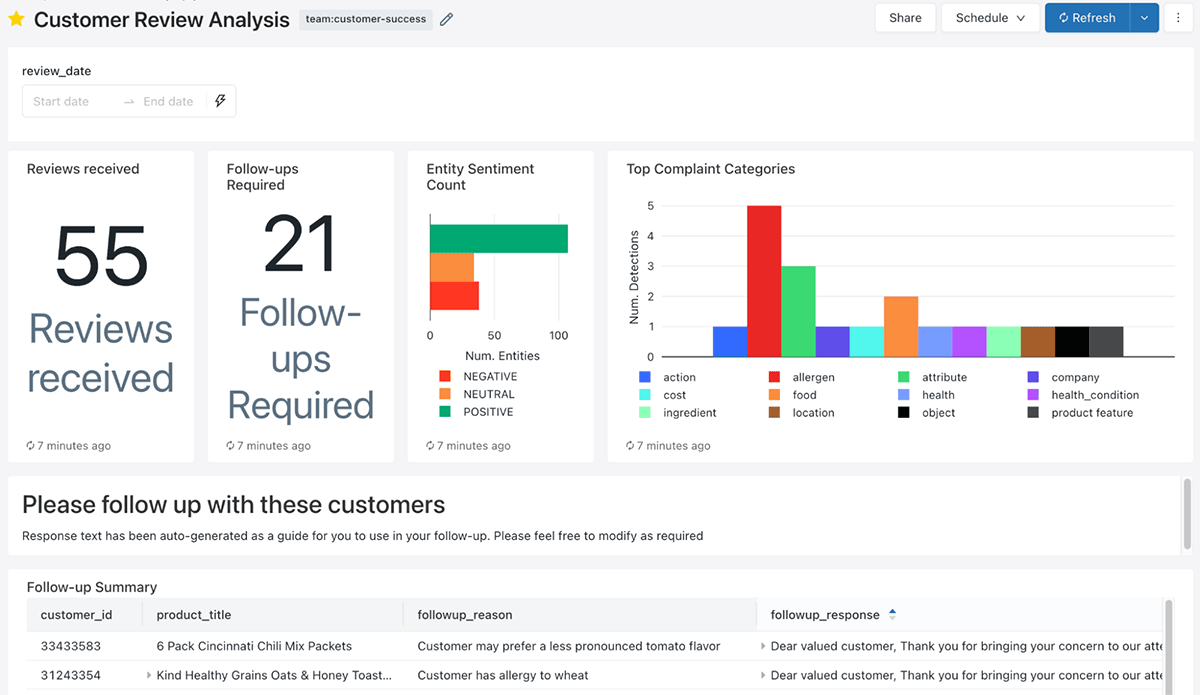
出来上がったデータは次のようになります。
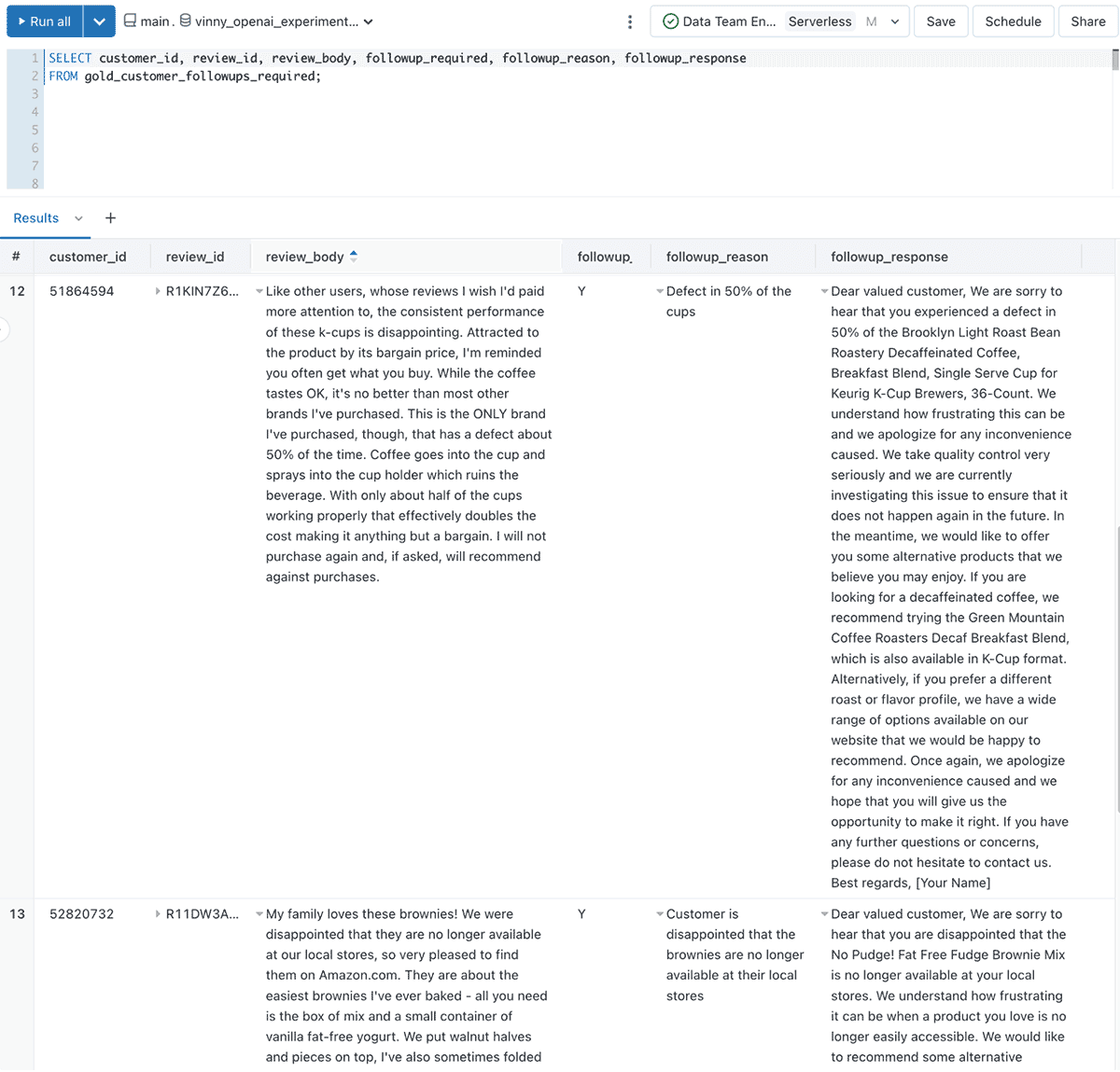
お客様のレビューやフィードバックがLakehouseに流れ込んでくるので、スーザンと彼女のチームは、手作業でそれぞれのフィードバックを評価するという、労力とミスが発生しやすい作業を省くことができました。