Snowplowでデータチームを強化:ファーストパーティデジタルイベントデータ収集の新時代

公開日: 2024年5月31日
によって コナー・ドイル、マイク・ロビンス、ランディ・ウェールズ、ジェニー・ズー 、 ブライアン・スミス(Bryan Smith) による投稿
顧客とのやり取りがますますデジタル領域に移行するにつれて、組織がオンライン顧客行動に関する知見を開発することがますます重要になります。 これまで、多くの組織はサードパーティのデータ収集業者に依存していましたが、プライバシーに関する懸念の高まり、データへのよりタイムリーなアクセスの必要性、カスタマイズされた情報収集の要件により、多くの組織がこの機能の社内への移行を進めています。 Snowplowなどの顧客データ インフラストラクチャ (CDI) プラットフォームとDatabricksのリアルタイム データ処理および予測機能を組み合わせることで、これらの組織は、より深く、よ�り豊富で、よりタイムリーで、よりプライバシーに配慮した知見を開発し、オンライン顧客エンゲージメントの可能性を最大限に引き出すことができます (図 1)。
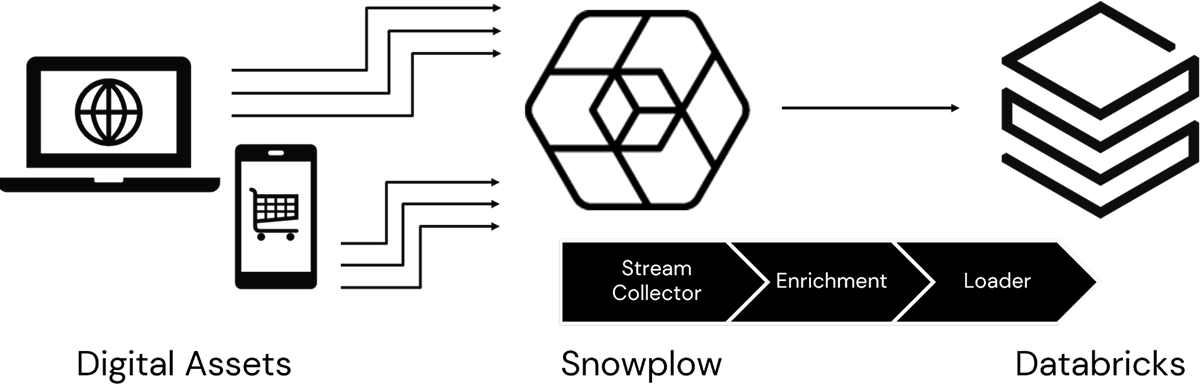
ただし、このデータの可能性を最大限に引き出すには、これらのデータがサードパーティのインフラストラクチャを介して流れていたときには行わなかった方法で、デジタル チームが組織のデータ エンジニアやデータサイエンティストと提携する必要があります。 Snowplow CDI によってキャプチャされ、Databricks Data Intelligence Platform を通じてアクセス可能になるデータをデータ プロフェッショナルに詳しく知ってもらうために、デジタル イベント データがどのように生成され、このアーキテクチャを流れ、最終的にオンライン エクスペリエンスを変革できるさまざまなシナリオを実現できるかを調べます。
イベント生成の理解
ユーザーがオンライン ページを開いたり、スクロールしたり、マウスを移動したり、クリックしたりすると、ページに埋め込まれたコード スニペット (タグと呼ばれる) がトリガーされます。 ここで概説されているさまざまなメカニズムを通じてこれらのページに統合されたこれらのタグは、組織のデジタル インフラストラクチャで実行されている Snowplow アプリケーションのインスタンスを呼び出すように構成されています。 Snowplow は、受信したリクエストごとに、ユーザー、ページ、呼び出しをトリガーしたアクションに関する幅広い情報を取得し、これを大容量で低遅延のストリーム取り込みメカニズムに記録します。
の ストリーム コレクター 機能によって AzureEvent Hubs、AWSKinesis 、GCP PubSub、または に記録されるこのデータは、ユーザー アクションの基本要素をキャプチャします。ApacheKafkaSnowplow
