Project Lightspeed Update - Apache Spark Structured Streamingの高度化に向けて
Databricksにおけるストリーミング・イノベーションを振り返って
によって Karthik Ramasamy, Michael Armbrust, Matei Zaharia, Reynold Xin(レイノルド・シン), Praveen Gattu, Ray Zhu, Shrikanth Shankar, Awez Syed, Sameer Paranjpye, フランク・ムンツ 、 マット・ジョーンズ による投稿
翻訳:Saki Kitaoka. - Original Blog Link
このブログポストでは、1年前にProject Lightspeedを発表してからのSpark Structured Streamingの進歩について、パフォーマンスの向上からエコシステムの拡張、そしてそれ以降についてレビューします。具体的なイノベーションについて説明する前に、そもそも私たちがProject Lightspeedの必要性に至った背景を少しおさらいしましょう。
本記事の背景
ストリーム処理は、インスタントな洞察とリアルタイムのフィードバックを得るために、企業にとって重要なニーズです。Apache Spark Structured Streamingは、その使いやすさ、パフォーマンス、大規模なエコシステム、開発者コミュニティにより、長年にわたって最も人気のあるオープンソースのストリーミングエンジンです。オープンソースで組織全体に広く採用されており、Delta Live Tables(DLT)やDatabricks Lakehouse Platformのストリーミングを支える中核技術です。
当社の顧客は、ストリーミングデータを使用して、記録的な価格とパフォーマンスで驚くべきことを行っています:
Columbiaは、Databricks上でリアルタイム分析パイプラインを構築し、以前のデータウェアハウスベースのプラットフォームよりも48倍高速なETLワークロードを低コストで実現しました。
AT&T, LaLiga, USDOTは、リアルタイムMLのユースケースをわずかなコストと複雑さで変革しました。
Walgreens社は、BIワークロードをレガシーデータウェアハウスアーキテクチャからSpark Structured Streamingで構築されたリアルタイム分析ソリューションに進化させることで、サプライチェーンコストを数百万ドル削減しました。
Honeywell社とEdmunds社は、SparkとDLTで構築されたより高性能で低コストのETLパイプラインにより、リアルタイムアプリケーションを強化しました。
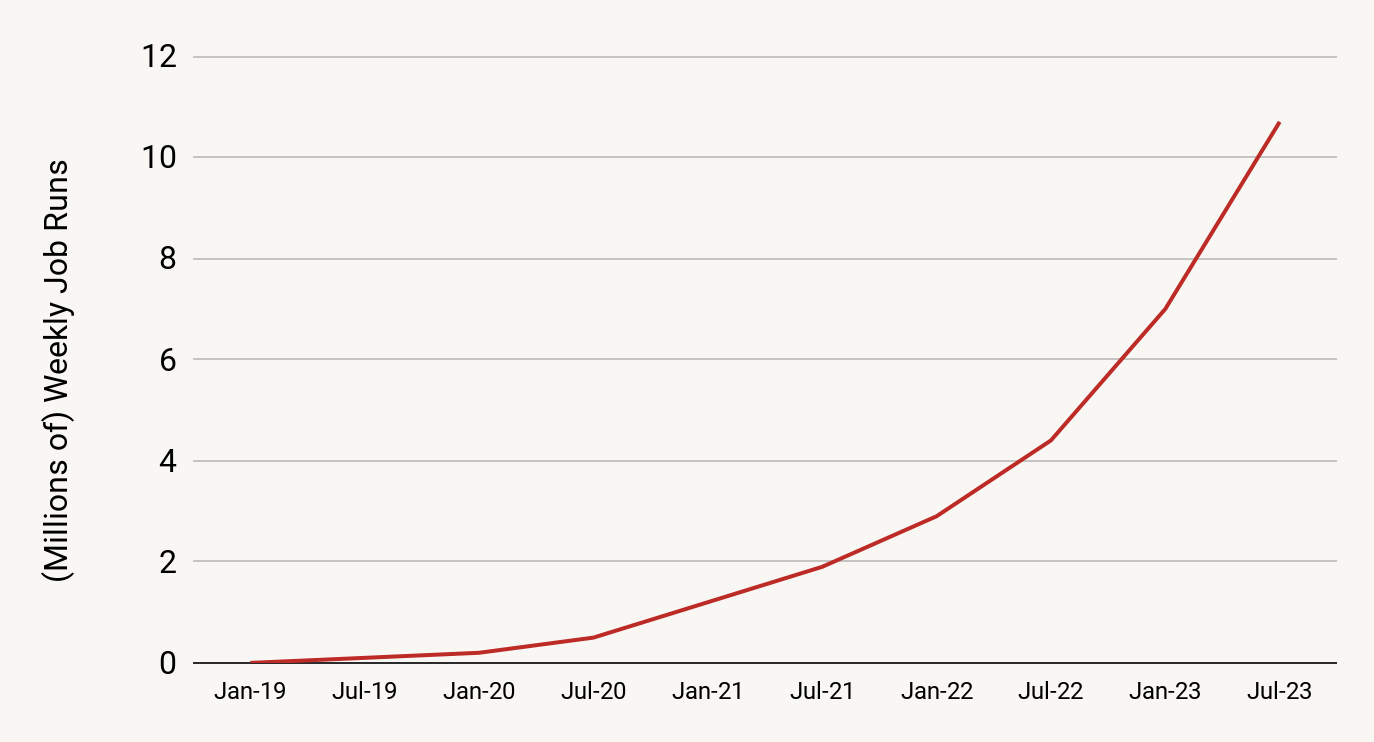
実際、Databricks Lakehouse Platformは、リアルタイムアナリティクス、リアルタイムAIおよびML、リアルタイムアプリケーションを強化するストリーミングデータワークロードとして、何千もの顧客に信頼されています。Databricks上で実行されるストリーミングジョブは週に1,000万を超え、その数は毎年2.5倍以上のペースで増え続けています。これらのジョブは、1日に数ペタバイトのデータ(圧縮データ)を処理しています。
Project Lightspeed
2022年のData+AI Summitで、私たちはApache Sparkを使ったより高速でシンプルなストリーム処理に特化したイニシアチブであるProject Lightspeedを発表しました。Lightspeedは、未来のストリーミングエンジンとしてのSparkと、Sparkワークロードを実行するための最適な場所としてのDatabricks Lakehouse Platformへの協調的な投資を表しており、また、すべてのデータの必然的な未来としてストリーミングデータアーキテクチャを認めています。
Project Lightspeedは、4つの異なる領域で構造化ストリーミングに進歩をもたらしました。これらはすべて、Apache Spark Structured StreamingとDatabricks Runtimeが複雑なリアルタイムデータワークロードの処理をますます向上させることを目的としています。
