MLflow 2.4を発表:ロバストなモデル評価のためのLLMOpsツール

Original: Announcing MLflow 2.4: LLMOps Tools for Robust Model Evaluation
翻訳: junichi.maruyama
LLMは、あらゆる規模の企業にとって、強力なアプリケーションを迅速に構築し、ビジネ��ス価値を提供する大きな機会を提供します。これまでデータサイエンティストは、非常に限られたタスクを実行するために何千時間もかけてモデルのトレーニングや再トレーニングを行っていましたが、今ではSaaSやオープンソースの幅広いモデル基盤を活用して、より汎用的でインテリジェントなアプリケーションを短時間で提供できるようになりました。データサイエンティストは、プロンプトエンジニアリングのような数ショットやゼロショットの学習技術を使うことで、多様なデータセットに対する高精度の分類器、最先端の感情分析モデル、低レイテンシーの文書要約器などを迅速に構築することができます。
しかし、生産に最適なモデルを特定し、安全に配備するためには、組織は適切なツールとプロセスを用意する必要があります。最も重要なコンポーネントの1つは、堅牢なモデル評価です。幻覚、反応毒性、即時注入に対する脆弱性などのモデル品質の課題、さらに多くのタスクに対するグランドトゥルースラベルの欠如により、データサイエンティストは、多種多様なデータに対するモデルの性能評価に極めて真摯である必要があります。また、データサイエンティストは、複数のモデル候補の微妙な違いを識別して、生産に最適なモデルを選択する能力も必要です。LLMOpsプラットフォームは、すべてのモデルについて詳細なパフォーマンスレポートを提供し、本番のかなり前に弱点や脆弱性を特定し、モデル比較を効率化することができるため、これまで以上に必要です。
このようなニーズに応えるため、モデル評価のための包括的なLLMOpsツール群を提供するMLflow 2.4の登場を発表します。言語タスクのための新しいmlflow.evaluate()統合、複数のモデルバージョン間のテキスト出力を比較するための全く新しいArtifact View UI、そして待望のデータセット追跡機能により、MLflow 2.4はLLMの開発を加速させます。
言語モデルのmlflow.evaluate()で性能に関する洞察を得る
言語モデルの性能を評価するためには、様々な入力データセットを与え、対応する出力を記録し、ドメイン固有のメトリクスを計算する必要があります。MLflow 2.4 では、MLflow の強力な評価 API である mlflow.evaluate()を拡張して、このプロセスを劇的に簡素化しました。1行のコードで、テキスト要約、テキスト分類、質問応答、テキスト生成など、LLMを使用するさまざまなタスクのモデル予測やパフォーマンス・メトリクスを追跡することができます。これらの情報はすべてMLflow Trackingに記録され、複数のモデルの性能評価を検査および比較することで、本番に最適な候補を選択することができます。