- ipAddress:イベントをトリガーしたユーザーデバイスのIPアドレス
- timestamp: イベントに関連付けられた日時
- userAgent: 使用されているアプリケーション(通常はブラウザ)を識別する文字列
- path: 操作されているサイト上のページのパス
- クエリ文字列: HTTP ページリクエストに関連付けられた HTTP クエリ文字列
- 本文: イベントデータを表すペイロード。通常はJSON形式です。
- headers: HTTP ページ要求で送信されるヘッダー
- contentType: 要求されたアセットに関連付けられた HTTP コンテンツタイプ
- エンコーディング: Snowplow に送信されるデータに関連付けられたエンコーディング
- コレクター: イベント収集中に使用されるストリームコレクターのバージョン
- ホスト名: イ�ベントが発生したソースシステムの名前
- networkUserId: ユーザーの Cookie ベースの識別子
- schema: 送信されるイベントペイロードに関連付けられたスキーマ
イベントデータへのアクセス
ストリーミング データ ソースを構成し Tables (または高度なシナリオ Delta Live Tablesでは構造化ストリーミング) を使用して適切なデータ処理パイプラインを設定することで、ストリーム コレクターによってキャプチャされたイベントDatabricks データに から直接 アクセスできます 。とはいえ、ほとんどの組織は、 Snowplowアプリケーションの組み込みEnrichment プロセスを利用して、各イベント レコードで利用可能な情報を拡張することを好むでしょう。
エンリッチメントでは、 追加のプロパティ が各イベント レコードに追加されます。 このプロセスに対して追加のエンリッチメントを構成して、Snowplow にさらに複雑な検索とデコードを実��行するように指示し、各レコードで利用できる情報をさらに広げることができます。
このエンリッチデータは、 Snowplowによってストリーム取り込みレイヤーに書き込まれます。 そこから、データエンジニアは独自に設計したストリーミング ワークフローを使用してデータを Datbricks に読み込むことができますが、 Snowplowでは、いくつかのSnowplow Loader ユーティリティを利用することで、データの読み込みプロセスが大幅に簡素化されています。 この目的には多くの Loader ユーティリティを使用できますが、ほとんどのデータ エンジニアが使用する LoaderDelta Lake は Lake LoaderDatabricks Databricksです。これは、 環境内で推奨される高性能 形式でデータを取得し、 管理者によるコンピュート キャパシティの割り当てを必要とせず、データの読み込みコストを最小限に抑えることができるためです。