以下は、Project Lightspeedのここ1年の新機能を領域別にまとめたものです:
この投稿では、Project Lightspeedがこれまでにもたらしたすべての変更点を探ります。新しいレイテンシーの改善から、Amazon KinesisやGoogle Pub/Subのような一般的なメッセージング・システム用の改良されたコネクターまで、すべてをカバーします。
領域 1 - パフォーマンスの向上
Sparkの設計は、高いスループットと使いやすさを低コストで実現する一方で、秒以下のレイテンシには最適化されていませんでした。私たちは、一貫性のあるサブ秒レイテンシーを実現するために、いくつかのテクニックと機能を実装しました。これらの改善は以下の通りです。
Offset の管理
Apache Spark Structured Streamingは、データがどの時点まで処理されたかを追跡するために、オフセットの永続化と管理に依存しています。これは、各マイクロバッチに対して2つの帳簿管理操作に変換されます。
- マイクロバッチの開始時に、ソースシステムから読み込める新しいデータに基づいてオフセットが計算され、offsetLogと呼ばれる耐久性のあるログに永続化されます。
- マイクロバッチの終了時には、このマイクロバッチが正常に処理されたことを示すエントリが commitLog と呼ばれる耐久性のあるログ��に永続化されます。
以前は、これらの操作は両方ともデータ処理のクリティカルパス上で実行され、処理の待ち時間とクラスタの使用率に大きな影響を与えていました。
オフセットを永続化するこのオーバーヘッドに対処するため、Project Lightspeedに非同期の進捗追跡を実装しました。この実装により、Structured Streamingパイプラインは、マイクロバッチ内の実際のデータ処理と並行して、非同期にログを更新することができます。パフォーマンス実験では、100K、500K、1Mイベント/秒のスループットで、レイテンシが700~900ミリ秒から150~250ミリ秒に一貫して3倍削減されました。
Availability - この機能はDBR11.3以降のリリースから利用可能です。
詳細については、以下のブログをご参照ください。
- Apache Spark Structured Streamingでレイテンシが1秒未満になりました
ログのパージ
プログレス・トラッキングのオフセット管理に加えて、以前は Structured Streaming はマイクロバッチごとにクリーンアップ処理を実行していました。このオペレーションは、プログレス・トラッキングの古くて不要なログ・エントリーを削除または切り捨て、これらのログが蓄積されて無制限に増大しないようにします。この操作は、レイテンシに影響を与えるデータの実際の処理とインラインで実行されました。
このオーバーヘッドを除去するために、ログのクリーンアップはProject Lightspeedで非同期にされ、バックグラウンドでゆったりとしたスケジュールで実行され、マイクロバッチごとのレイテ��ンシが削減されました。この改善はすべてのパイプラインとワークロードに適用されるため、すべてのStructured Streamingパイプラインでデフォルトでバックグラウンドで有効になります。当社の性能評価では、100K、500K、1M イベント/秒のスループットでレイテンシが 200~300ms 短縮されました。
Availability - この機能はDBR11.3以降のリリースから利用可能です。
詳細については、以下のブログをご参照ください。
- Apache Spark Structured Streamingでレイテンシが1秒未満になりました
マイクロバッチパイプライニング
ベンチマークのためにStructured Streamingクエリを実行すると、sparkクラスタの使用率が低く、レイテンシが高く、スループットが低いことが観察されました。さらに調査したところ、これはStructured Streamingの基本的な実行メカニズムが原因であることがわかりました:
