Delta Live Tablesを使用してフルテーブルスナップショットからの変更データキャプチャ(CDC)を実行する方法
によって Mojgan Mazouchi 、 ガネーシュ・チャンド による投稿
すべてのコードはこのGitHubリポジトリで利用可能です。
このブログを読む前に、Delta Live Tablesの始め方とDatabricks Delta Live Tablesで変更データキャプチャを簡素化するを読むことをお勧めします。これらの記事では、Delta Live Tables(DLT)の宣言的なETL定義とステートメントを使用して、スケーラブルで信頼性の高いパイプラインを作成する方法について説明しています。
イントロダクション
Oracle、MySQL、またはデータウェア�ハウスなどの外部リレーショナルデータベースからDatabricksデータインテリジェンスプラットフォームへのデータの同期は、一般的なユースケースです。Databricksは、LakeFlow Connectのシンプルで効率的な取り込みコネクタから、変更データキャプチャ(CDC)入力データセットを受け入れるDelta Live Tables(DLT)の柔軟性を持つAPPLY CHANGES INTOステートメントまで、さまざまなアプローチを提供しています。 以前、「Databricks Delta Live Tablesで変更データキャプチャを簡素化する」で、DLTパイプラインがどのようにスケーラブルで信頼性の高い低遅延データパイプラインを開発し、最小限の計算リソースと自動的な順序外データ処理でデータレイク内のCDC処理を実行できるようにするかを説明しました。
しかし、LakeFlow ConnectとDLT APPLY CHANGES INTOは、変更データフィード(CDF)をストリームとして提供できるデータベースとシームレスに連携しますが、CDFストリームが利用できない環境やシステムも存在します。これらのソースでは、スナップショットを比較して変更を識別し、それらを処理することができます。このブログでは、テーブルスナップショットを使用してDatabricks Delta Live TablesでSCDタイプ1とSCDタイプ2を実装する方法をご紹介します。
徐々に変化する次元を理解する
時間経過による特定の次元でのデータの予測不能で散発的な変化を、ゆっくりと変化する次元(SCD)と呼びます。これらの変更は、データのエラー��を修正する結果であったり、顧客の位置情報や製品の詳細情報など、特定の次元での真の更新と値の変更を表すことがあります。典型的な例は、顧客が引っ越して住所を変更する場合です。
データを扱う際には、変更が正確に反映され、データの一貫性が損なわれないようにすることが重要です。新しい値で古い値を上書きするか、変更をキャプチャしながら履歴レコードを保持するかという決定は、あなたのデータパイプラインとビジネスプロセスに大きな影響を与える可能性があります。この決定は、あなたの特定のビジネス要件に大きく依存します。異なるユースケースに対応するために、Slowly Changing Dimensions(SCD)にはさまざまなタイプがあります。このブログでは、最も一般的な2つに焦点を当てます:新しいデータで次元が上書きされるSCDタイプ1と、新旧のレコードが時間をかけて保持されるSCDタイプ2です。
スナップショットとは何で、なぜ重要なのでしょうか?
