Databricksで高品質のRAGアプリケーションを作成する
ジェネレーティブAIアプリケーションを本番稼動させるための新しいツール群

RAG(Retrieval-Augmented-Generation)は、独自のリアルタイムデータをLLM(Large Language Model)アプリケーションに組み込む強力な方法として、急速に台頭してきた。 本日Databricksユーザーが企業データを使用して高品質な本番LLMアプリケーションを構築するためのRAGツール群を発表できることを嬉しく思う。
LLMは、新しいアプリケーションを迅速にプロトタイプ化する能力において、大きなブレークスルーをもたらした。 しかし、RAGアプリケーションを構築している何千もの企業と仕事をした結果、彼らの最大の課題は、これらのアプリケーションを本番で用いることができる品質にすることであることがわかった。 顧客向けアプリケーションに要求される品質基準を満たすためには、AIの出力は正確で、最新で、そして企業のコンテキストを認識し、安全でなけれ�ばならない。
高品質なRAGアプリケーションを構築するためには、開発者はデータとモデル出力の品質を理解するための豊富なツールと、RAGプロセスのあらゆる側面を組み合わせて最適化できる基盤プラットフォームが必要である。 RAGには、データ準備、検索モデル、言語モデル(SaaSまたはオープンソースのいずれか)、ランキングおよび後処理パイプライン、プロンプトエンジニアリング、カスタムエンタープライズデータでのモデルのトレーニングなど、多くのコンポーネントが含まれる。 Databricksは常に、お客様のデータと最先端のML技術を組み合わせることに注力してきた。 本日のリリースでは、この理念をさらに発展させ、高品質のAIアプリケーションを作成する際に顧客がデータを活用できるようにする。
本日のリリースには、以下のパブリック・プレビューが含まれている:
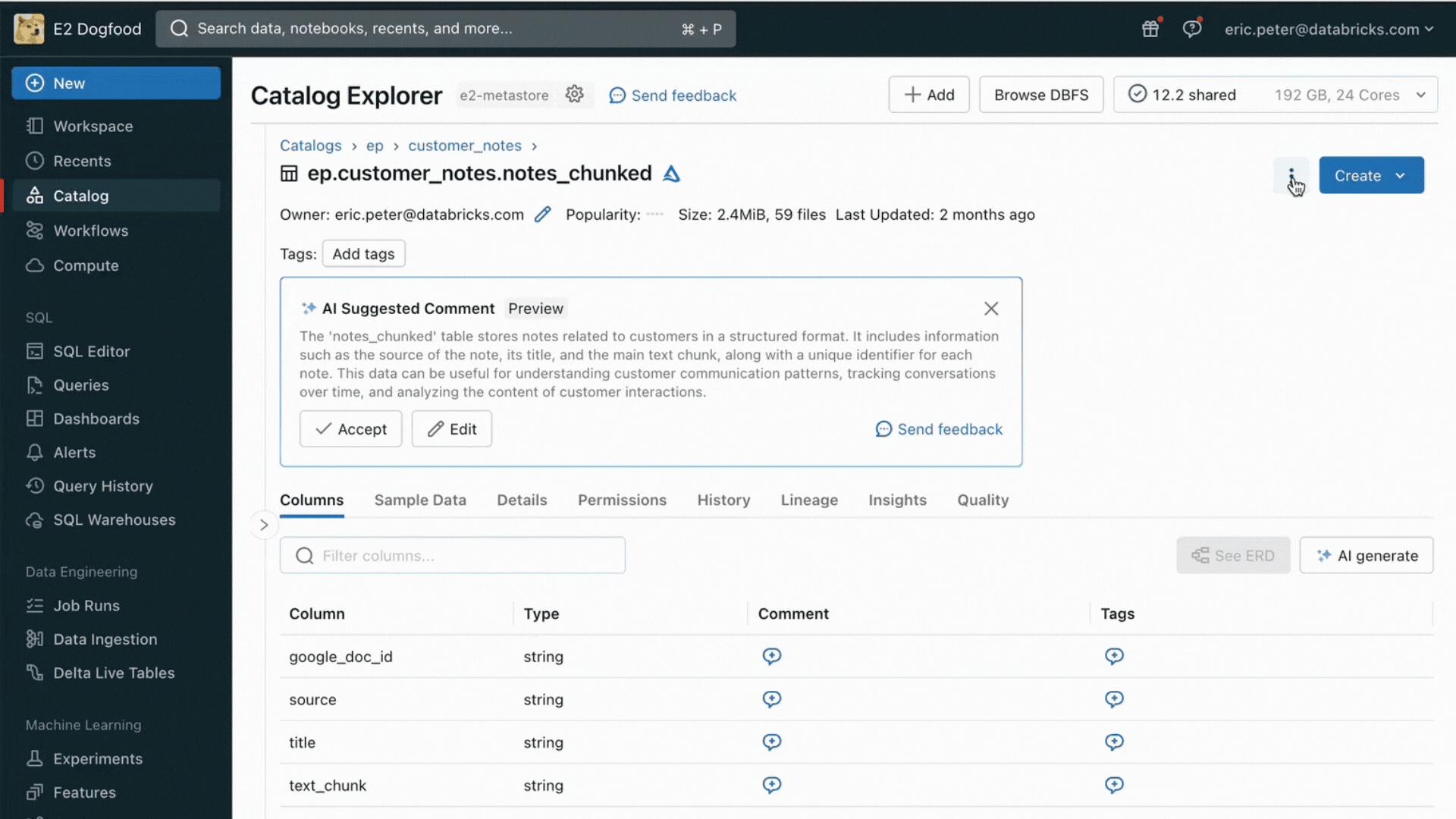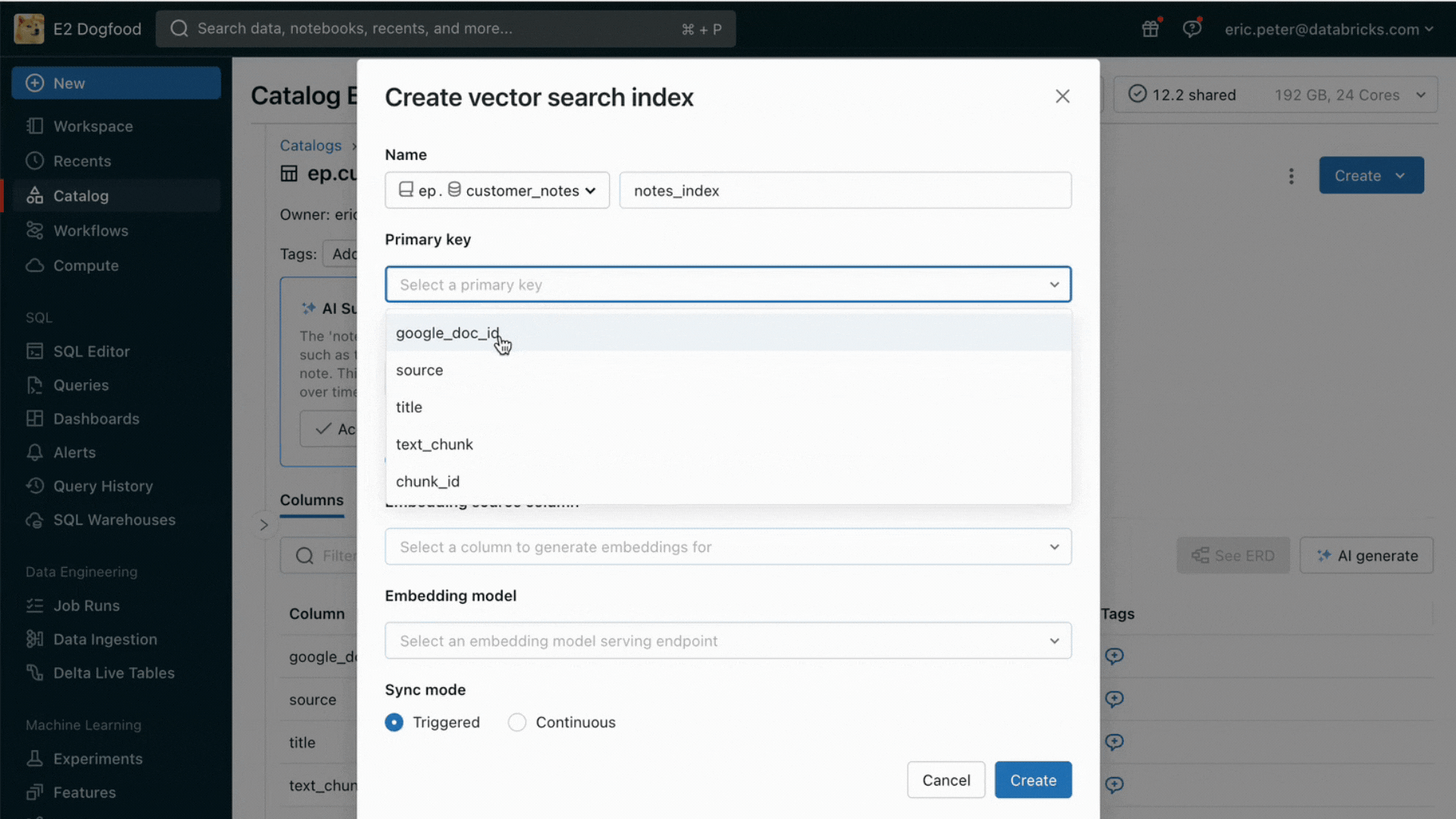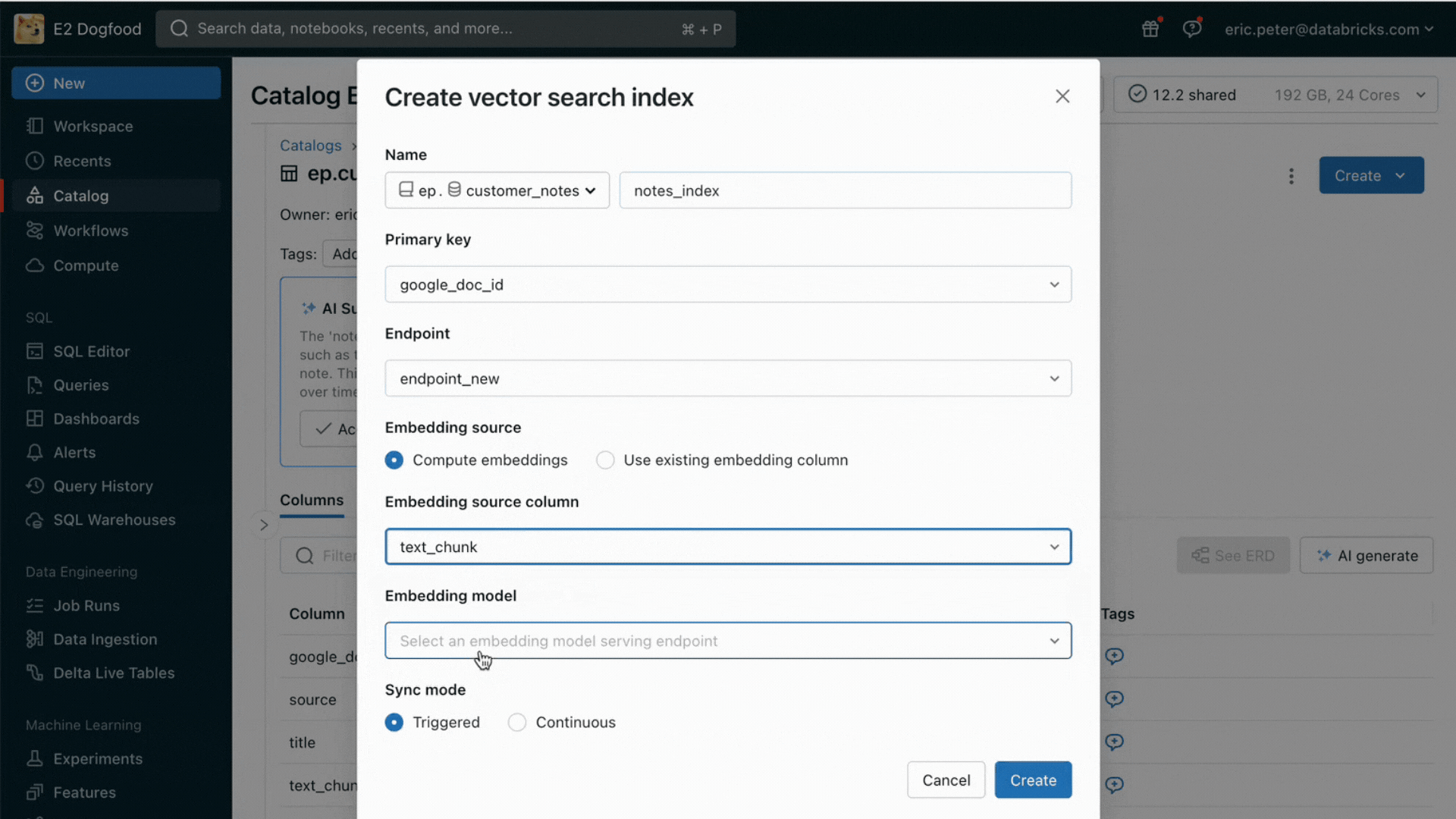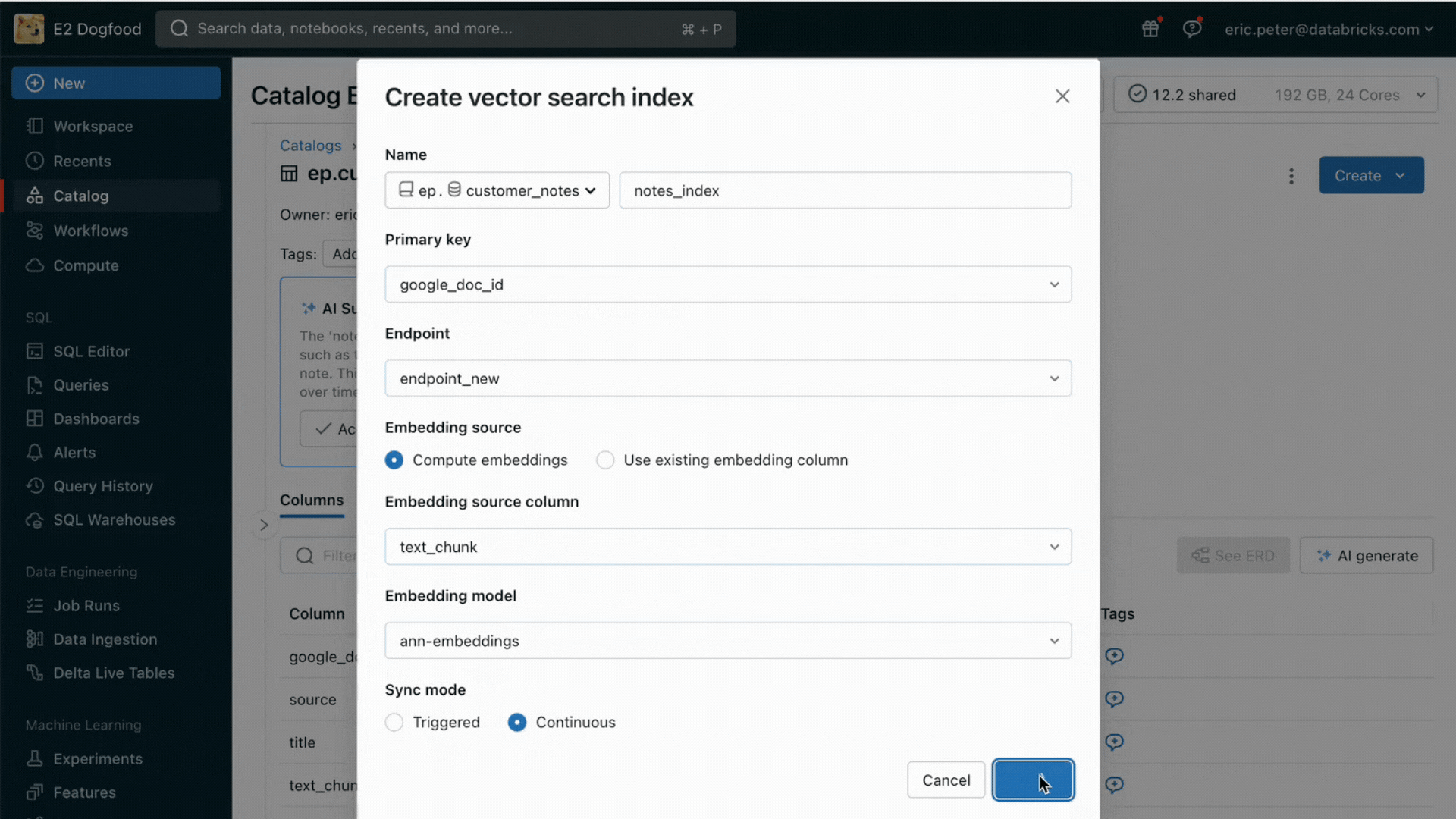
- レイクハウスの既存のテーブルをセマンティック検索するためのベクトル検索サービス
- RAGアプリが構造化されたコンテキストを利用できるようにするOnline feature と function serving
- トークン・ベースのLLMを提供するフルマネージド・ファウンデーション・モデル