- ストリーミングクエリで一度に実行できるマイクロバッチは1つのみ
- マイクロバッチの1つのステージだけが一度に実行できるため、ストリーミングクエリではすべてのステージが順次実行されます。
このため、現在のマイクロバッチの1つのタスクの終了に時間がかかると、次のマイクロバッチのタスクの実行のスケジューリングが遅れます。この間、すでに完了したタスクのタスクスロットは利用されないため、待ち時間が長くなり、スループットが低下します。
利用率を向上させ、待ち時間を短縮するために、前のマイクロバッチのタスクが「すべて」終了するのを待つのではなく、前のマイクロバッチのタスクが「それぞれ」終了した直後に次のマイクロバッチのタスクが開始されるように実行メカニズムを変更しました。基本的には、マイクロバッチの実行をパイプライン化するか、多数のマイクロバッチを同時に実行します。
パイプライン実行による性能向上を定量化するためにこれまでに実行したベンチマークでは、スループットとコスト削減において2~3倍の改善が見られました。 さらに多くのベンチマークを実行し、パイプライン実行による性能向上をさらに最適化する予定です。
Availability - この機能は2023年第3四半期にGAされる予定です。
ステートフル・パイプラインの性能に関する考察
予測不可能で一貫性のないパフォーマンス
既存のモデルでは、Structured StreamingパイプラインがRocksDBのステートストア・プロバイダを使用する場合、遅延が大きく変動することがありました。詳細な調査の結果、ステートストアに関連するコミットオペレーションがタスク時間の50-80%に寄与していることが判明しました。以下は、私たちが確認した問題の一部です:
- メモリの増加/使用に関する問題 - RocksDBのステートストア・プロバイダでは、すべての更新がwriteBatchWithIndexを使ってメモリに保存されていました。これは、インスタンス単位で使用量が制限されないだけでなく、単一ノードのステート・ストア・インスタンス全体でグローバルな制限がないことを意味しました。ステートフルなクエリの場合、ステート・ストア・インスタンスの数は通常パーティションの数に比例するため、大きなステートを扱うクエリではメモリ使用�量が急増します。
- データベースの書き込み/フラッシュ関連の速度低下 - コミット操作の一部として、writeBatchWithIndexからデータベースへの書き込みと、同期フラッシュを実行していました。また、SST(Sorted String Table)ファイルの同期とともに、WAL(write-ahead log)へのすべての書き込みを強制していたため、更新が重複していました。また、データベースのスナップショットを取得する前に、バックグラウンドの作業が完了するまで明示的に待機していたため、バックグラウンドのコンパクション/フラッシュ処理に関連する一時停止が発生していました。
- 書き込みの増幅 - 既存のモデルでは、分散ファイルシステムにアップロードされた状態のサイズは、変更された実際の状態データのサイズに比例していませんでした。これは、RocksDBのSSTファイルがLSM(Log Structured Merge)コンパクション中にマージされるためです。そのため、以前のバージョンと比較して変更されたSSTファイルをすべて特定しようとすると、分散ファイルシステムに多くのファイルを同期する必要があり、書き込みが増幅され、ネットワークとストレージのコストが追加されることになります。
より高速で一貫性のあるパフォーマンスに向けて
上述した問題に対処するため、より高速で一貫性のあるパフォーマンスを実現するために多くの改善を行いました。
- メモリ使用量の制限 - メモリの使用量や増加の問題を解決するために、RocksDBの書き込みバッファマネージャ機能を使用することで、ユーザがメモリ使用量の制限を設定できるよう��になりました。これにより、ユーザはブロックキャッシュ、書き込みバッファ、フィルタ/インデックスブロックのメモリ使用量を、ステートストアDBインスタンス全体で制御するための単一のグローバル制限を設定することができます。また、writeBatchWithIndexへの依存を削除し、更新がバッファリングされずに直接データベースに書き込まれるようになりました。
