Amazon EC2 G6インスタンス対応をDatabricksが発表

私たちは、Databricksが現在、Amazon EC2 G6インスタンスをNVIDIA L4 Tensor Core GPUでサポートすることを発表することを嬉しく思います。これによりDatabricksデータインテリジェンスプラットフォーム上でのより効率的でスケーラブルなデータ処理、機械学習、AIワークロードを可能にする一歩を示しています。
AWS G6 GPUインスタンスの利点は何ですか?
Amazon Web Services (AWS)のG6インスタンスは、低コストでエネルギー効率の高いNVIDIA L4 GPUを搭載しています。このGPUは、NVIDIAの第4世代テンソルコアAda Lovelaceアーキテクチャに基づいており、最も要求の厳しいAIや機械学習のワークロードをサポートします。
- G6インスタンスは、NVIDIA T4 GPUを使用するG4dnインスタンスと比較して、ディープラーニングの推論やグラフィックスワークロードで最大2倍のパフォーマンスを提供します。
- G6インスタンスは、NVIDIA A10GテンソルコアGPUを搭載したG5インスタンスの2倍の計算能力を持ちながら、メモリ帯域幅は半分です。(注: 多くのLLMやその他の自己回帰型トランスフォーマーモデルの推論はメモリに依存する傾向があるため、A10Gはチャットなどの用途に依然として適しているかもしれませんが、L4は計算負荷の高いワークロードでの推論に最適化されています。)
ユースケース:AIと機械学習のワークフローを加速する
- ディープラーニング推論: L4 GPUは、バッチ推論ワークロードに最適化されており、高い計算能力とエネルギー効率のバランスを提供します。TensorRTや他の推論最適化ライブラリに優れたサポートを提供し、コンピュータビジョン、自然言語処理、推奨システムなどのアプリケーションでのレイテンシを減らし、スループットを向上させます。
- 画像と音声の前処理: L4 GPUは並列処理に優れており、これは画像や音声の前処理のようなデータ集約型のタスクにとって重要です。例えば、画像やビデオのデコードや変換はGPUから利益を得るでしょう。