- RAGアプリの本番環境でのパフォーマンスを監視するための柔軟な品質監視インターフェース
- 様々なLLMを比較・評価するためのLLM開発ツール一式
これらの機能は、本番用RAGアプリケーションを構築する際に見られる3つの主要な課題に対処するために設計されている:
チャレンジ#1 - RAGアプリにリアルタイムデータを提供する
RAGアプリケーションは、お客様の最新の構造化データと非構造化データを組み合わせて、最高品質で最もパーソナライズされた応答を生成する。 しかし、オンラインデータ配信インフラを維持することは非常に困難であり、企業はこれまで、複数のシステムをつなぎ合わせ、中央データレイクから特注の配信レイヤーにデータをロードするための複雑なデータパイプラインを維持しなければならなかった。 重要なデータセットの保護も、コピーが異なるインフラスタックにまたがってストライピングされている場合は非常に難しい。
このリリースにより、Databricksはオンライン検索のためのデータ提供およびインデックス作成をネイティブにサポートする。非構造化データ(テキスト、画像、動画)に対して、Vector Searchは自動的にインデックスを作成し、Deltaテーブルからデータを提供する。Vector Searchは、失敗を管理し、再試行を処理し、バッチサイズを最適化して、最高のパフォーマンス、スループット、コストを提供する。