スナップショットは、特定の時点でのデータの安定したビューを表し、テーブルレベルまたはファイルレベルで明示的または暗黙的にタイムスタンプを付けることができます。これらのタイムスタンプにより、時間データの維持が可能になります。時間をかけて一連のスナップショットを取ることで、ビジネスの歴史を包括的に把握することができます。
レコードの履歴を追跡せずに、古いレコードに基づいた分析レポートを作成すると、そのレポートは不正確であり、ビジネスに誤解を与える可能性があります。したがって、データウェアハウスでは次元の変更を正確に追跡することが重要です。これらの変更は予測不可能ですが、スナップショットを比較することで、時間経過に伴う変更を直感的に追跡し、最新のデータに基づいた正確なレポートを作成することができます。
RDBMSテーブルスナップショット管理の効率的な戦略:Push vs. Pull
Push-Based Snapshots: 直接的で効率的
プッシュベースのアプローチは、テーブルの全内容を直接コピーし、このコピーを別の場所に保存することを含みます。この方法は、データベースベンダー固有のテーブルレプリケーションやバルク操作を使用して実装することができます。ここでの主な利点は、その直接性と効率性です。あなたがユーザーとしてプロセスを開始し、データの即時かつ完全な複製が行われます。
プルベースのスナップショット:柔軟性があるがリソースが集中する
一方、Pull-Basedアプローチでは、ソーステーブルの全内容を取得するためにクエリを実行する必要があります。これは通常、DatabricksからのJDBC接続を介して行われ、取得したデータはスナップショットとして保存されます。この方法は、データの取得時期や方法についてより柔軟性を提供しますが、コストがかかる可能性があり、非常に大きなテーブルサイズではスケールしないかもしれません。
これらのスナップショットの複数バージョンを扱う際の主な戦略は2つあります:
スナップショットの置換アプローチ(アプローチ1):この戦略は、スナップショットの最新バージョンのみを維持することに関しています。新しいスナップショットが利用可能になると、古いものと置き換えられます。このアプローチは、最新のデータスナップショットのみが関連するシナリオに最適�で、ストレージコストを削減し、データ管理を簡素化します。
スナップショット蓄積アプローチ(アプローチ2):リプレースメントアプローチとは逆に、ここではテーブルスナップショットの複数のバージョンを保持します。各スナップショットは一意のパスに保存され、過去のデータ分析や時間経過に伴う変更の追跡が可能です。この方法はより豊かな歴史的な文脈を提供しますが、より多くのストレージとより複雑なシステム管理を必要とします。
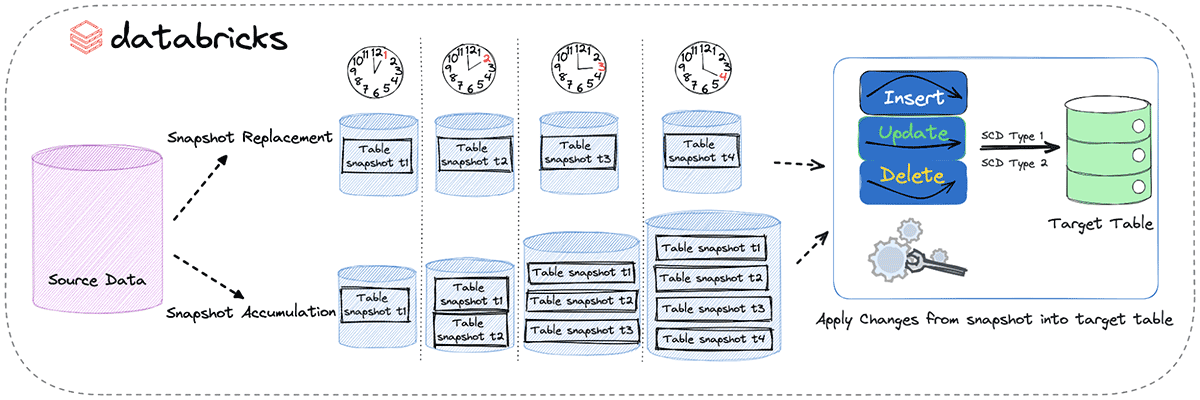
Delta Live Tablesの紹介 スナップショットからの変更の適用
DLTには"APPLY CHANGES FROM SNAPSHOT"という機能があり、これによりデータを一連のフルスナップショットから増分的に読み取ることができます。フルスナップショットには、すべてのレコードとそれに対応する状態が含まれており、その瞬間のデータの包括的なビューを提供します。APPLY CHANGES FROM SNAPSHOTステートメントを使用すると、ソースデータベースのフルスナップショットを使用して、外部RDBMSソースをDatabricksプラットフォームにシームレスに同期することができます。
APPLY CHANGES FROM SNAPSHOTは、シンプルで宣言的な構文を提供し、順序付けされた一連のスナップショットを比較することでソースデータに対する変更を効率的に判断し、ユーザーが簡単にCDCロジックを宣言し、SCDタイプ1または2として履歴を追跡できるようにします。
この新機能を使用する例を詳しく見ていく前に、DLTでこの新機能を活用する前にユーザーが確認すべき要件と注意点を見てみましょう:
- この機能はPythonのみをサポートしています。
- この機能は、サーバーレスのDLTパイプラインと、ProおよびAdvanced製品エディションの非サーバーレスDLTパイプラインでサポートされています。
- ステートメントに渡されるスナップショットは、バージョン順に昇順でなければなりません。
- APPLY CHANGES FROM SNAPSHOTステートメントのスナップショットバージョンパラメータは、ソート可能なデータ型でなければなりません(例えば、文字列と数値型)。
