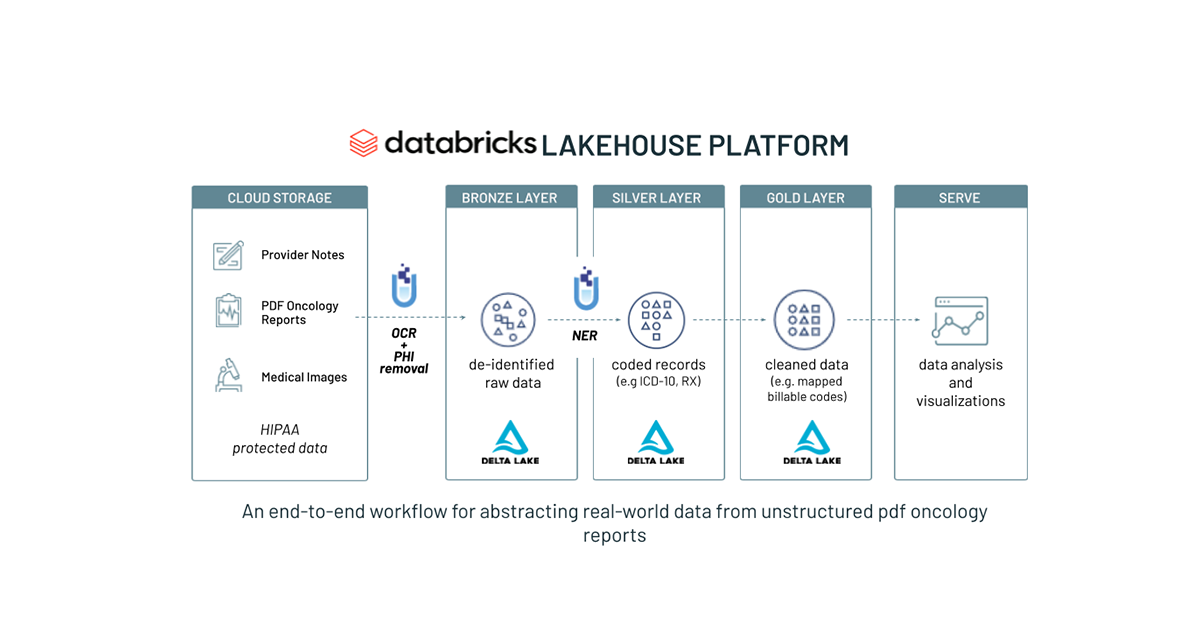
Databricks上で高度にスケーラブルなディープ推薦システムを訓練する(パート1)

推薦システム(RecSys)は、さまざまなプラットフォームでパーソナライズされたコンテンツの提案を支える現代のデジタル体験の不可欠な部分となって�います。これらの洗練されたシステムとアルゴリズムは、ユーザーの行動、好み、アイテムの特性を分析し、興味のあるアイテムを予測し、推奨します。ビッグデータと機械学習の時代において、推薦システムは単純な協調フィルタリングのアプローチから、深層学習技術を活用する複雑なモデルへと進化しています。
これらの推薦システムをスケールすることは、特に何百万人ものユーザーや何千もの製品を扱う場合には、困難な場合があります。これを行うには、コスト、効率、精度のバランスを見つける必要があります。 このスケーラビリティの問題に対処する一般的なアプローチは、2段階のプロセスを含みます:初期の効率的な「広範な検索」に続いて、最も関連性の高いアイテムに対するより計算的に集中的な「狭範な検索」です。例えば、映画の推薦では、効果的なモデルはまず検索空間を数千からユーザーごとに約100項目に絞り込み、その後、上位10の推薦を正確に順序付けるためにより複雑なモデルを適用するかもしれません。この戦略は、推薦品質を維持しながらリソース利用を最適化し、大規模推薦システムのスケーラビリティの課題に対処します。