構造化されたデータに対しては、Feature and Function Servingが、ユーザーやアカウント・データなど、企業がユーザー情報に基づいてカスタマイズするためにプロンプトに注入したいと考えることの多いコンテキスト・データのミリ秒単位のクエリーを提供する。
Unity Catalogは、提供されるデータセットのオフラインコピーとオンラインコピー間の系統を自動的に追跡するため、データ品質の問題のデバッグが非常に容易になる。また、オンラインとオフラインのデータセット間のアクセス制御設定を一貫して実施するため、企業は機密性の高い専有情報を誰が閲覧しているかをより適切に監査・管理できる。
チャレンジ#2 - ファンデーションモデルの比較、チューニング、提供
RAGアプリケーションの品質を決定する主な要因は、ベースとなるLLMモデルの選択である。推論能力、ハルシネーション傾向、コンテクストウィンドウの大きさ、サービングコストなど、いくつかの次元でモデルが異なるため、モデルの比較は困難である。また、モデルによっては、特定の用途に合わせて微調整が可能なものもあり、これによってパフォーマンスをさらに向上させ、コストを削減できる可能性もある。ほぼ毎週のように新しいモデルがリリースされる中、特定のアプリケーションに最適な選択を見つけるために、ベースモデルの並べ替えを比較するのは非常に負担がかかる。