- SCDタイプ1とSCDタイプ2の両方の方法がサポートされています。
このブログに従って、APPLY CHANGES FROM SNAPSHOT文を活用し、Hive MetastoreとUnity Catalogの両環境でスナップショットの置き換えまたは蓄積アプローチを実装することができます。
あなたのソーステーブルを定義する
この概念をオンラインショッピングを例に探ってみましょう。オンラインショッピングをすると、アイテムの価格は供給と需要の変動により変動することがあります。あなたの注文は配達前にいくつかの段階を経て、価格が下がったアイテムを返品して再注文することがあります。小売業者は、このデータを追跡することで利益を得ることができます。それは彼らが在庫を管理し、顧客の期待に応え、販売目標と調整するのに役立ちます。
最初のアプローチ(スナップショット置換アプローチ)を使用�したオンラインショッピングの例を示すために、ストレージロケーションに保存された完全なスナップショットデータを使用し、新しい完全なスナップショットが利用可能になると、既存のスナップショットを新しいものに置き換えます。二つ目のアプローチ(スナップショット蓄積アプローチ)では、毎時の全データスナップショットに依存します。新しいスナップショットが利用可能になるたびに、新たに到着したデータを既存のすべてのスナップショットを保存しているストレージ場所に書き込みます。データロードの頻度のスナップショットは、スナップショットの処理に必要な頻度に設定できます。スナップショットの処理頻度を増減する必要があるかもしれません。ここでは簡単のため、毎時の全スナップショットを選択します。つまり、毎時にレコードの最新の更新がすべてコピーされ、その対応する時間にストレージ場所にロードされ保存されます。以下は、私たちの毎時フルスナップショットが管理されたUnity Catalog Volumesにどのように保存されているかの例です。

下記の表は、フルスナップショットの例として保存されたレコードを表しています:
| order_id | 価格 | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | 再注文 | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | 配送 | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | 配送済 | 2023-10-04 01:07:35 | 10706 | 2005 |
| … | … | … | … | … | … |
スナップショットデータを作成するときは、データの各レコードに対してプライマリキーを持ち、各スナップショット内のすべてのレコードに適用される単一のタイムスタンプまたはバージョン番号を持つ必要があります。これにより、取り込まれた一連のスナップショットの変更順序を簡単に追跡することができます。この日次スナップショットの例では、order_idが主キーとして機能します。スナップショットをストレージ場所にロードする際の日付がファイル名に使用され、特定の日付のスナップショットにアクセスできるようになり、これらの日付ベースのファイル名に依存して連続するスナップショット間の変更を追跡します。
この例のために、先ほど述べたテーブルのフィールドを使用してサンプルデータセットを作成しました。更新操作を示すために、既存の注文のorder_statusを'pending'から'shipping'、'delivered'、または'cancelled'に変更します。��挿入を示すために、一意のorder_idsを持つ新しい注文を追加します。最後に、削除の動作を示すために、既存の注文からランダムに少数を削除します。このアプローチは、すべての主要な操作:INSERT、UPDATE、DELETEを含む包括的な例を提供します。このブログで使用されたすべてのノートブック、データジェネレーターを含めて、ここで見つけることができます。処理手順と結果は、以下のセクションで示されています。
フルスナップショットからのCDCデータを処理するDLTパイプラインの実装
"APPLY CHANGES FROM SNAPSHOT"を活用するためには、APPLY CHANGES INTOと同様に、まず時間経過によるレコード変更をキャプチャーして保存するために使用されるターゲットストリーミングテーブルを作成する必要があります。下記のコードは、ターゲットストリーミングテーブルを作成する例です。