多くの企業は、この規模の推奨システムを構築し、スケールアップするためのリソースを持っていませんが、Databricksは、データ処理、特徴エンジニアリング、モデル訓練、モニタリング、ガバナンス、サービングなど、最先端の推奨システムを作成するために組み合わせることができるすべての基本的な�コンポーネント、およびそれらを実装するための技術サポートリソースを提供します。この記事は、Databricks上でスケールする推奨モデルの訓練とデプロイの効果的な手法を示すためのシリーズの最初のものです。この記事では、分散データローディングと訓練に焦点を当てています。後続の記事では、分散チェックポイント、推論、ベクトルストアなどの補完的なコンポーネントの統合について探求し、堅牢なエンドツーエンドの推奨システムパイプラインを作成します。

この記事では、Databricks Data Intelligence Platformで企業規模の推奨システムを訓練するための堅牢な基盤となる一連の参照ソリューションを紹介します。これらのソリューションは、Mosaic Streamingをデータローダーとして、TorchDistributorを分散訓練のオーケストレーターとして使用しています。これらはいずれもDatabricks社内で開発されました。PyTorchを活用した高度にスケーラブルな推奨システムパッケージであるTorchRecを使用することで、先述の二段階アプローチに合致する2つの高度な深層学習モデルの実装を示します。それらは、効率的な「広範な検索」フェーズに最適なTwo Tower modelと、より集中的な「狭範な検索」フェーズに適したMetaのDLRM(Deep Learning Recommendation Model)です。