さらに事態を複雑にしているのは、モデル・プロバイダがしばしばバラバラのAPIを持っていることで、RAGアプリケーションの迅速な比較や将来への備えが非常に困難になっていることだ。
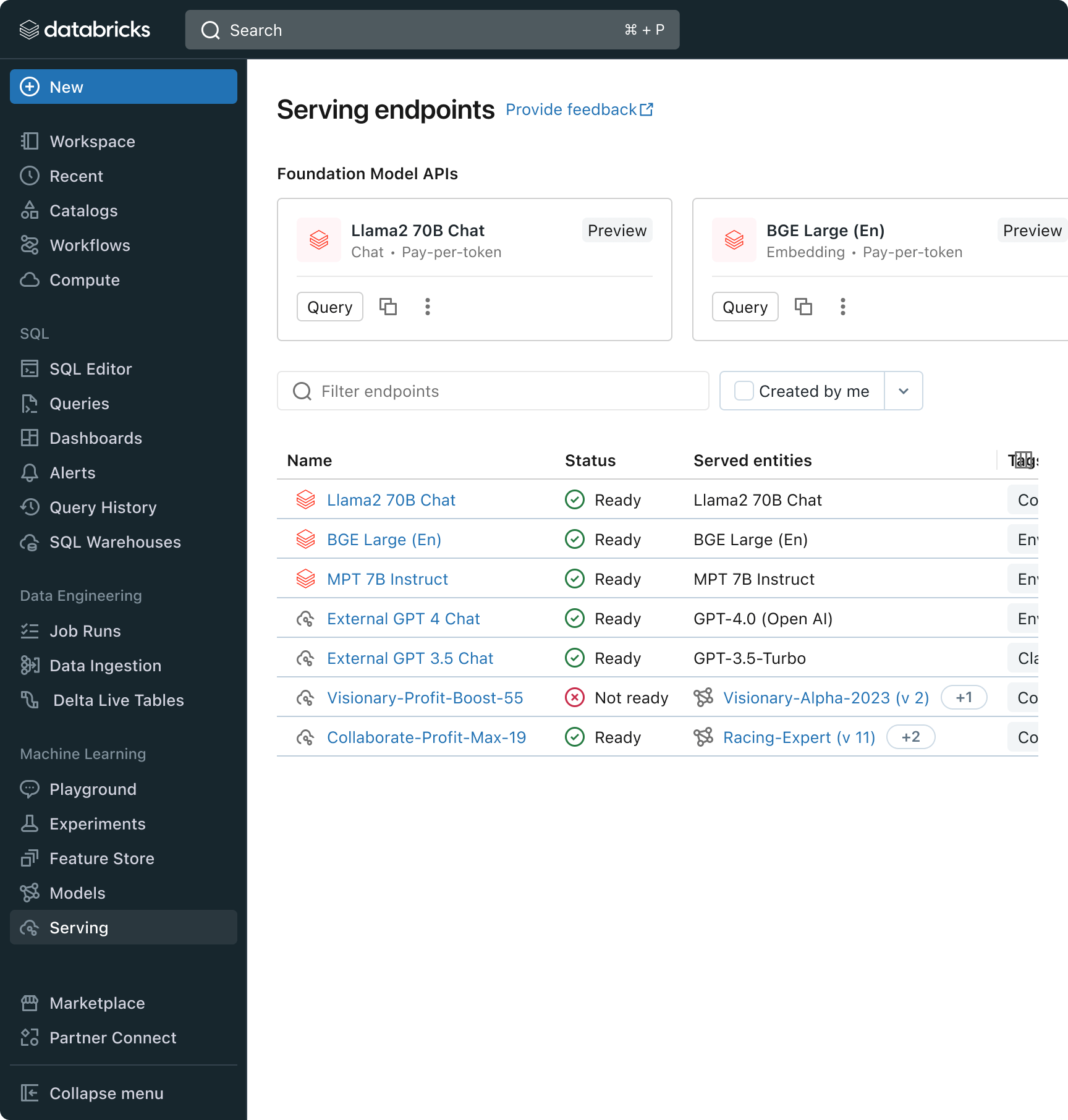
このリリースにより、DatabricksはLLMの開発と評価のための統一された環境を提供し、クラウドにとらわれないプラットフォーム上で、モデルファミリー間で一貫したツールセットを提供する。Databricksのユーザーは、Azure OpenAI Service、AWS Bedrock、Anthropicの主要モデル、Llama 2やMPTなどのオープンソースモデル、または顧客の微調整された完全カスタムモデルにアクセスすることができる。MLflowと統合されたツールチェーンは、毒性、待ち時間、トークン数のような主要メトリクスを追跡することにより、豊富な比較を可能にする。PlaygroundまたはMLflowでモデルを並べて比較することで、顧客は各ユースケースに最適なモデル候補を特定することができ、レトリーバー・コンポーネントの評価もサポートする。
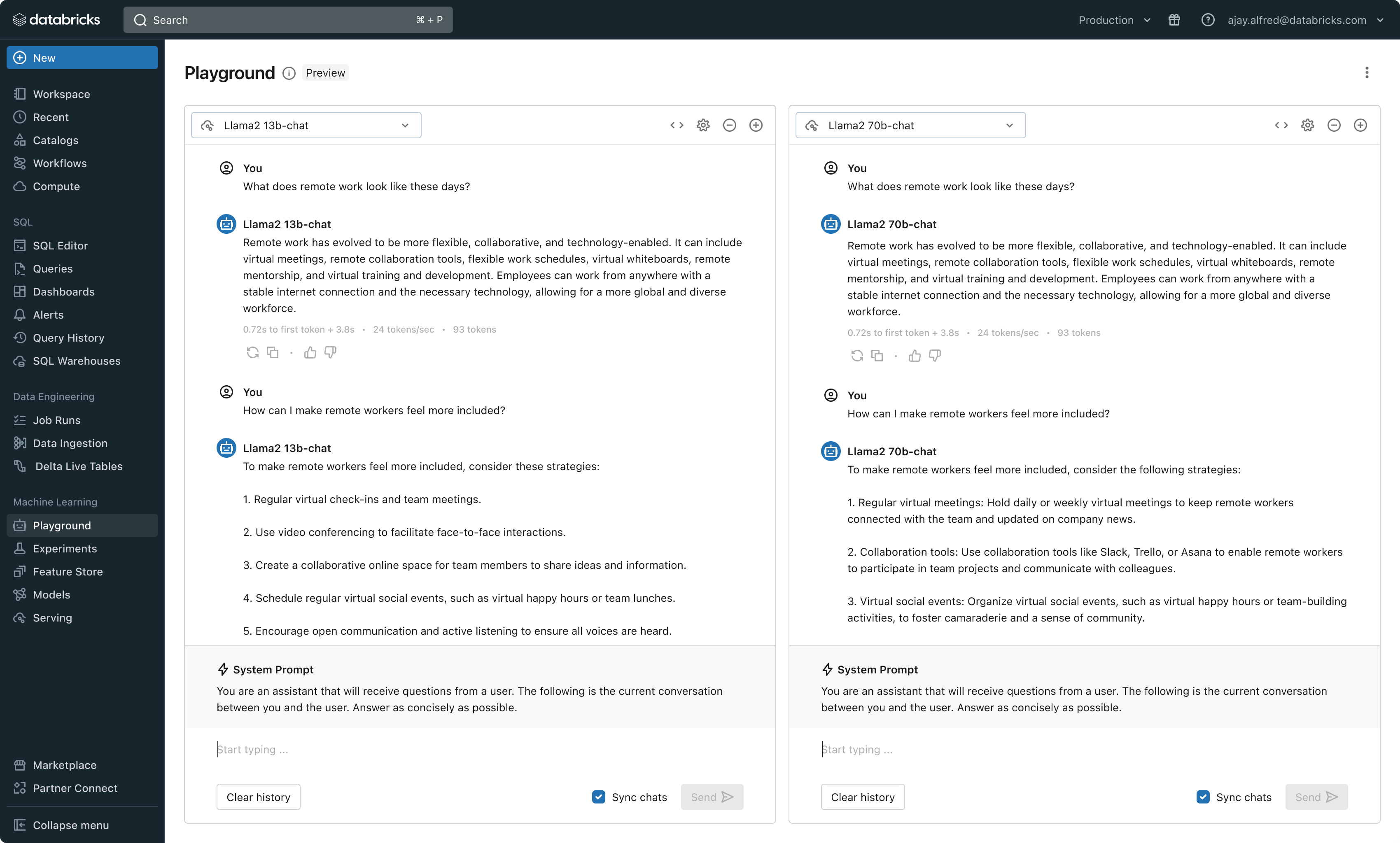