- データベース書き込み関連の改善 - 今回実装した改善により、データベースから直接書き込みと読み取りを行うようになりました。しかし、明示的にWAL(write-ahead log)を必要としないため、今回のケースではこのRocksDBの機能を無効にしています。これにより、すべての読み込み/書き込みを主にメモリから行うことができ、また、変更ログのチェックポイントが有効になっている場合には定期的にフラッシュすることができます。また、スナップショットのキャプチャとアップロードをバックグラウンドのDB操作を中断することなく安全に行うことができるため、バックグラウンド操作を中断することもなくなりました。
- 変更ログチェックポインティング - インクリメンタルチェックポインティングの重要な考え方は、状態全体をチェックポイントの場所にスナップショットする代わりに、変更ログを同期することでマイクロバッチの状態を永続的にすることです。さらに、スナップショットのプロセスは、クリティカルパスのタスク実行をブロックしないように、バックグラウンドタスクにプッシュされます。スナップショットの間隔は、障害回復とリソース使用のトレードオフのために設定することができます。スナップショットを選択し、そのスナップショットの後に作成された変更ログを再生することで、どのバージョンの状態も再構築できます。これにより、RocksDBのステートストア・プロバイダを使った、より高速で効率的な状態のチェックポイントが可能になります。
- その他の改善 - 特定の種類のクエリのパフォーマンスも改善しました。例えば、ストリームストリーム結合クエリでは、パーティションに関連するすべてのステートストアインスタンスに対してステートストア・コミットを並列に実行することができるようになり、全体的なレイテンシが短縮されました。もう1つの最適化は、(Kafkaシンクのような)少なくとも1回のシンクに対して出力コミット・ライターを経由するのをスキップすることです。
Availability - 上記の改善はすべてDBR13.2以降のリリースで利用可能になります。
ステートのリバランシング
Structured Streamingでは、一部のオペレーターはステートフルです(例:mapGroupsWithState)。分散実行では、これらのオペレーターの状態はパーティションにシャーディングされ、マイクロバッチ実行の合間にローカル実行ディスクに保存され、分散ファイルシステムにもチェックポイントされます。通常、1つのスパーク実行タスクが1つのステートパーティションを管理します。現在、デフォルトでは、ステートフルオペレータは200のパーティションにシャーディングされています。
各パーティションに関連付けられたタスクは、アイドル状態のリソースが利用可能かどうかに基づいてランダムに選択されたエクゼキュータ上で初めて実行��されます。その後のマイクロバッチ実行では、タスクスケジューラはステートパーティションタスクを以前に実行した同じエクゼキュータ上でスケジュールすることを好みます(エクゼキュータが死亡したり、ステートフルタスクがある閾値以上の実行を待ち、他のアイドルエクゼキュータに選ばれない限り)。これは、メモリやローカルディスクにキャッシュされた状態の局所性を利用するためです。このような動作は、特に新しいエクゼキュータがクラスタに追加されたときに問題となります(自動スケーリングによる)。そのため、クラスタをスケールアップしてもステートフルなタスクの実行が最適に分散されません。
リソースを効率的に利用するために、私たちはタスクスケジューラに状態リバランシングアルゴリズムを実装し、新しいエクゼキュータが追加または削除されたときに、状態に関連するタスクが利用可能なエクゼキュータに均等に分散されるようにしました。リバランシングアルゴリズムは、最適配置のための状態タスクの最小移動数で収束するため、状態配置のばたつきがないことを保証します。エクゼキュータのセットやパーティション数に変更がないと仮定すると、その後の最適性の再計算では、ステートタスクの移動は発生しません。