ターゲットストリーミングテーブルができたので、APPLY CHANGES FROM SNAPSHOTステートメントをより詳しく調べ、スナップショットデータを効果的に処理するために必要な引数を調べることができます。アプローチ1では、既存のスナップショットが定期的に新しいスナップショットに置き換えられるとき、apply_changes_from_snapshot Python関数はソーステーブルから新しいスナップショットを読み込み、ターゲットテーブルに保存します。
SNAPSHOTからの変更の適用は、「keys」引数の指定が必要です。"keys"引数は、スナップショットデータの行を一意に識別する列または列の組み合わせを参照する必要があります。これは、新しいスナップショットで変更があった行を識別するための一意の識別子です。例えば、私たちのオンラインショッピングの例では、「order_id」は主キーであり、更新、削除、または挿入された注文の一意の識別子です。したがって、後のステートメントでorder_idをkeys引数に渡します。
別の必要な引数はstored_as_scd_typeです。stored_as_scd_type引数を使用すると、ユーザーはターゲットテーブルのレコードをSCD TYPE 1またはSCD Type 2としてどのように保存するかを指定できます。
アプローチ2では、スナップショットが時間をかけて蓄積され、既存のスナップショットのリストがすでにある場合、ソース引数を使用する代わりに、snapshot_and_versionという別の引数を指定する必要があります。スナップショットのバージョンは、各スナップショットに対して明示的に提供する必要があります。このsnapshot_and_version引数は、ラムダ関数を取ります。この引数にラムダ関数を渡すと、関数は最新の処理済みスナップショットバージョンを引数として取ります。
Lambda関数: lambda Any => Optional[(DataFrame, Any)]
戻り値: Noneまたは2つの値のタプルのいずれかになります。
- 返されるタプルの最初の値は、処理される新しいスナップショットDataFrameです。
- 返されるタプルの2番目の値は、スナップショットの論理的な順序を表すスナップショットバージョンです。
apply_changes_from_snapshotパイプラインがトリガーされるたびに、以下の操作を行います:
- snapshot_and_version lambda関数を実行して、次のスナップショットDataFrameと対応するスナップショットバージョンをロードします。
- DataFrameの戻り値がない場合、実行を終了し、更新を完了とマークします。
- 新しいスナップショットによって導入された変更を検出し、それらを目標に対して増分的に適用します。
- 最初のステップ(#1)に戻って、次のスナップショットとそのバージョンをロードします。
上記の議論は、スナップショットからの変更の適用の必須フィールドですが、他のオプションの引数、例えばtrack_history_column_listやtrack_history_except_column_listは、ユーザーが必要に応じてターゲットテーブルの表現をカスタマイズするためのより大きな柔軟性を提供します。
オンラインショッピングの例に戻って、この機能がどのように動作するかを[table 1]から合成的に生成されたデータを使用して詳しく見てみましょう:最初の実行から始めて、初期のスナップショットが存在しない場合、私たちは注文データを生成してアプローチ1の場合には最初のスナップショットテーブルを作成し、またはアプローチ2の場合には生成された初期のスナップショットデータを定義されたストレージロケーションパスに管理されたUnity Catalogボリュームを使用して保存します。アプローチに関係なく、生成されたデータは以下のようになります:
| order_id | 価格 | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | 再注文 | 2023-09-16 13:59:15 | 17127 | 2058 |
| 2 | 24 | 返却済 | 2023-09-13 15:52:53 | 16334 | 2047 |