ガートナー®: Databricks、クラウドデータベースのリーダー

イベントデータの操作
どの Loader ユーティリティが使用されているかに関係なく、 Databricksに公開されたエンリッチデータは、 atomic.eventsという名前のテーブルを通じてアクセス可能になります。 この表は、Snowplow によって収集されたすべてのイベント データの統合ビューを表し、さまざまな形式の分析の出発点として使用できます。
そうは言っても、Snowplow のスタッフは、イベント データが使用される一般的なシナリオが多数あることを認識しています。 これらのデータをより直接的にシナリオに合わせるために、Snowplow 一連のdbt パッケージ を提供しており、データエンジニアはこれを使用して、 内に デプロイ可能 で、次のニーズに合わせた軽量データ処理パイプラインをセットアップできます Databricks(図 2)。
- 統合デジタル: ページや画面の閲覧、セッション、ユーザー、同意に関するウェブおよびモバイル データをモデル化します。
- Media Player: 再生統計のメディア要素をモデル化します。
- 電子商取引: カート、製品、チェックアウト、トランザクションにわたる電子商取引のやり取りをモデル化します
- アトリビューション: Snowplow 内のアトリビューション モデリングに使用されます
- 正規化: すべてのSnowplowイベントデータの正規化された表現を構築するために使用されます
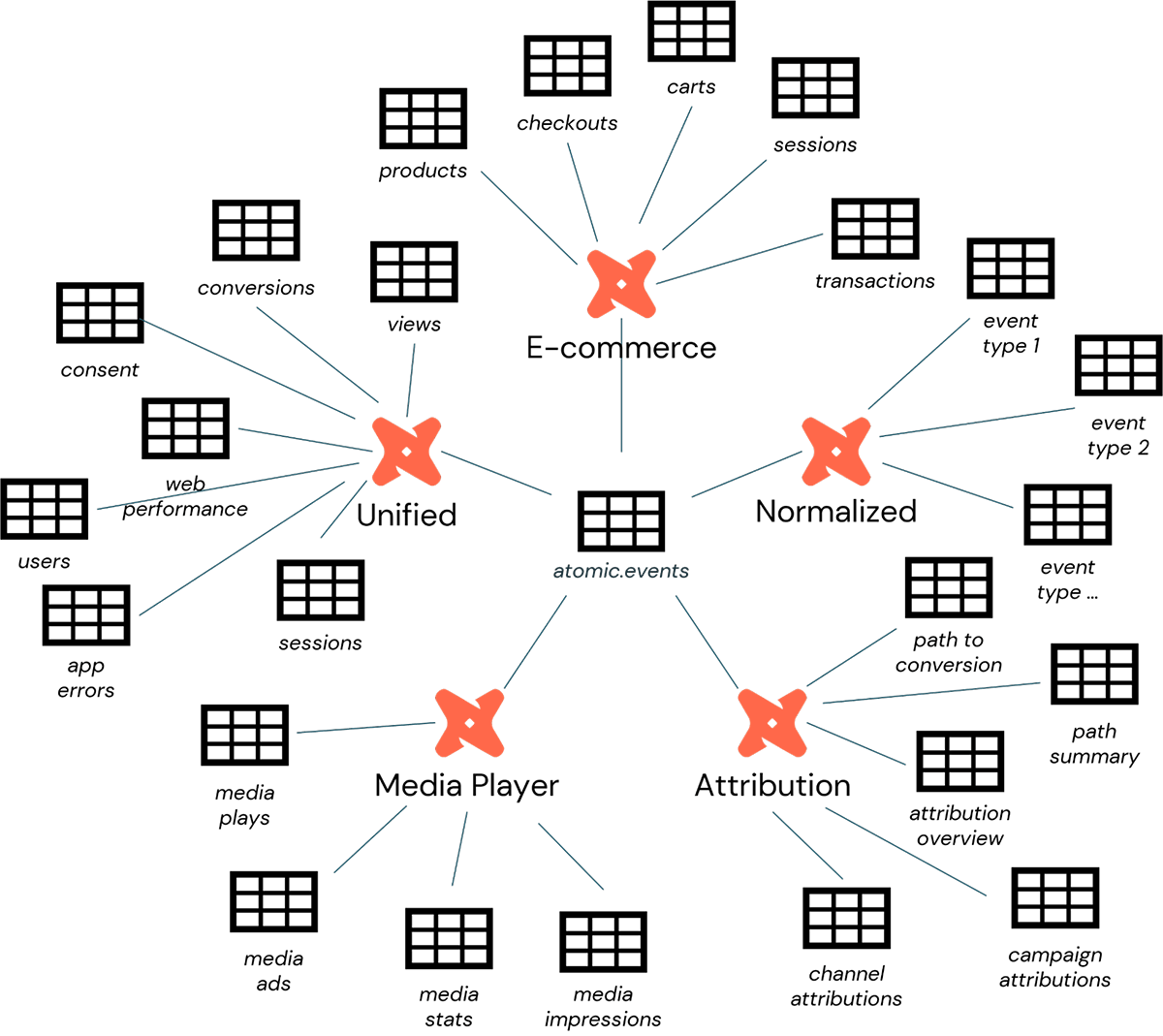
dbt、Snowplow パッケージに加えて、ビデオやメディア、モバイル、Web サイトのパフォーマンス、同意データなどの分析とモニタリングをこのデータから簡単に収集する方法を示す多数の 製品アクセラレー��タ も提供しています。
これらのプロセスの結果は、ほとんどのデータエンジニアに馴染みのある古典的なメダリオンアーキテクチャです。 atomic.eventsテーブルは、このアーキテクチャのシルバーレイヤーを表し、基本イベント データへのアクセスを提供します。 Snowplowが提供する各dbtパッケージおよび製品アクセラレータに関連付けられたさまざまなテーブルは、ゴールドレイヤーを表し、よりビジネスに適した情報へのアクセスを提供します。
イベントデータから知見を抽出する
Snowplowが提供するイベント データの幅広さにより、幅広いレポート、モニタリング、探索のシナリオが可能になります。 Databricks を介して企業に公開されると、アナリストはインタラクティブなダッシュボードやオンデマンド (およびスケジュールされた) クエリなどの組み込みの Databricks インターフェイスを通じてこのデータにアクセスできます。 また、複数のSnowplow データ アプリケーション(図 3) と、 TableauやPowerBIなどの幅広いサードパーティ ツールを採用して、環境内に取り込まれたデータを活用することもできます。