Availability - この機能はDBR11.1以降のリリースから利用可能です。
適応的なクエリの実行
Databricks Structured Streamingの顧客の40%以上がForeachBatchシンクを使用しています。通常、ForeachBatchシンクは、結合やDelta Mergeのような、大量のデータを伴うリソース集約的な処理に使用されます。その結果、静的なクエリプランニングと推定��統計量に依存した多段階の実行プランが貧弱な物理的実行戦略となり、歪んだデータ分布の場合にはパフォーマンスが低下していました。
これらの課題を解決するために、ForeachBatchシンクの前のマイクロバッチ実行中に収集された実行時統計量を使用して、後続のマイクロバッチを最適化します。適応的なクエリの再プランニングは、各マイクロバッチで独立してトリガーされます。高価な結合や集約によってボトルネックになっているステートレスクエリに対する性能実験では、1.2倍から2倍のスピードアップを経験しました。
Availability - この機能はDBR13.1以降のリリースから利用可能です。
詳細については、以下のブログをご参照ください。
- 構造化ストリーミングにおける適応的なクエリの実行
領域2 - 機能の強化
企業がより多くのユースケースでストリーミングの利用を拡大するにつれて、ロジックをより簡潔かつネイティブに表現するための機能性が求められています。
そこで、以下のような機能を追加しました。
複数のステートフルオペレーターのサポート
以前は、Structured Streamingのストリーミング・クエリ内で複数のステートフルオペレーターをサポートする機能はありませんでした。例えば、2つのウィンドウ集約を持つストリーミング・クエリはサポートされておらず、正しく実行されませんでした。 これらの制限を回避するために、外部ストレージによって接続された個別のクエリにクエリを分割するなどの回避策がありますが、ユーザー・エクスペリエンス、システム・パフォーマンス、および運用コストの観点から欠点があります。このため、Structured Streamingでは実装が困難な、1つのクエリに複数のステートフルなオペレーターを含む多くの潜在的なユースケースが存在します。
複数のステートフルオペレータがサポートされない理由は、以前のウォーターマークメカニズムが機能する方法に関するいくつかの根本的な問題によるものです。 その中には、壊れたレイトレコードフィルタリングと不十分なイベント時間列追跡がありますが、最も重要なのは、ステートフルなオペレーターごとにウォーターマークを追跡するサポートが欠けていたことです。以前は、ストリーミングクエリーごとに単一の「グローバル」ウォーターマーク値のみが追跡されていました。 このため、1つのウォーターマークでは複数のステートフルオペレータの実行状況を追跡することができないため、複数のステートフルオペレータをサポートすることができませんでした。これらの制限は修正され、ウォーターマークは各状態オペレーターごとに追跡されるようになり、複数の状態オペレーターを持つストリーミング・クエリが正しく実行されるようになりました。
Availability - この機能はDBR13.1以降のリリースから利用可能です。
Pythonでの任意のステートフル処理
ストリーム処理の主な使用例の1つは、入力データに対して連続的な集約を実行することです。例えば、オプション取引では、ユーザーが独自の指数加重移動平均を記述する機能を提供する必要があります。Structured Streaming は、このようなユースケースに対応するために、flatMapGroupsWithState() や mapGroupsWithState()による任意のステートフルな操作を提供します。しかし、この機能はこれまでPySparkでは利用できませんでした。そのため、ユーザーはScalaやJavaに乗り換え、Pandasのような一般的なPythonライブラリで作業できなくなります。