| 3 | 13 | 配送済 | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | キャンセル | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | 配送中 | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | 配送済 | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | 保留中 | 2023-09-15 03:22:52 | 10488 | 2033 |
| 8 | 23 | 返却済 | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | 保留中 | 2023-09-28 22:50:24 | 18909 | 2039 |
| 10 | 79 | キャンセル | 2023-09-29 15:06:21 | 14775 | 2017 |
次にジョブがトリガーされると、新たに注文ID 11と12が追加され、初期のスナップショット内の既存の注文(注文ID 7と9)が新しい注文ステータスで更新され、古い返品注文であった注文ID 2が存在しなくなった状態の、注文データの第2のスナップショットを取得します。したがって、2つ目のスナ�ップショットは以下のようになります:
| order_id | 価格 | order_status | order_date | customer_id | product_id |
|---|---|---|---|---|---|
| 1 | 91 | 再注文 | 2023-09-16 13:59:15 | 17127 | 2058 |
| 3 | 13 | 配送済 | 2023-10-04 01:07:35 | 10706 | 2005 |
| 4 | 45 | キャンセル | 2023-10-06 10:40:38 | 10245 | 2089 |
| 5 | 41 | 配送中 | 2023-10-08 14:52:16 | 19435 | 2057 |
| 6 | 38 | 配送済 | 2023-10-04 14:33:17 | 19798 | 2061 |
| 7 | 27 | 配送済 | 2023-10-10 23:08:24 | 10488 | 2033 |
| 8 | 23 | 返却済 | 2023-09-14 14:50:19 | 10302 | 2051 |
| 9 | 96 | 配送中 | 2023-10-10 23:08:24 | 18909 | 2039 |
| 10 | 79 | キャンセル | 2023-09-29 15:06:21 | 14775 | 2017 |
| 11 | 91 | 返却済 | 2023-10-10 23:24:01 | 18175 | 2089 |
| 12 | 24 | 返却済 | 2023年10月10日 23:39:13 | 13573 | 2068 |
アプローチ1の場合、「orders_snapshot」のスナップショットテーブルは、最新のスナッ�プショットデータによって上書きされています。スナップショットデータを処理するために、まず「orders」のターゲットストリーミングテーブルを作成します。
その後、最新のスナップショットデータから各order_idの最新の変更をターゲットテーブルに適用するために、以下のようにapply_changes_from_snapshotを使用します。この例では、新しいスナップショットを処理したいため、スナップショットデータソースから新しいスナップショットを読み込み、処理したスナップショットデータをターゲットテーブルに保存します。
アプローチ1と同様に、アプローチ2のスナップショットデータを処理するためには、まずターゲットのストリーミングテーブルを作成する必要があります。このターゲットテーブルを「orders」と呼びます。
アプローチ2では、ジョブがトリガーされて新しいスナップショットデータが生成されるたびに、そのデータは初期のスナップショットデータが保存された同じ定義済みのストレージパスに保存されます。このパスが存在するかどうかを評価し、初期のスナップショットデータを見つけるために、定義済みのパスの内容をリストし、パスから抽出した日時文字列を日時オブジェクトに変換し、これらの日時オブジェクトのリストを作成します。日時オブジェクトのリスト全体を持った後、このリストで最も早い日時を見つけることで、ルートパスディレクトリに保存された初期のスナップショットを特定します。