その代わりに、お客様を喜ばせるという価値の高い仕事に時間を割くことができるようになりました!
アドホッククエリーのサポート
また、PROMPT_HANDLER()関数を使用して、アドホッククエリを作成することもできます。例えば、あるアナリストは、レビューが飲料について議論しているかどうかを理解することに興味があるかもしれません:
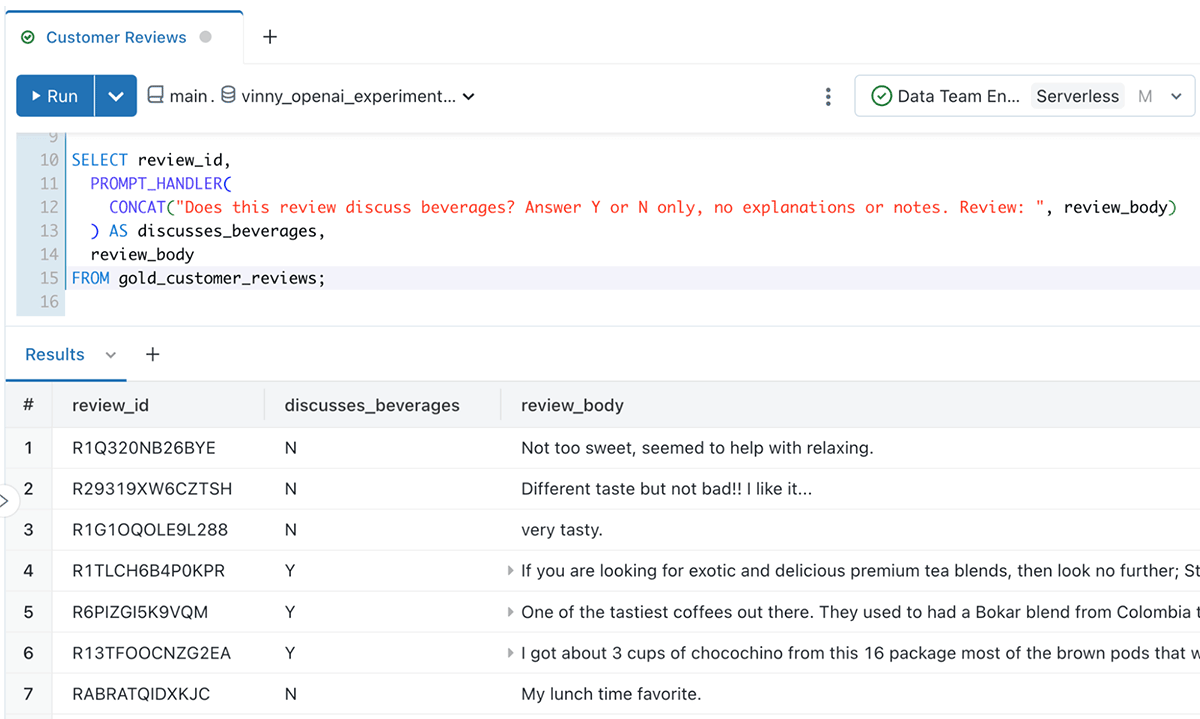
非構造化データから分析済みデータまで、数分で!