PySparkでは、Structured Streamingで任意のステートフルな操作のサポートを追加することで、このギャップを解消しました。新しい API DataFrame.groupby.applyInPandasWithState を導入し、ユーザが状態を更新する独自の関数を呼び出せるようにしました。
Availability - この機能はDBR11.3以降で利用可能です。
詳細については、以下のブログをご参照ください。
- Python Arbitrary Stateful Processing in Structured Streaming
ウォーターマーク内の重複の削除
以前は、行のイベント時刻情報を含むタイムスタンプ列を dropDuplicates 関数に渡す必要がありました。これは、どのステート情報をクリーンアップするかを決定するウォーターマークを計算するためです。 このイベント時刻列は、行が重複しているかどうかを判断する際にも考慮されます。 ユーザは通常、重複排除処理においてイベント時刻列以外の列も考慮したいため、これはユーザが望む動作ではないことがよくあります。 この問題は、この機能を適切に使用する方法について、ユーザーに混乱を引き起こします。
この問題は、新しい関数 dropDuplicatesWithinWatermark を作成することによって解決されました。この関数を使用すると、ユーザーは、重複排除の目的で考慮したい列とは別に、ウォーターマークに使用するイベント時刻列を宣言することができます。
Protobufシリアライゼーションのネイティブサポート
Structured Streamingにおけるプロトコルバッファ(Protobuf)のネイティブサポートします。この機能強化により、Sparkデータ変換を使用してProtobufデータをシリアライズおよびデシリアライズできます。Sparkは現在、次の2つの関数を公開しています。
from_protobuf() と to_protobuf() です。from_protobuf()関数はバイナリ列を構造体にキャストします。
to_protobuf() は構造体列をバイナリにキャストします。
Availability - この機能は DBR13.0 以降で利用可能です。詳細はドキュメントを参照してください。
領域3 - 観察性の向上
ストリーミング・ジョブは継続的に実行されるため、実運用シナリオでの監視、デバッグ、アラートのためのメトリクスとツールが重要です。観測性を向上させるために、以下の機能を追加しました。
Python クエリーリスナー
Structured Streaming は、以下の機能を提供することで、ストリーミングワークロードの監視の問題に対処します:
- リアルタイムのメトリクスと統計情報を備えた専用 UI(Dedicated UI)
- アラートや外部システムとのダッシュボードのような高度な監視機能を可能にするObservable API
PySparkにはObservable APIがないため、ユーザーはストリーミングクエリにScala APIを使わざるを得ませんでした。Databricks上で実行されるノー��トブックコマンドの70%近くがPythonであることを考えると、Pythonの重要性が増すにつれて、Pythonにこの機能がないことはより重要になってきています。
私たちはObservable APIをPySparkのストリーミングクエリーリスナーで実装し、開発者が外部システムにストリーミングメトリクスを送信できるようにしました。Streaming Query Listenerは抽象クラスで、継承する必要があり、onQueryStarted、onQueryProgress、onQueryTerminatedの全てのメソッドを実装する必要があります。
Availability - この機能は DBR11.0 以降で利用可能です。
詳細については、以下のブログをご参照ください。
- How to Monitor Streaming Queries in PySpark.