両モデルとも、何百万人ものユーザーとアイテムを効率的に処理することができ、Two Towerモデルは候補セットを何百万人から数千人に素早く絞り込み、DLRMは最も関連性の高いアイテムの精確な順序付けを提供します。これらのモデルをあなたのワークスペースやプロジェクトにシームレスに統合するために、私たちはこれらのモデルをDatabricks marketplaceで利用可能にしました。
Two Tower
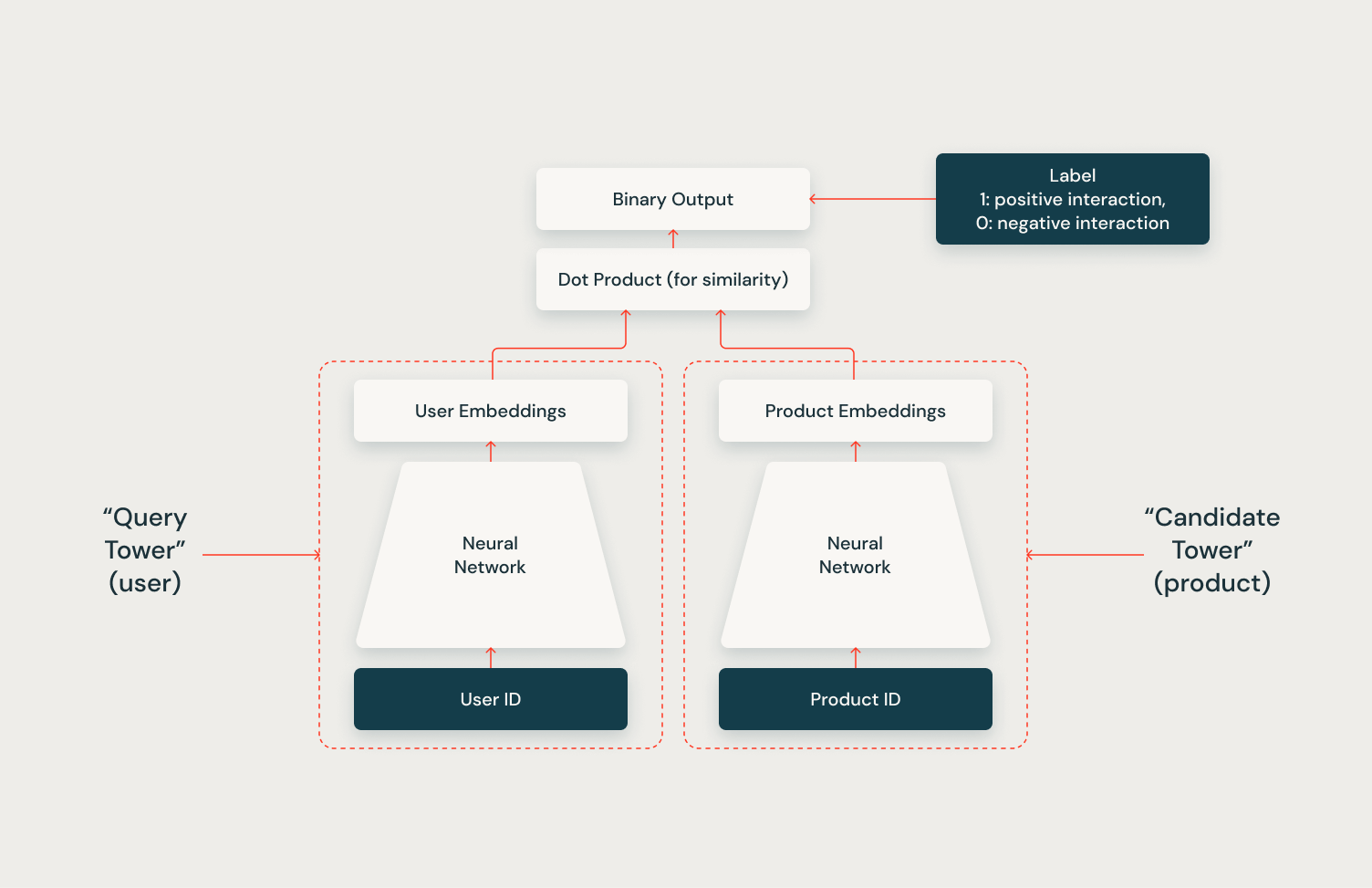
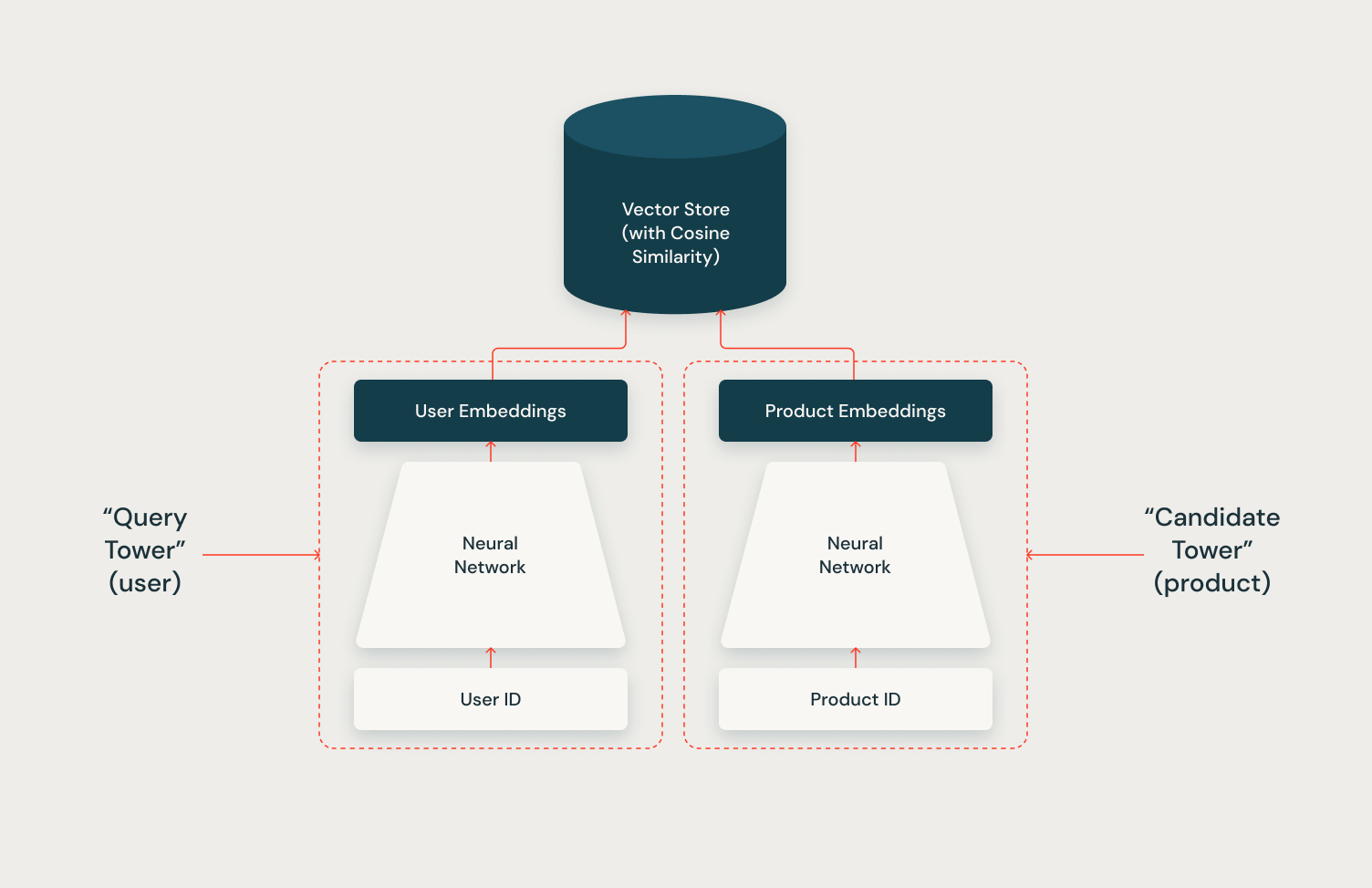
Two Towerアーキテクチャの全能力は、ベクトルストアとの統合を通じて実現されます。ベクトルストアを利用して候補ベクトルをインデックス化することで、システムは推論中に各ユーザーに対して効率的かつスケーラブルに数百の関連候補を取得することができます。このシリーズの次の記事では、Mosaic AI Vector StoreとTwo Towerモデルを使用してこの統合を実装する方法を示し、この組み合わせたアプローチの力を示します。
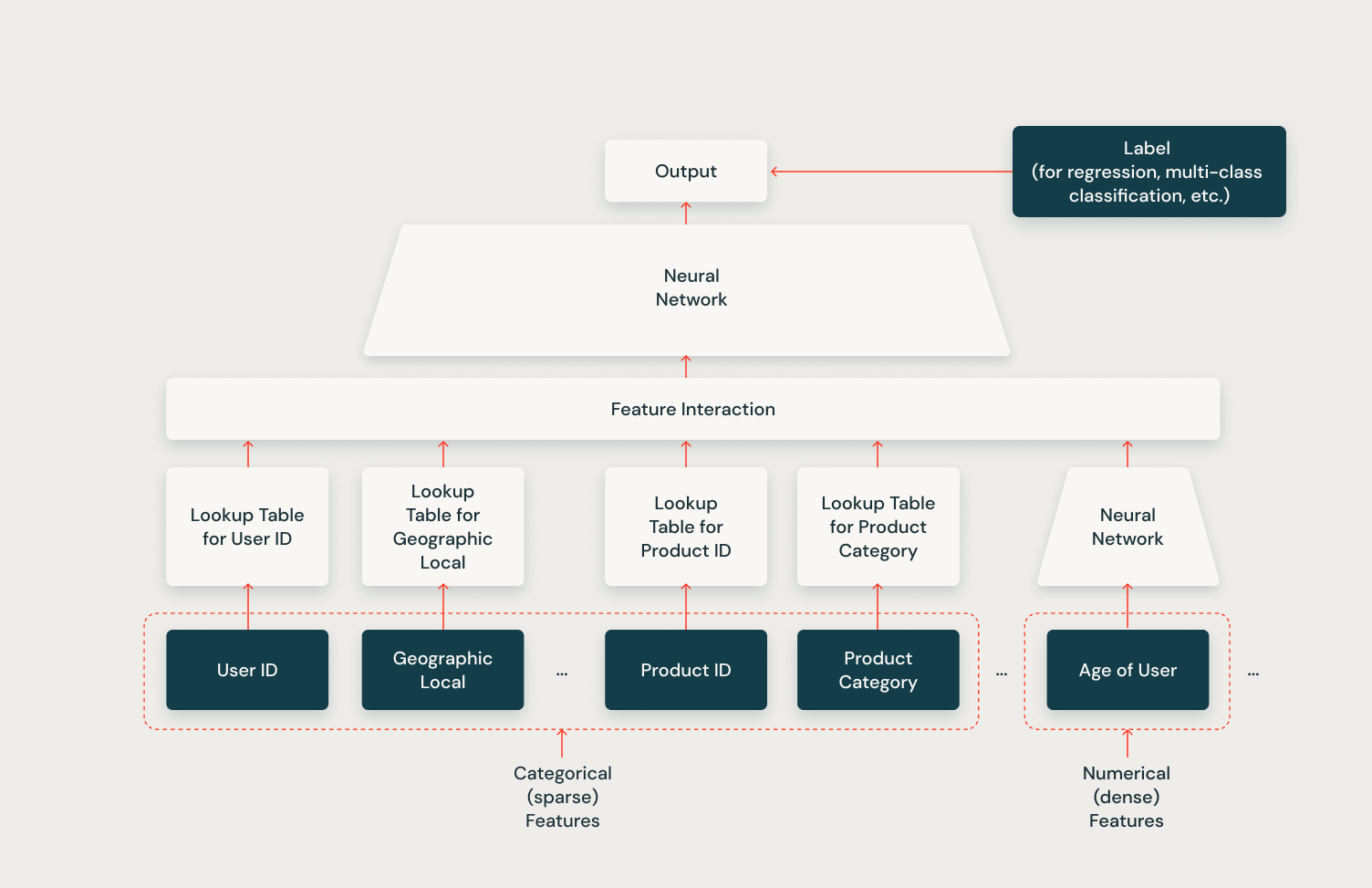
DLRM
以下の図に示すように、MetaによるDeep Learning Recommendation Model(DLRM)は、大規模な推奨システムのために設計された洗練されたアーキテクチャです。それは効率的にカテゴリカル(スパ�ース)と数値(密)の両方の特徴を扱うことができ、様々な推奨タスクに非常に多用途です。モデルはルックアップテーブルを使用してカテゴリカルな特徴を埋め込み、これらの埋め込みは数値特徴と共に特徴相互作用層を通じて処理されます。