ノートブックでシンプルに!DLTパイプライン開発
公開日: June 25, 2024
によって Zoé Durand、ドミニク・クレイマー、プラディープ・ゴパナパリ・ヴェンカタ、ディラン・スティール、ジュリア・マーティン による投稿
史上最大規模のData + AI Summitが開催されてからわずか数週間が経ちました。このサミットでは、データエンジニアリングのための統合されたインテリジェントなソリューションであるDatabricks LakeFlowを紹介しました。 Databricksのデータエンジニアリングのこの戦略的方向性に非常に興奮していますが、現在もユーザー向けの製品エクスペリエンスへの投資も続けています��。
DLT 開発エクスペリエンスの向上は、DLT を使用してデータパイプラインを構築する開発者の効率と満足度に直接影響するため、中心的な焦点となっています。 ノートブックを使用した DLT 開発エクスペリエンスにいくつかの機能強化が加えられたことをお知らせします。 これらの新機能は、シームレスで直感的な DLT 開発インターフェースを提供し、パイプラインを迅速かつ効率的に構築およびデバッグするのに役立ちます。
Delta Live Tables (DLT) は、信頼性の高いデータパイプラインの構築、テスト、保守を簡素化および高速化する革新的なフレームワークです。 宣言型データエンジニアリングと自動パイプライン管理を提供し、依存関係の追跡、エラー回復、モニタリングを処理しながら、ユーザーがビジネスロジックの定義に集中できるようにします。 この強力なツールは、データ操作を効率よく正確に最適化し、データサイエンティストやアナリストが常に最新の高品質データにアクセスできるようにすることを目標とする組織にとって画期的なツールです。
この新しいリリースでは、ノートブックを使用した DLT 開発エクスペリエンスに、次のようなエキサイティングな新機能が追加されます。
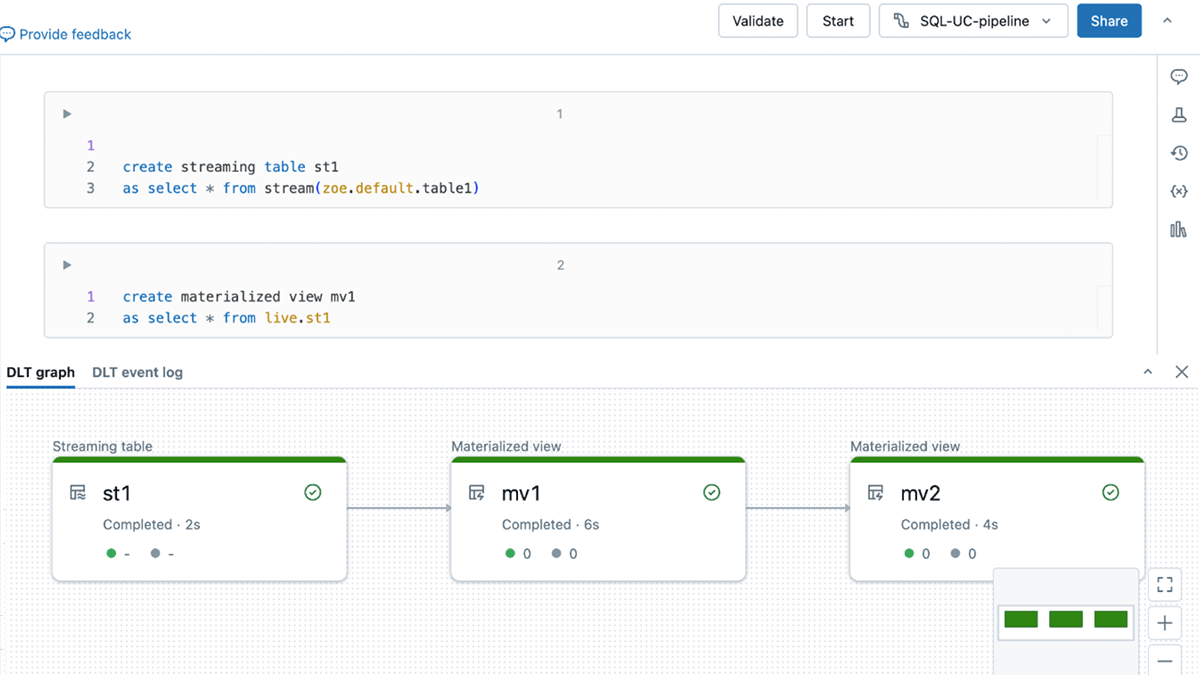
- コンテキストの切り替えはもう必要ありません。DLT グラフ、イベント ログ、ノートブック コードを 1 つのコンテキスト UI で表示します。
- 新しい「検証」アクションで構文エラーをすばやく見つけます。
- DLT固有のオートコンプリート、インラインエラー、診断により、コードをより簡単に開発できます。
コンテキストの切り替えはもう不要: 単一のコンテキストUIでDLTパイプラインを開発
これで、 SQLウェアハウスやインタラクティブ クラスターに接続するのと同じように、データベースから DLT パイプラインに直接「接続」できるようになりました。
DLT パイプラインに接続すると、新しいオールインワン UI にアクセスできるようになります。 DLT グラフ (有向非巡回グラフ (DAG) とも呼ばれます) と DLT イベント ログは、編集中のコードと同じ UI で確認できます。
この新しいオールインワン UI を使用すると、タブを切り替えることなく必要な作業をすべて実行できます。 開発中にDLTグラフの形状と各テーブルのスキーマをチェックして、必要な結果が得られていることを確認できます。 また、開発プロセス中に発生したエラーをイベントログで確認することもできます。
これにより、DLT パイプラインの開発の使いやすさと人間工学が大幅に向上します。
エラーをより迅速に検出し、DLTコードを簡単に開発
1. 「Validate」で構文エラーをすばやくキャッチ
DLT パイプラインの「開始」および「完全更新」に加えて、「検証(Validate)」アクションを導入しています。
「検証」を使用すると、データを処理せずにパイプラインのソース コードの問題をチェックできます。 この機能を使用すると、パイプラインの開発中またはテスト中に、テーブル名や列名の誤りなど、パイプライン内のエラーを繰り返し検出して修正できます。
「検証」はノートブック UI のボタンとして使用でき、「Shift + Enter」キーボード ショートカットを押したときにも実行されます。
2. DLT対応のオートコンプリート、インラインエラー、診断により、コードの開発がより簡単
DLT固有のオートコンプリートにアクセスできるようになり、コードの記述がより速く、より正確になりました。
さらに、コード内の正確なエラー位置を強調する赤い波線で構文エラーを簡単に識別できます。
最後に、インライン診断ボックスを使用すると、関連するエラーの詳細と提案が適切な行番号に表示されます。 エラーの上にマウスを置くと詳細情報が表示されます。
はじめに
DLT パイプラインとデータベースを作成し、コンピュート ドロップダウンからパイプラインに接続するだけです。 これらの新しいノートブック機能は、Azure、AWS、GCPでお試す頂けます。

