Apache Spark 構造化ストリーミングにおけるステートフルパイプラインの最新パフォーマンス改善へのディープダイブ
によって Mojgan Mazouchi, ムリティウンジャイ・クマール, Anish Shrigondekar 、 カルティケヤン・ラマサミー による投稿
この投稿は、ステートフル・パイプラインの最新のパフォーマンス改善に関する2部構成のシリーズの第2部です。 このシリーズの最初の部分は、Apache Spark 構造化ストリ��ーミングにおけるステートフルパイプラインのパフォーマンス改善でカバーされています。
Project Lightspeedの更新ブログでは、ステートフルパイプラインに追加したさまざまなパフォーマンス改善の概要を紹介しました。 このセクションでは、パフォーマンス分析中に観察されたさまざまな問題を掘り下げ、それらの問題に対処するために実施した具体的な機能強化の概要を説明します。
RocksDBステートストア・プロバイダの改善
メモリ管理
RocksDBは主にメモリをmemtables、ブロックキャッシュ、その他のピン留めブロックに使用します。以前は、マイクロバッチ内のすべての更新は、WriteBatchWithIndexを使用してメモリにバッファリングされていました。 さらに、ユーザーは書き込みバッファとブロックキャッシュの使用について、インスタンスごとのメモリ制限を設定することしかできませんでした。 このため、インスタンス単位でのメモリ使用量が制限されず、複数のステートストア・インスタンスが単一のワーカーノードでスケジュールされた場合に問題が深刻化しました。