このレイヤーは、異なる特徴タイプ間の複雑な関係を捉えます。結合された特徴は次にニューラルネットワークに供給され、さらに情報を処理して最終的な出力を生成します。この出力は、特定の推奨問題に応じて回帰や多クラス分類などのさまざまなタスクに使用できますが、最もよくクリックスルーレートの予測に使用されます。DLRMが多様な特徴タイプを扱い、複雑な特徴相互作用を捉える能力は、推奨システムにおける「狭い検索」フェーズでの精密なアイテムランキングに特に効果的です。
本番レベルのDLRMモデル訓練には、Databricks Feature Storeの活用を推奨します。この強力なツールにより、ユーザーとアイテムの両方に対して多様な特徴配置の訓練データセットをシームレスに作成することが可能になります。現在のDatabricksのドキュメンテーションでは、よりシンプルな推奨システムの例が提供されていますが、このシリーズの今後の記事では、ここで議論されるモデルとDatabricks Feature Storeをどのように統合するかを示します。
レコメンデーションモデルの訓練方法
両方のトレーニング推奨モデルの例は、大規模分散トレーニングのための最先端の技術を使用して、同様の全体的な構造を共有しています。
モザイクストリーミングを用いたデータ前処理とデータローディング
これらの段階での例は、Mosaic Streamingを活用しています。これは、クラウド環境に保存された大規模なデータセットでの訓練プロセスを最適化するための重要なツールです。このアプローチは効率性、コスト効果、スケーラビリテ��ィを最大化します。大規模な推奨システム、特に何百万人ものユーザーやアイテムを対応させる必要があるものを訓練する際には、多ノード訓練がしばしば必要となります。しかし、分散データローディングは、同期問題、メモリ管理、実行間の再現性など、さまざまな課題を引き起こします。
Mosaic Streamingはこれらの課題に対処するために特別に設計されています。 これは、大規模モデルのマルチノード、分散トレーニングをサポートするように特別に設計されており、正確性の保証、パフォーマンスの最適化、柔軟性の提供、使いやすさの向上に焦点を当てています。これらの重要な側面に取り組むことで、Mosaic Streamingは、分散トレーニング環境に関連する一般的な問題を緩和しながら、推奨システムのシームレスなスケーリングを可能にします。
前処理ステージにはいくつかのステップが含まれます:
- Unity Catalogのテーブルから訓練データを収集します
- 必要なデータ変換を実行する
- Mosaic Streamingのdataframe_to_mds APIを使用して処理済みデータをUnity Catalog Volumeにマテリアライズします
次に、私たちは訓練関数でMosaic AIのStreamingDatasetとStreamingDataLoader APIを使用して、分散環境の各ノードに関連するデータを簡単にロードします。StreamingDataLoaderは、中間エポックの再開が必要な場合に必要です。それが必要ない場合は、ネイティブのTorch DataLoaderを使用しても問題ありません!