朝、スーザンが出社すると、ダッシュボードから、どの顧客とどのような時間を過ごすべきかが表示されるようになりました。さらに、それを基にしたメッセージも用意されています!
スーザンの同僚の多くにとって、これは魔法のように思える!どんなマジックにも秘密があります。ここでの秘密はAI_GENERATE_TEXT()で、LLMをレイクハウスに適用するのがいかに簡単か、ということです。Lakehouseは、複数のデータソースからのレビューを一元化し、データに意味を持たせ、次善の策を推奨するために裏方として働いてきたのだ
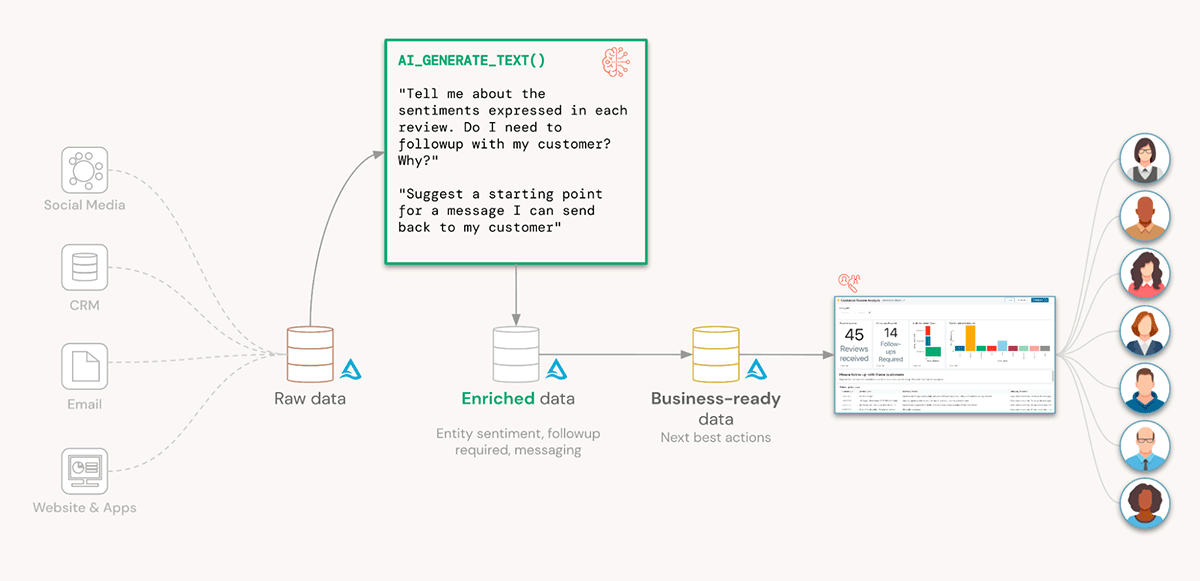
スーザンのビジネスにおける主な利点を再確認してみましょう:
- モデルのトレーニング、構築、運用に数週間を要することなく、すぐにAIをデータに適用することができる。
- アナリストや開発者は、使い慣れたSQLのスキルを使って、このモデルを操作することができます。
など、レイクタウン全体にこれらのSQL関数を適用するこ�とができます:
- Delta Live Tablesでリアルタイムにデータを分類する。
- ブランドに対するネガティブな感情の高まりを警告するリアルタイムSQL Alertsの構築と配信
- Feature Store tablesで製品センチメントを把握し、リアルタイムのサービスモデルを支える
考慮すべき事項
このワークフローは、独自のモデルを訓練し維持する必要なく、データに即座に価値をもたらすものですが、いくつかのことを認識する必要があります:
- LLMから正確な回答を得るための鍵は、よく構成された詳細なプロンプトにあります。例えば、ルールや文言の順番が重要な場合もあります。定期的にプロンプトをファインチューニングしてください。SQLロジックを書くよりも、プロンプトのエンジニアリングに多くの時間を費やすことになるかもしれません!
- LLMの応答は非決定的であることがあります。temperatureを0に設定すれば、レスポンスはより決定論的になりますが、決して保証されるものではありません。そのため、データを再処理する場合、以前に処理したデータの出力が異なる可能性があります。Delta Lakeのtime travelやchange data feedの機能を使って、変化したレスポンスを特定し、それに応じて対処することができます
- Databricksでは、LLMサービスの統合に加え、お客様が所有し、お客様のデータでファインチューニングされたLLMの構築と運用を簡単に行うことができます。例えば、Dollyを構築した方法をご覧ください。これらをAI Functionsと組み合わせて使用することで、お客様のビジネスにとって真にユニークなインサイトを作り出すことができます。
What next?
毎日、コミュニティではプロンプトの新しい創造的な使い方が紹介されています。あなたのDatabricks Lakehouseにあるデータには、どんなクリエイティブな使い方ができるのでしょうか?
- AIファンクション」パブリックプレビューのお申し込みはこちら
- ドキュメントを読むにはこちら
- dbdemos.aiでデモをご覧ください。
- Dollyのような独自のLLMを構築する方法について説明したウェビナーはこちらでご覧ください!