このような問題に対処するため、RocksDBのライトバッファマネージャ機能を活用することで、ユーザがメモリの使用量を制限できるようになりました。 これにより、ユーザーは単一のグローバル・メモリ制限を設定して、単一のエクゼキュータ・ノード上のステート・ストア・インスタンス全体でブロック・キャッシュ、書き込みバッファ、およびフィルタ・ブロック・メモリの使用を制御できます。 さらに、WriteBatchWithIndexへの依存を完全に削除し、更新がバッファリングされずにデータベースに直接書き込まれるようにしました。
データベースの書き込み/フラッシュのパフォーマンス
最新の改良により、すべての更新が SSTファイルとして ローカルに安全に書き込まれ、その後、各マイクロバッチのチェックポイント・ディレクトリの一部として永続ストレージにバックアップされるため、 書き込み先ログ(WAL )が明示的に不要になりました。
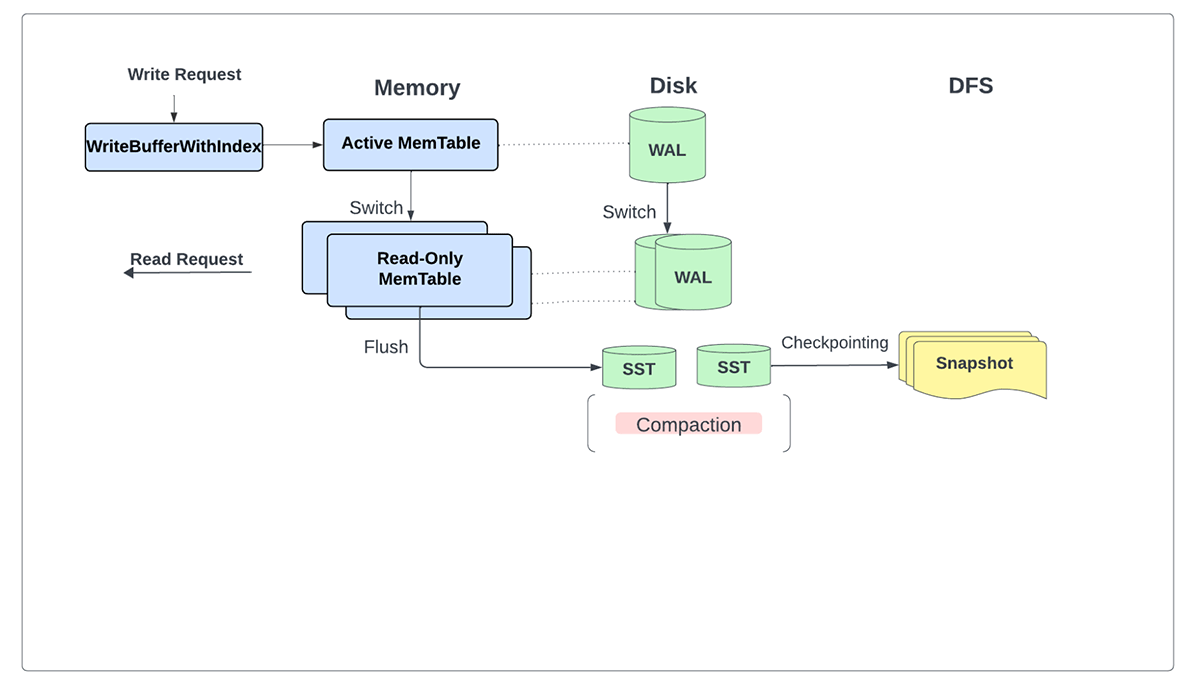
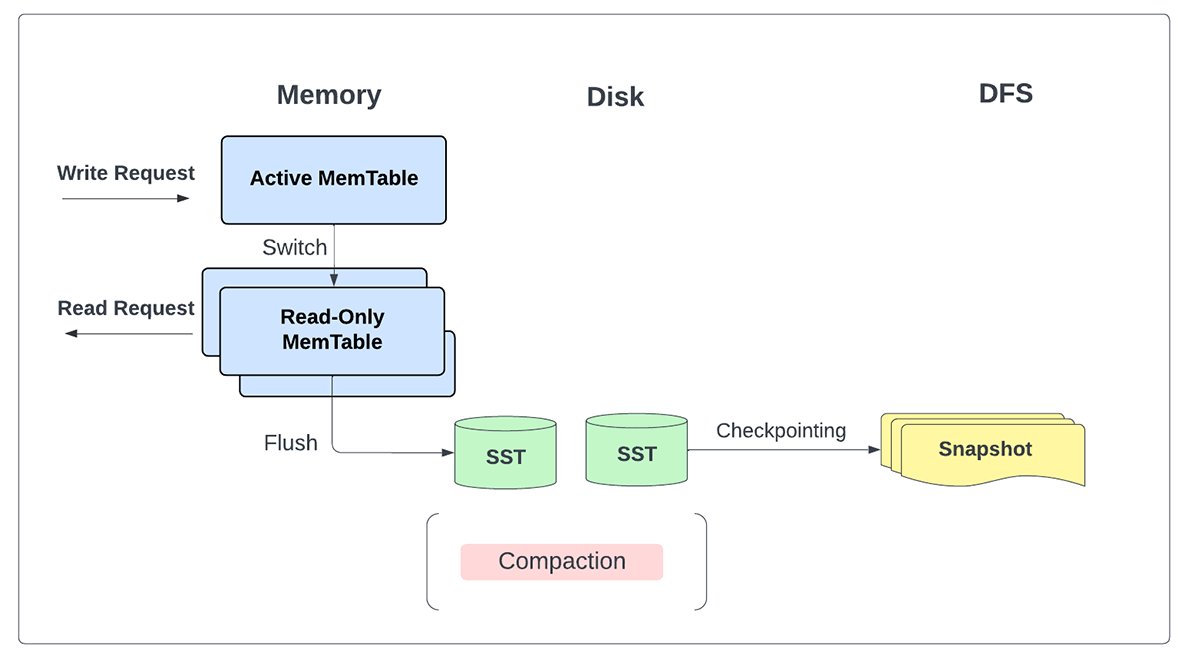
すべての読み込みと書き込みを主にメモリから提供することに加え、この変更により、マイクロバッチごとではなく、チェンジログのチェックポイントが有効になっているときに、定期的に書き込みをストレージにフラッシュできるようになりました。
変更履歴のチェックポイント
私たちは、ステートフル・ストリーミング・クエリの主要なパフォーマンス・ボトルネックの1つとして、ステートのチェックポイント待ち時間を特定しました。 この待ち時間の原因は、バックグラウンド処理に伴うRocksDBインスタンスの定期的な休止と、バッチのコミットの一部であるスナップショットの作成とアップロード処理にありました。
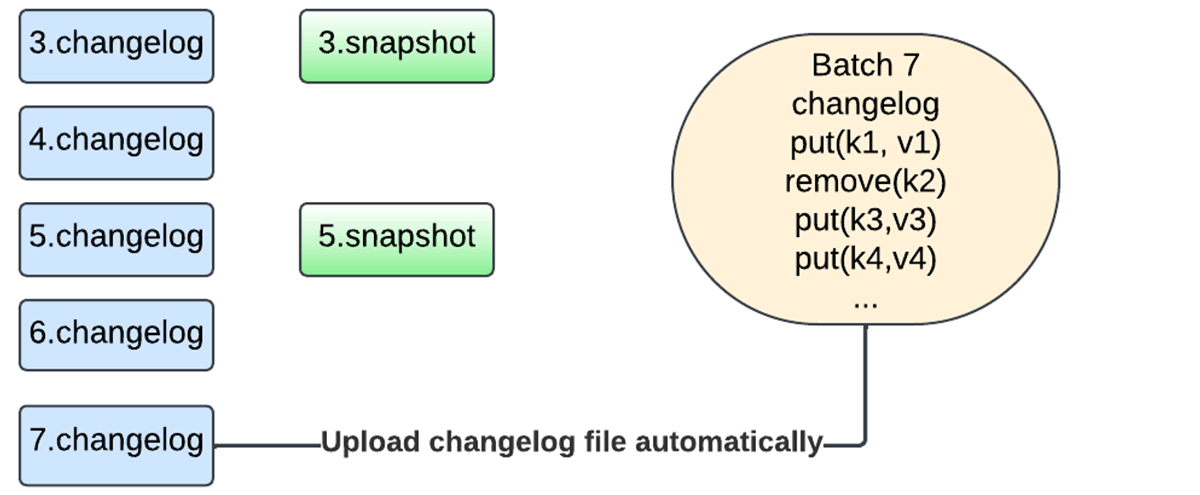
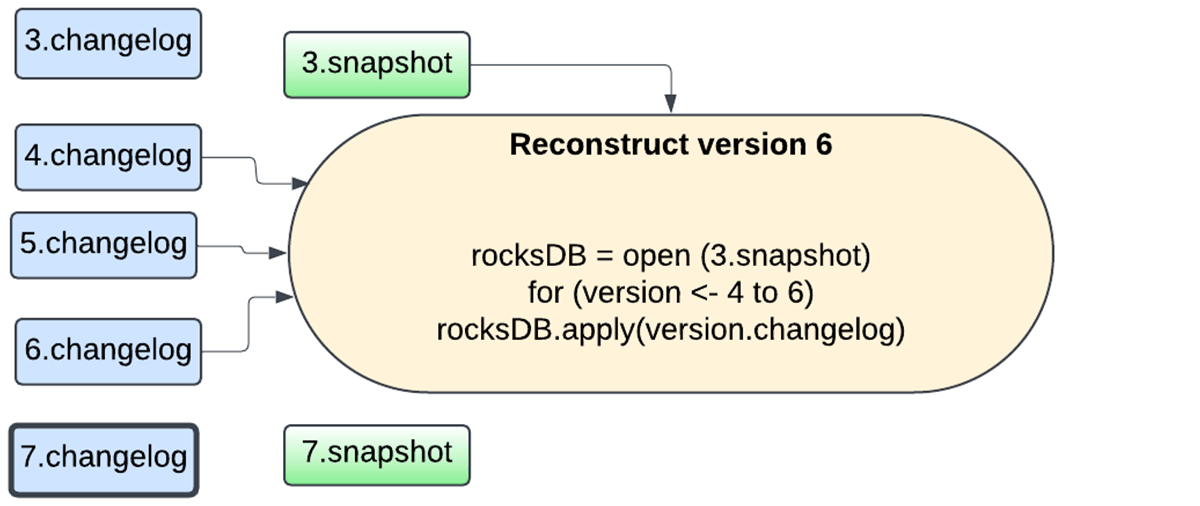
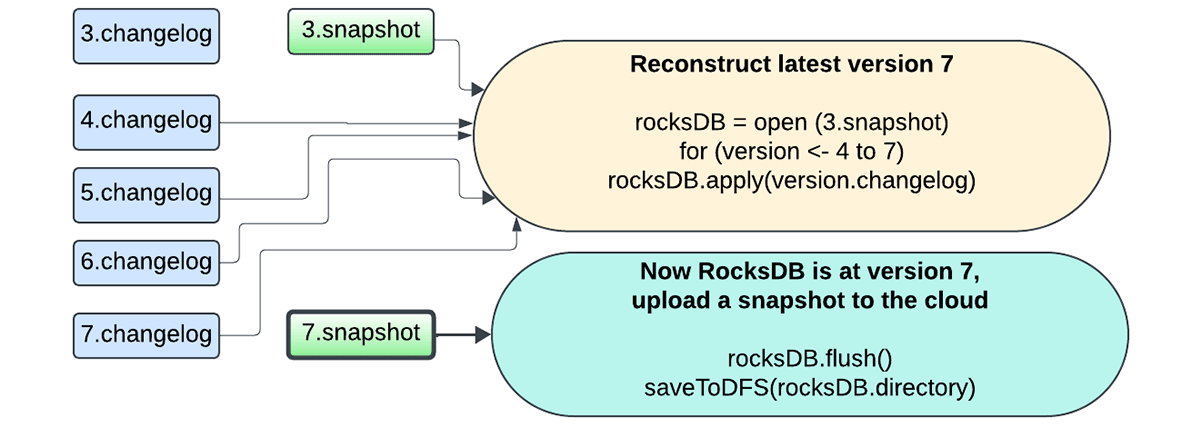