次のコード例では、mlflow.evaluate()を使用して、要約モデルのパフォーマンス情報を素早く取得します:
mlflow.evaluate()の詳細については、使用例を含め、MLflow Documentationとexamples repositoryをチェックしてください。
新しいアーティファクトビューでLLMの出力を検査し比較する
グランドトゥルースのラベルがない場合、多くのLLM開発者は、品質を評価するためにモデルの出力を手動で検査する必要があります。これは、文書の要約、複雑な質問�に対する回答、生成された散文など、モデルによって生成されたテキストに目を通すことを意味することが多い。最適なモデルを選択する際には、これらのテキスト出力をグループ化し、モデル間で比較する必要があります。 例えば、LLMを使った文書要約モデルを開発する場合、各モデルが与えられた文書をどのように要約しているかを確認し、違いを特定することが重要です。
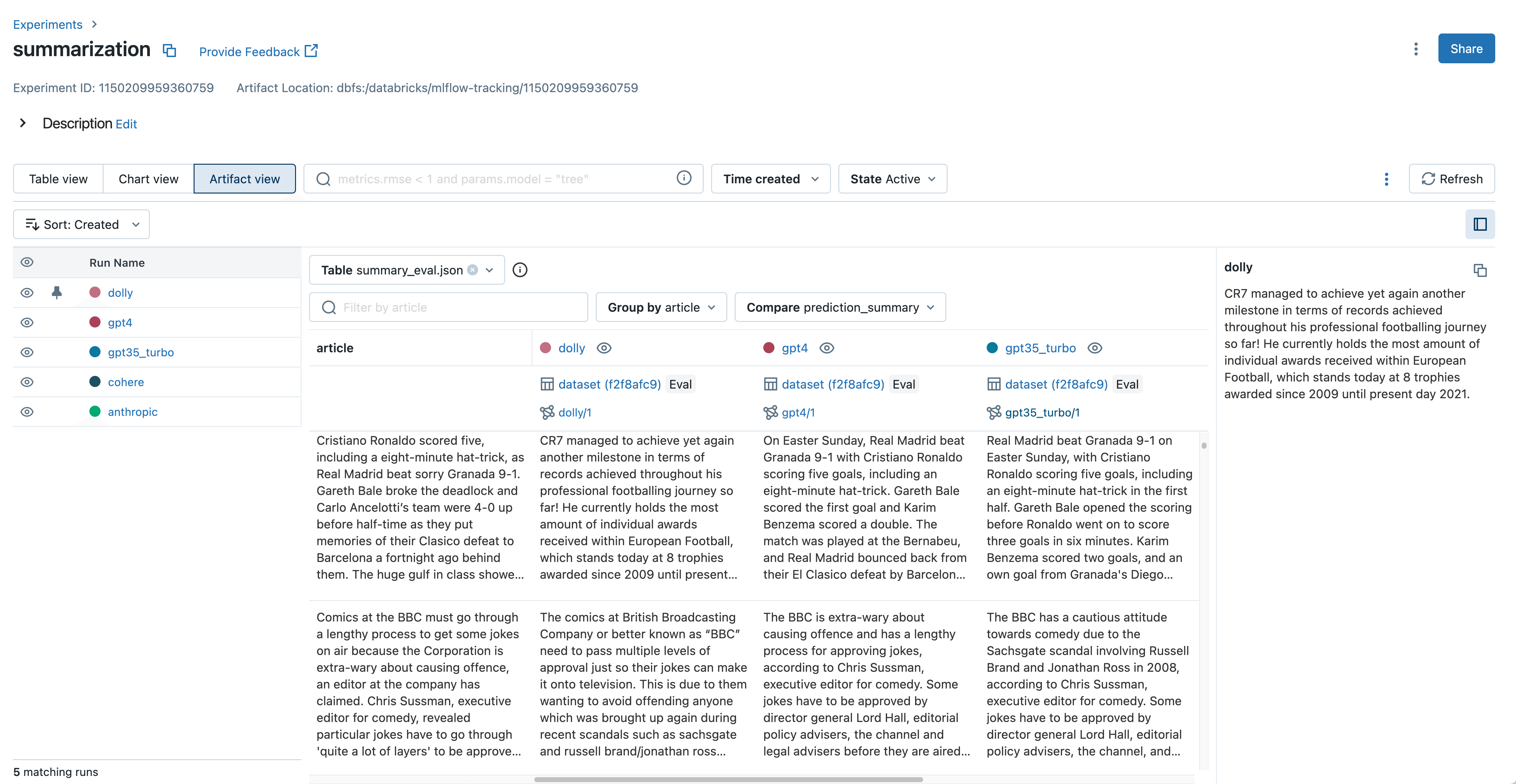
MLflow 2.4 では、MLflow Tracking の新しい Artifact View により、この出力検査と比較が効率化されました。数回クリックするだけで、すべてのモデルにおいて mlflow.evaluate() からのテキスト入力、出力、および中間結果を表示し比較することができます。これは悪い出力を識別し、推論中に使用されたプロンプトを理解することが非常に容易になります。MLflow 2.4 の新しい mlflow.load_table() API を使用すると、Databricks SQL やデータラベリングなどで使用するために、Artifact View に表示された評価結果をすべてダウンロードすることもできます。これは、次のコード例で実証されています:
評価データセットを追跡し、正確な比較を可能にします
生産に最適なモデルを選択するには、さまざまなモデル候補の性能を徹底的に比較する必要があります。この比較で重要なのは、すべてのモデルが同じデータセットで評価されていることを確認することです。結局のところ、報告された精度が最も高いモデルを選択することは、検討されたすべてのモデルが同じデータセットで評価された場合にのみ意味があるのです。