Databricks はまた、人気の高い Llama と MPT モデルファミリーを含む、完全に管理された LLM モデルのセットである Foundation Model API's をリリースしている。Foundation Model API'sは、トークンごとに課金されるため、コストを大幅に削減し、柔軟性を高めることができる。Foundation Model APIはDatabricksのインフラストラクチャから提供されるため、機密データをサードパーティのサービスに転送する必要がない。
実際には、高品質を達成するためには、各アプリケーションの特定の要件に従ってベースモデルをミックス&マッチングする必要がある。DatabricksのModel Servingアーキテクチャは、完全なカスタムモデルであれ、Databricksが管理するモデルであれ、サードパーティの基盤モデルであれ、あらゆるタイプのLLMをデプロイ、管理、クエリするための統一されたインターフェイスを提供する。この柔軟性により、顧客は適切な業務に適切なモデルを選択することができ、将来的に利用可能なモデルが増加した場合でも、将来性を確保することができる。
課題その3 - 生産における品質と安全性の確保
いったんLLMアプリケーションがデプロイされると、それがどの程度うまく機能しているかを知るのは難しいかもしれない。従来のソフトウェアとは異なり、言語ベースのアプリケーションには、単一の正解や明らかな「エラー」条件がない。このことは、品質(これがどの程度機能しているか)や、異常、安全でない、あるいは有害な出力(これは安全か)を構成するものを理解することが、自明でないことを意味する。Databricksでは、多くの顧客がRAGアプリケーションの展開を躊躇しているのを見てきた。それは、小規模な社内プロトタイプで観察された品質が、スケールしたユーザーベースに反映されるかどうかわからないからだ。
今回のリリースに含まれるLakehouse Monitoringは、RAGアプリケーションのための完全管理型品質監視ソリューションを提供する。Lakehouse Monitoringは、アプリケーションの出力を自動的にスキャンし、有害、幻覚、その他安全でないコンテンツを検出することができる。このデータは、ダッシュボード、アラート、その他の下流データパイプラインにフィードされ、その後のアクションに活用される。モニタリングはデータセットやモデルのリネージと統合されているため、開発者は古くなったデータパイプラインや予期せず挙動が変化したモデルなどに関連するエラーを迅速に診断することができる。