- ディープラーニングモデルの訓練: L4 GPUは、パラメータが少ない(10億未満)比較的小さなディープラーニングモデルの訓練に非常に効率的です
MLOps のビッグブック

使用方法
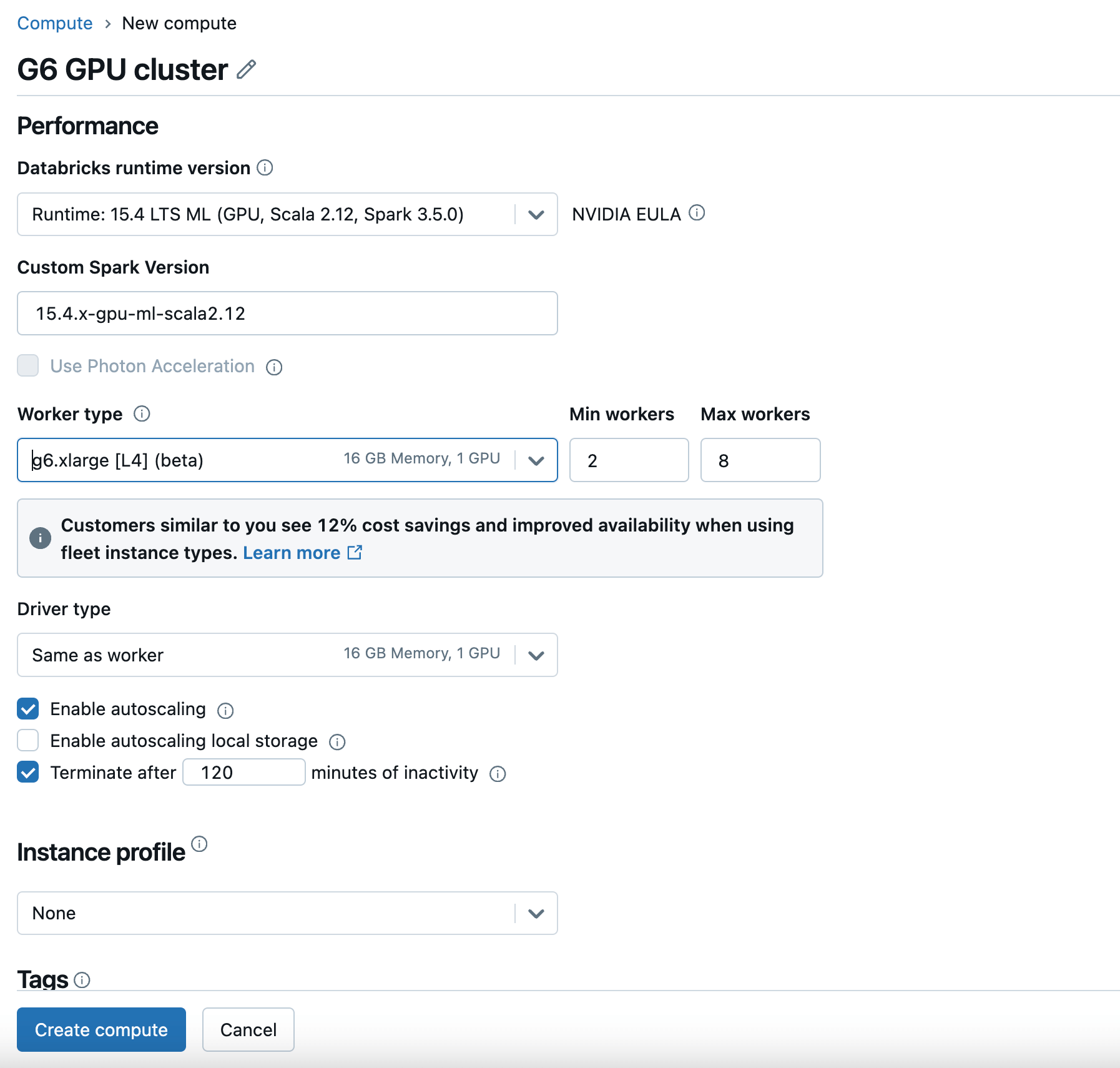
DatabricksでG6 GPUインスタンスを使用するには、GPU対応のDatabricksランタイムバージョンで新しいコンピュートを作成し、ワーカータイプとドライバータイプとしてG6を選択します。詳細は、Databricksのドキュメンテーションをご覧ください。
G6インスタンスは、現在AWS US East(N.バージニアおよびオハイオ)およびUS West(オレゴン)地域で利用可能です。将来的に利用可能な地域については、AWSのドキュメンテーションをご確認ください。
先を見据えて
AWSでのG6 GPUサポートの追加は、DatabricksがAIとデータ分析のイノベーションの最前線に立ち続けるための多くの取り組みの一環です。お客様が最新のプラットフォーム機能を活用し、独自のデータからインサイトを得ることに意欲的であることを私たちは理解しています。今後もGr6やP5eインスタンスなどのGPUインスタンスタイプや、AMDなどのさらなるGPUタイプのサポートを拡大していく予定です。お客様が利用できるようになるAIコンピュートの革新を積極的にサポートしていくことが私たちの目標です。
まとめ
推奨システムのようなDLモデルをトレーニングしたい研究者、UCからのデータを使ってDLバッチ推論を実行したいデータサイエンティスト、あるいはビデオやオーディオデータを処理したいデータエンジニアにとって、今回の最新の統合により、DatabricksがあらゆるデータとAIのニーズに応える堅牢で将来に備えたプラットフォームを提供し続けることが可能になりました。
今すぐ始めて、Databricks上でのデータと機械学習ワークロードにおける次世代のパフォーマンスを体験してください。