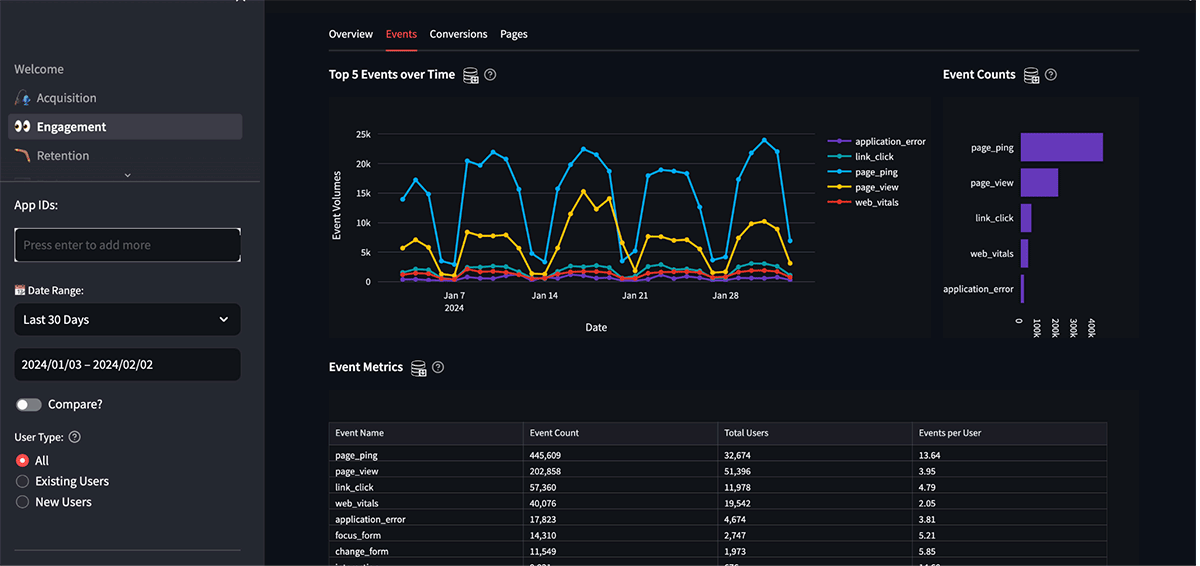
しかし、 data scientistsからより深く将来を見据えた予測的な知見を引き出すことができるようになると、このデータの本当の可能性が解き放たれます。 よく検討される一般的なシナリオには、次のようなものがあります。
- マーケティング アトリビューション: 顧客獲得とコンバージョンを促進しているデジタル キャンペーン、チャネル、タッチポイントを特定します。
- Eコマースファネル アナリティクス: サイト内での顧客の購入までの経路を調査し、ボトルネックや放棄ポイント、コンバージョンまでの時間を短縮する機会を特定します。
- 検索アナリティクス: 顧客を希望する製品やコンテンツに誘導する検索機能の有効性を評価します
- 実験 アナリティクス: 新しい製品、コンテンツ、機能に対する顧客の反応を�厳密に評価し、サイトの機能強化が意図した結果につながるようにします。
- 傾向スコアリング: リアルタイムのユーザー行動を分析して、ユーザーの購入完了の意図を明らかにします。
- リアルタイム セグメンテーション: リアルタイム インタラクションを使用して、ユーザーの意図や好みに最も合った製品やコンテンツにユーザーを誘導します。
- クロスセルとアップセル: 製品の閲覧と購入に関する知見を活用して代替品や追加品を推奨し、購入による収益と利益の可能性を最大化します。
- 次善のオファー: 買い物客の状況を調べて、どのオファーやプロモーションが顧客に購入を完了させたり、カートのサイズを大きくしたりする可能性が最も高いかを特定します。
- 不正検出:不正購入に関連する異常な動作やパターンを特定し、商品が出荷される前に取引にフラグを立てます
- デマンドセンシング:行動データを使用して、消費者の需要に関する期待を調整し、在庫と進行中の注文を最適化します
このリストは、組織が通常このデータを使用して実行する分析の種類のほんの一部にすぎません。 これらを実現するための鍵となるのは、 Snowplowが提供する拡張デジタル イベント データへのタイムリーなアクセスと、 Databricksのリアルタイムデータ処理および機械学習推論機能の組み合わせです。 これら 2 つのプラットフォームを組み合わせることで、より多くの組織がデジタル アナリティクスを社内に導入し、成果につながる強化された顧客エクスペリエンスを実現できるようになります。 組織で同じことを行う方法の詳細については、こちら からお問い合わせください 。
読者に次のステップを案内します。詳細な情報を得るために関連コンテンツを提案し、マーケティング ファネルに沿って読者を動かすためのリソースを提供します。