領域4 - エコシステムの拡大
クラウドプロバイダーは多くのデータソースとデータシンクを提供しているため、Structured Streamingがそれらからデータを読み込んだり、処理したデータを書き込んだりするのを簡単にする必要があります。この観点から、既存のコネクタを強化し、以下に示す新しいコネクタを追加しました。
Amazon Kinesisの拡張ファンアウト(EFO)サポート
Amazon Kinesisは、共有スループット・コンシューマーと拡張ファンアウト・コンシューマーという2つの異なるタイプのコンシューマーをサポートしています。共有スループットでは、ストリーム内のシャードはシャードごとに2MB/秒の読み取りスループットを提供します。このスループットは、特定のシャードから読み取りを行うすべてのコンシューマーで共有されます。コンシューマが拡張ファンアウトを使用する場合、コンシューマは独自の2MB/秒の読み取りスループットを割り当てられるため、複数のコンシューマが他のコンシューマと読み取りスループットを争うことなく、同じストリームからデータを並行して読み取ることができます。
DatabricksはDBR3.0以降、ストリーミングソースとしてAmazon Kinesisをサポートしています。このソースは、再シャーディング(シャードのマージと分割)のサポートとともに共有コンシューマモデルを使用します。当社のお客様の中には、このコネクターを複数の Structured Streaming ジョブで使用して、1 つの大きな kinesis ストリームからイベントを消費している方がいます。この場合、読み取りスループットが超過してボトルネックになることが多く、処理されるデータが制限され、一貫性のないレイテンシが発生します。2MB/秒のスループットを完全に得るために、複数のStructured Streamingジョブで使用するkinesisストリームをクローンすることもありますが、これは運用上のオーバーヘッドにつながります。この問題を解決するために、Databricks KinesisコネクタにEFOモードのサポートを導入しました。この機能により、ユーザーは必要なスループット、レイテンシ、コストに応じて適切なコンシューマーモードを選択できます。これに加えて、DBR13.1以降のKinesisソースコネクタにTrigger.AvailableNowのサポートが追加されました。詳細はこちらのドキュメントをご覧ください。
Availability - この機能はDBR11.3以降のリリースから利用可能です。
詳細については、以下のブログをご参照ください。
- Announcing Support for Enhanced Fan-Out for Kinesis on Databricks.
Google Pub/Subコネクタ
Google Pub/SubはGoogle Cloudが提供する主要なストリーミング・メッセージ・バスです。Lakehouseプラットフォームを拡張し、GCPのStructured Streamingのお客様に利益をもたらすため、Google Pub/Subソースコネクタをネイティブでサポートすることにしました。しかし、Google Pub/Subは他のメッセージバスと大きく異なります。
- Pubsubにはオフセットがありません - 各メッセージは一意のUUIDである独自のメッセージIDを持っています。
- Pubsubにはオフセットがありません - 各メッセージは一意なUUIDである独自のメッセージIDを持っています。
- メッセージIDでメッセージを取得するAPIはありません。
- 同じサブスクライバで再配信が行われることは保証されていません。
- メッセージは、ACK された後に再配信できます。
- あるサブ��スクライバは、別のサブスクライバに送信されたメッセージを ACK できます。
これらの違いは、Pub/Sub コネクタを開発する上で課題となりました。というのも、データを正確に一度だけ処理するなど、他の Structured Streaming ソースと同様の統一された動作を実現し、フォールトトレランスを提供し、スループットをエクゼキュータの数に応じて線形に拡張したかったからです。Pub/Subからのフェッチをマイクロバッチの実行から切り離すことで、これらの課題を克服しました。これにより、データを個別にフェッチし、重複排除を処理し、独自の決定論的オフセットを作成し、その上にジャストワンス処理ソースを構築できるようになりました。
Google Pub/Subソースコネクタの追加により、Amazon Kinesis、Apache Kafka、Azure EventHub(Kafkaインターフェイス経由)など、主要なクラウドプロバイダーのすべてのストリーミングバスをサポートするようになりました。
Availability - この機能はDBR13.1以降のリリースから利用可能です。
詳細については、以下のブログをご参照ください。
- DatabricksとGoogle Cloudでリアルタイムデータ処理のパワーを解き放つ
まとめ
このブログでは、パフォーマンス、機能性、観測可能性、エコシステムの拡大など、様々な側面からApache Spark Structured Streamingを推進するProject Lightspeedの最新情報を提供しました。現在もProject Lightspeedの実行を継続しており、近い将来さらなる発表があることを期待しています。
当社のお客様がSpark Structured StreamingとDatabricks Lakehouse Platformを使ってストリーミングデータアーキテクチャをどのように運用しているかは、こちらをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。