モニタリングは安全性だけでなく、品質にも関わる。Lakehouse Monitoringは、"thumbs up/thumbs down "スタイルのユーザーフィードバックや、"user accept rate"(エンドユーザーがAIが生成したレコメンデーションを受け入れる頻度)のような派生メトリクスなど、アプリケーションレベルの概念を組み込むことができる。我々の経験では、エンド・ツー・エンドのユーザー・メトリクスを測定することで、RAGアプリケーションが実運用でうまく機能しているという企業の自信を大幅に強化することができる。モニタリング・パイプラインもDatabricksによって完全に管理されるため、開発者は観測可能なインフラを管理するよりも、アプリケーションに時間を費やすことができる。
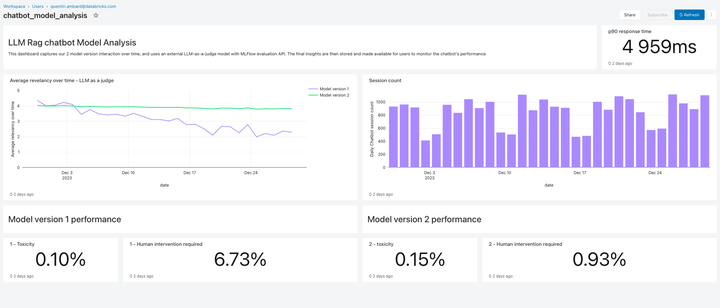
このリリースのモニタリング機能は、ほんの始まりに過ぎない。今後にご期待いただきたい!
次のステップ
今週から来週にかけて、導入のベストプラクティスについて詳しく説明するブログを用意している。 Databricksのブログを毎日ご覧いただき、新しいRAGのデモを通じて当社の製品を探索し、DatabricksGenerative AI Webセミナーをオンデマンドでご覧ください:

Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満