新しい設計では、ステート全体をチェックポイントの場所にスナップショットする必要がなくなりました。 代わりに、現在は変更ログチェックポイント機能を利用しています。これは、マイクロバッチのコミットごとに最後のチェックポイント以降の変更点のみを保存することで、マイクロバッチの状態を永続化するものです。
さらに、スナップショット・プロセスは、更新を実行する同じデータベース・インスタンスによって処理されるようになり、スナップショットは、タスクの実行をブロックしないように、バックグラウンド保守タスクを使用して非同期にアップ��ロードされます。 ユーザーはスナップショットの間隔を柔軟に設定できるようになり、障害回復とリソースの使用量をトレードオフできるようになりました。 スナップショットを選択し、そのスナップショット以降に作成された変更ログを再生することで、どのバージョンの状態も再構築することができます。 これにより、RocksDBステートストア・プロバイダを使った状態のチェックポイントが高速化されます。
以下の一連の図は、新しいメカニズムがどのように機能するかを捉えたものです。
シンク特有の改善
ステートフルオペレーションが完了すると、その状態はコミットを呼び出すことでステートストアに保存されます。 ステートの保存が成功したら、パーティションデータ(エクゼキュータのスライスデータ)をシンクに書き込まなければなりません。 エクゼキュータはドライバの出力コミット・コーディネータと通信し、他のエクゼキュータが同じデータ・スライスの結果をコミットしていないことを確認します。 他の実行者がこのパーティションにコミットしていないことを確認してからでないと、コミットは実行できません。
この実装は、"at-least-once" セマンティクスのみを提供するシンクでは簡単に回避できると判断した、望ましくない RPC 遅延をもたらしました。 新しい実装では、at-least-onceセマンティクスを持つすべてのDataSource V2(DSv2)シンクについて、この同期ステップを削除し、待ち時間の改善につながりました。 エンドツーエンドの "actly-once "パイプラインでは、再生可能なソースとべき等なシンクの組み合わせが使用されることに注意してください。