Approach 2で既に��述べたように、apply_changes_from_snapshotパイプラインがトリガーされるたびに、lambda関数は次にロードする必要があるスナップショットと、前のスナップショットからの変更を検出するための対応するスナップショットバージョンまたはタイムスタンプを特定する必要があります。
私たちは毎時スナップショットを使用しており、ジョブは毎時トリガーされるため、初期スナップショットの抽出された日時とともに1時間の増分を使用して、次のスナップショットパスと、このパスに関連する日時を見つけることができます。
このラムダ関数を定義し、データの変更を逐次的に識別できるようになると、apply_changes_from_snapshot文を使用してスナップショットを処理し、それらを作成したターゲットテーブル「orders」に逐次的に適用することができます。
アプローチに関係なく、コードが準備できたら、apply_changes_from_snapshot文を使用するために、ProまたはAdvanced製品エディションを使用したDLTパイプラインを作成する必要があります。
Delta Live Tablesパイプラインをタスクとして使用してワークフローを開発する(Databricks Asset Bundles(DABs)を使用)
サンプルワークフローの開発とデプロイを簡素化するために、私たちはDatabricks Asset Bundles(DABs)を使用しました。しかし、APPLY CHANGES機能はDABsの使用を必須とはしませんが、DatabricksワークフローとDLTパイプラインの開発とデプロイメントを自動化するためのベストプラクティスと考えられています。
このブログ�で取り上げている両方の一般的なアプローチでは、このリポジトリからDABsを活用しました。したがって、リポジトリには、エンドツーエンドのプロジェクト定義として機能するdatabricks.ymlという名前のソースファイルがあります。これらのソースファイルには、DLTパイプラインがワークフロー内のタスクとしてどのようにテストされ、デプロイされるかについてのすべてのパラメータと情報が含まれています。DLTパイプラインがHive MetastoreとUnity Catalogの2つのストレージオプションを提供していることを考慮に入れ、databricks.ymlファイルでは、アプローチ1とアプローチ2のジョブの両方の実装について両方のストレージオプションを考慮しました。databricks.ymlファイルのターゲット「development」は、Hive Metastoreを使用した両方のアプローチの実装とDBFSロケーションを指し、databricks.ymlファイルのターゲット「development-uc」は、Unity Catalogを使用した両方のアプローチの実装と管理されたUCボリュームへのデータ保存を指します。リポジトリ内のREADME.mdファイルに従って、いくつかのバンドルコマンドを使用するだけで、どちらのストレージオプションでも両方のアプローチをデプロイすることができます。
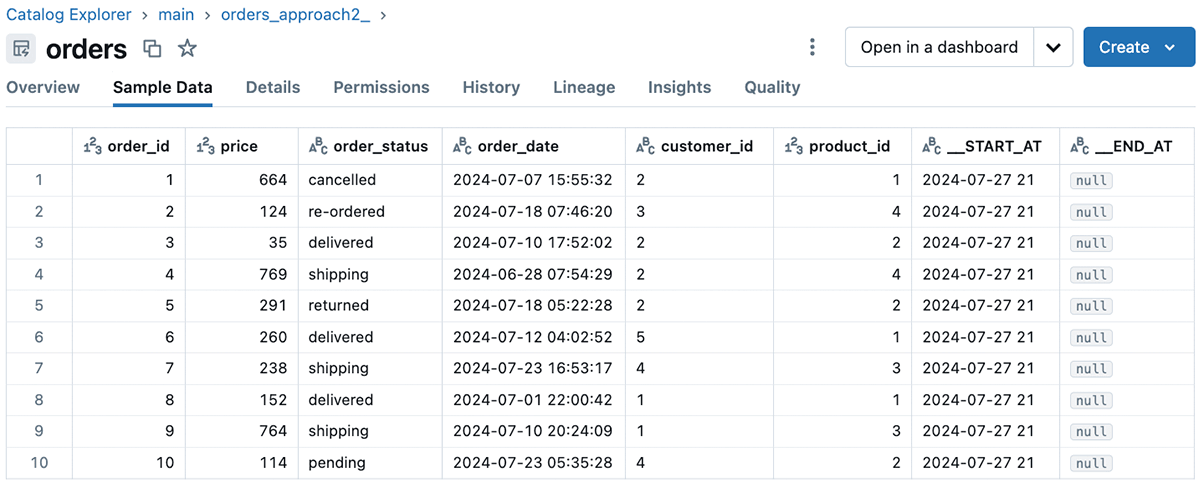
我々が取り上げた例では、アプローチ2ではSCDタイプ2のターゲットテーブルを使用し、stored_as_scd_type引数に2を渡すことで、ターゲットテーブルに注文IDの歴史的な値と現在の値をすべて保存しました。カタログエクスプローラーを通じてターゲットテーブルに移動すると、ターゲットテーブルの列、サンプルデータ、詳細、およびターゲットテーブルに関連するより洞察に満ちたフィールドを見ることができます。SCDタイプ2の変更については、Delta Live Tablesが適切なシーケンス値をターゲットテーブルの__START_ATおよび__END_AT列に伝播します。以下に、Unity Catalogを使用したときのCatalog Explorerのターゲットテーブルからのサンプルデータの例を示します。下の画像のカタログ「main」は、この例で便宜上使用しているUnity Catalogメタストアのデフォルトのカタログです。
次のステップ
スナップショットに基づいたスケーラブルで信頼性の高いインクリメンタルデータパイプラインを構築することはこれまでになく簡単になりました。Databricksを無料で試すと、この例を実行できます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。