MLflow 2.4 では、MLflow に待望の機能である Dataset Tracking を導入することができました。このエキサイティングな新機能は、モデル開発におけるデータセットの管理および分析方法を標準化します。データセット・トラッキングにより、各モデルの開発および評価に使用されたデータセットを迅速に特定することができ、公正な比較を保証し、本番展開におけるモデルの選択を簡素化します。
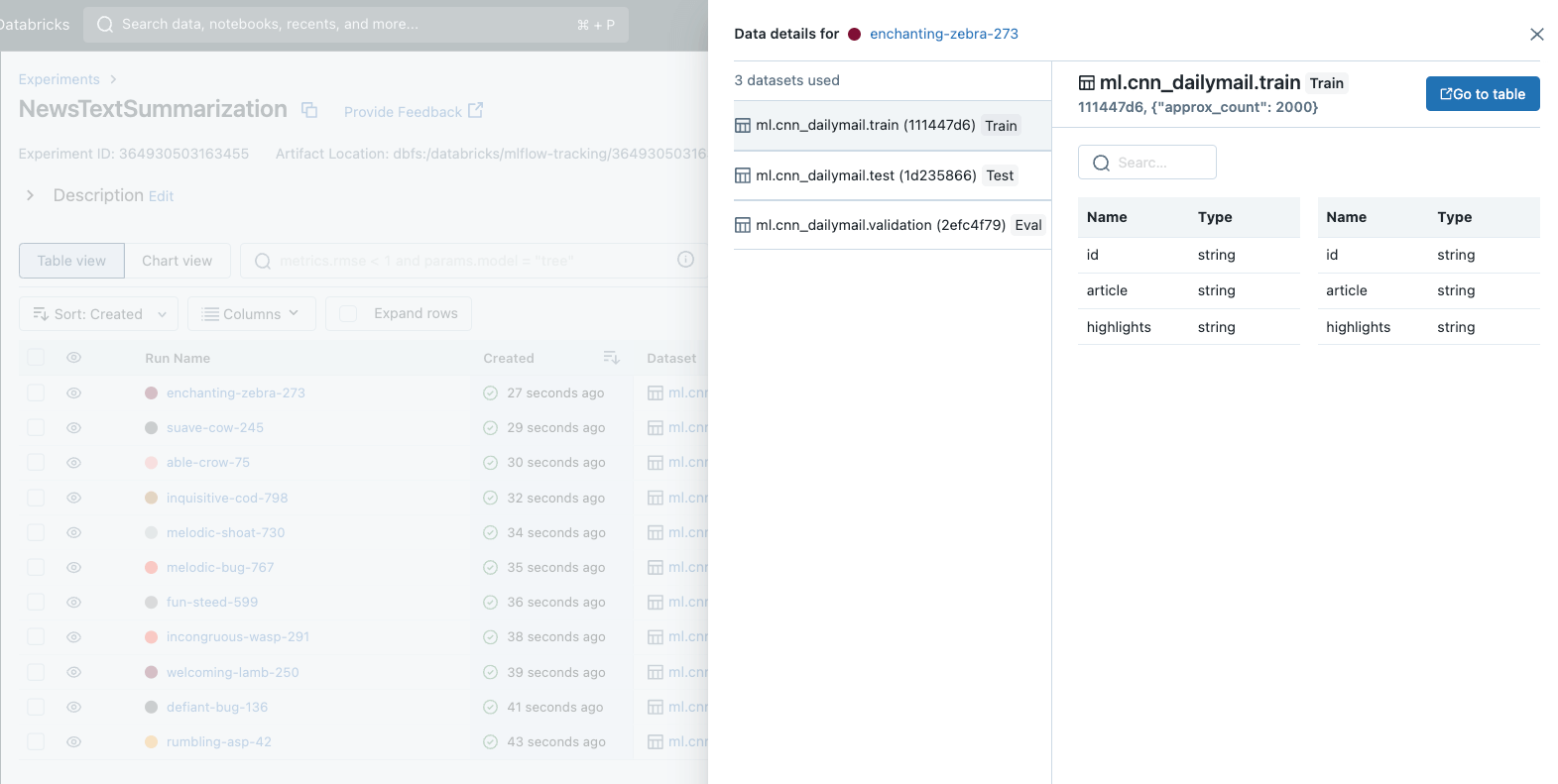
MLflowでデータ�セットトラッキングを始めるのはとても簡単です。データセット情報をMLflow Runに記録するには、mlflow.log_input() APIを呼び出すだけです。データセットトラッキングは、MLflow の Autologging と統合されており、追加のコードを必要とせずにデータインサイトを提供します。これらのデータセット情報は、分析および比較のために MLflow Tracking UI に顕著に表示されます。次の例は、mlflow.log_input() を使用して、トレーニングデータセットをランに記録し、ランからデータセットに関する情報を取得し、データセットのソースをロードする方法を示しています:
データセットのトラッキング情報および使用ガイドをもっと見る。check out the MLflow Documentation.
MLflow 2.4でLLMOpsのツールを使い始める
言語モデルの mlflow.evaluate()、言語モデル比較のための新しい Artifact View、および包括的なデータセット追跡の導入により、MLflow 2.4 はより堅牢で正確、かつ信頼できるモデルを構築できるようにユーザーを支援し続けています。特に、これらの機能強化は、LLMを使用したアプリケーションの開発体験を劇的に向上させます。
MLflow 2.4 for LLMOpsの新機能をぜひ体験してください。既存のDatabricksユーザーであれば、ノートブックやクラスタにライブラリをインストールすることで、今日からMLflow 2.4を使い始めることができます。また、MLflow 2.4はDatabricks Machine Learning Runtimeのバージョン13.2にプリインストールされる予定です。Databricks MLflowガイド [AWS][Azure][GCP] をご覧になって、ぜひ始めてみてください。まだDatabricksのユーザーでない方は、databricks.com/product/managed-mlflowで詳細を確認し、DatabricksとManaged MLflow 2.4の無料トライアルを開始してください。MLflow 2.4の新機能と改善点の全リストはrelease changelogをご覧ください。