オペレーター固有のメンテナンスタスクの改善
Project Lightspeedの一環として、ストリーム・ストリーム結合クエリなど、特定のタイプの演算子の改善も行いました。 このようなクエリに対して、パーティションに関連するすべてのインスタンスの状態ストアの並列コミットをサポートするようになり、レイテンシが改善されました。
もう一つの改良点は、主にスナップショットと期限切れ状態のクリーンアップを��担当するバックグラウンドメンテナンスタスクに関するものです。 このタスクが追いつかない場合、大量のデルタ/チェンジログファイルが蓄積され、再生が遅くなる可能性があります。 これを避けるために、現在では、期限切れの状態の削除を並列に実行することをサポートしています。また、スレッドプールの一部としてメンテナンスタスクを実行することで、1つの実行ノードでロードされたすべての状態ストアインスタンスに対応する1つのスレッドがボトルネックにならないようにしています。
まとめ
ステートフルなStructured Streamingパイプラインで、この最新の改良をぜひお試しください。 Project Lightspeedの一環として、私たちはすべてのストリーミング・パイプラインのスループットとレイテンシーを、より低いTCOで改善することに注力しています。 近い将来、この分野でさらなるアップデートがあることをご期待ください!
利用可能なバージョン
上記の機能はすべてDBR 13.3 LTSリリースから利用可能です。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。