TorchRecとTorchDistributorを用いたモデル訓練の並列化
ユーザーやアイテムが数百万にまで拡大する必要がある推奨システムは、単一のノードが処理するには圧倒的すぎることがあります。その結果、これらの大規模な深層推奨モデルの訓練には、しばしば複数のノードへのスケーリングが必要となります。この課題に対処するために、ソリューションはPyTorchのTorchRecライブラリとPySparkのTorchDistributorを組み合わせて、Databricks上での推奨モデルの訓練を効率的にスケールアップします。
TorchRecは、PyTorchに基づいたドメイン特化型ライブラリで、大規模な推薦システムのための必要なスパース性と並列性のプリミティブを提供することを目指しています。TorchRecの主な特徴は、大規模な埋め込みテーブルを効率的に複数のGPUやノードに分割する能力で、これはDistributedModelParallelおよびEmbeddingShardingPlannerAPIを使用しています。特筆すべきは、TorchRecはMetaの最大のモデル、特に1.25兆パラメータモデルや3兆パラメータモデルの運用において重要な役割を果たしていることです。
TorchRecを補完するTorchDistributorは、PySparkに統合されたオープンソースモジュールで、Databricks上でPyTorchを使用した分散トレーニングを容易にします。これは、Distributed Data ParallelやTensor Parallelなど、PyTorchが提供するすべての分散トレーニングパラダイムを、単一ノードマルチGPUやマルチノードマルチGPU設定など、さまざまな設定でサポートするように設計されています。さらに、現在のノートブック内で定義された関数や外部トレーニングファイルを使用してトレーニングを実行することを可能にする最小限のAPIを提供します。TorchDistributorの使用例は次のとおりです:
TorchRecとTorchDistributorの組み合わせにより、エンタープライズ級の推奨システムで一般的な大規模なデータセットと複雑なモデルの効率的な処理が可能になります。
MLflowを使用したロギング
提供された参照ソリューションでは、MLflowを使用して、モデルのハイパーパラメータ、メトリクス、モデルのstate_dictなどの重要な項目をログに記録します。例のノートブックで採用されたアプローチは、分散モデルを一つのノードに集めてからMLflowに保存しますが、これは一つのノードに収まらないほど大きなモデルには適用できません。この問題を解決するために、このシリーズの次の記事では、Databricks上での分散モデルチェックポイントと大規模モデル推論の方法について詳しく説明します。
次のステップ
この記事では、Databricks上で高度にスケーラブルな深層推薦モデルを実装し、訓練するための参考ソリューションを紹介しました。Two TowerアーキテクチャとDLRMアーキテクチャについて簡単に説明し、それらが拡張された推奨システムパイプラインのどこに位置するかを説明しました。 最後に、Databricks上でのこれらの推薦モデルの分散データローディングと分散モデル訓練の詳細について深く掘り下げました。これは始まりに過ぎません:このシリーズの今後の記事では、分散モデルの保存、推論、Databricks上の他のツールとの統合を含む、推薦システムの製品化に関する追加の側面について議論します。