長いシーケンスでLlama 3.1をファインチューニング

公開日: 2024年9月19日
によって Saaketh Narayan、アイリーン・ディア、ブライアン・チュー、 シャシャンク・ラジプート 、 ヴィタリー・チレイ による投稿
私たちは、Mosaic AIモデルトレーニングが、Meta Llama 3.1モデルファミリーの微調整時に131Kトークンの全文脈長をサポートするようになったことを発表することを嬉しく思います。この新機能により、Databricksの顧客は、長い文脈長のエンタープライズデータを使用して特化したモデルを作成することで、さらに高品質なRetrieval Augmented Generation(RAG)またはツール使用システムを構築することができます。
LLMの入力プロンプトのサイズは、その コンテキスト長 によって決定されます。お客様は特にRAGやマルチドキュメント分析のようなユースケースでは、短いコンテキスト長に制限されることが多いです。Meta Llama 3.1モデルは、コンテキスト長が131Kトークンと長いです。比較すると、『グレート・ギャツビー』は 約72Kトークン です。Llama 3.1モデルは、大量のデータコーパスを理解することを可能にし、RAGでのチャンキングや再ランキングの必要性を減らすか、エージェントのツール説明を増やすことができます。
ファインチューニングにより、顧客は自社のエンタープライズデータを使用して既存のモデルを特化させることができます。最近の技術であるRetrieval Augmented Fine-tuning (RAFT)は、ファインチューニングとRAGを組み合わせてモデルにコンテキスト内の無関係な情報を無視するように教え、出力品質を向上させます。ツールの使用において、ファインチューニングはモデルを特化させて、企業システム特有の新しいツールやAPIをより良く使用することができます。どちらの場合も、長いコンテキスト長でのファインチューニングにより、モデルは大量の入力情報を理解することができます。
Databricks Data Intelligence Platformは、お客様が自身のデータを使用して高品質なAIシステムを安全に構築できるようにします。お客様が最先端の生成AIモデルを活用できるようにするためには、長いコンテキスト長でのLlama 3.1の効率的なファインチューニングなどの機能をサポートすることが重要です。このブログ投稿では、エンタープライズデータ上でGenAIモデルを安全に構築し、微調整するための最高水準のサービスであるDatabricks Model Trainingを最適化するための最近の取り組みについて詳しく説明します。
長いコンテキスト長の微調整
長いシーケンス長のトレーニングは、主にその増加したメモリ要件のために課題をもたらします。LLMトレーニング中、GPUは最適化��プロセスのための勾配を計算するために、中間結果(つまり、活性化)を保存する必要があります。トレーニング例のシーケンス長が増えると、これらの活性化を保存するために必要なメモリも増え、GPUのメモリ制限を超える可能性があります。
これを解決するために、私たちはシーケンス並列化を採用し、単一のシーケンスを複数のGPUに分割します。このアプローチは、シーケンスのアクティベーションメモリを複数のGPUに分散し、微調整ジョブのGPUメモリフットプリントを減らし、訓練効率を向上させます。図1に示す例では、2つのGPUが同じシーケンスの半分をそれぞれ処理します。私たちは、オープンソースのStreamingDatasetの レプリケーション機能を使用して、GPUグループ間でサンプルを共有します。
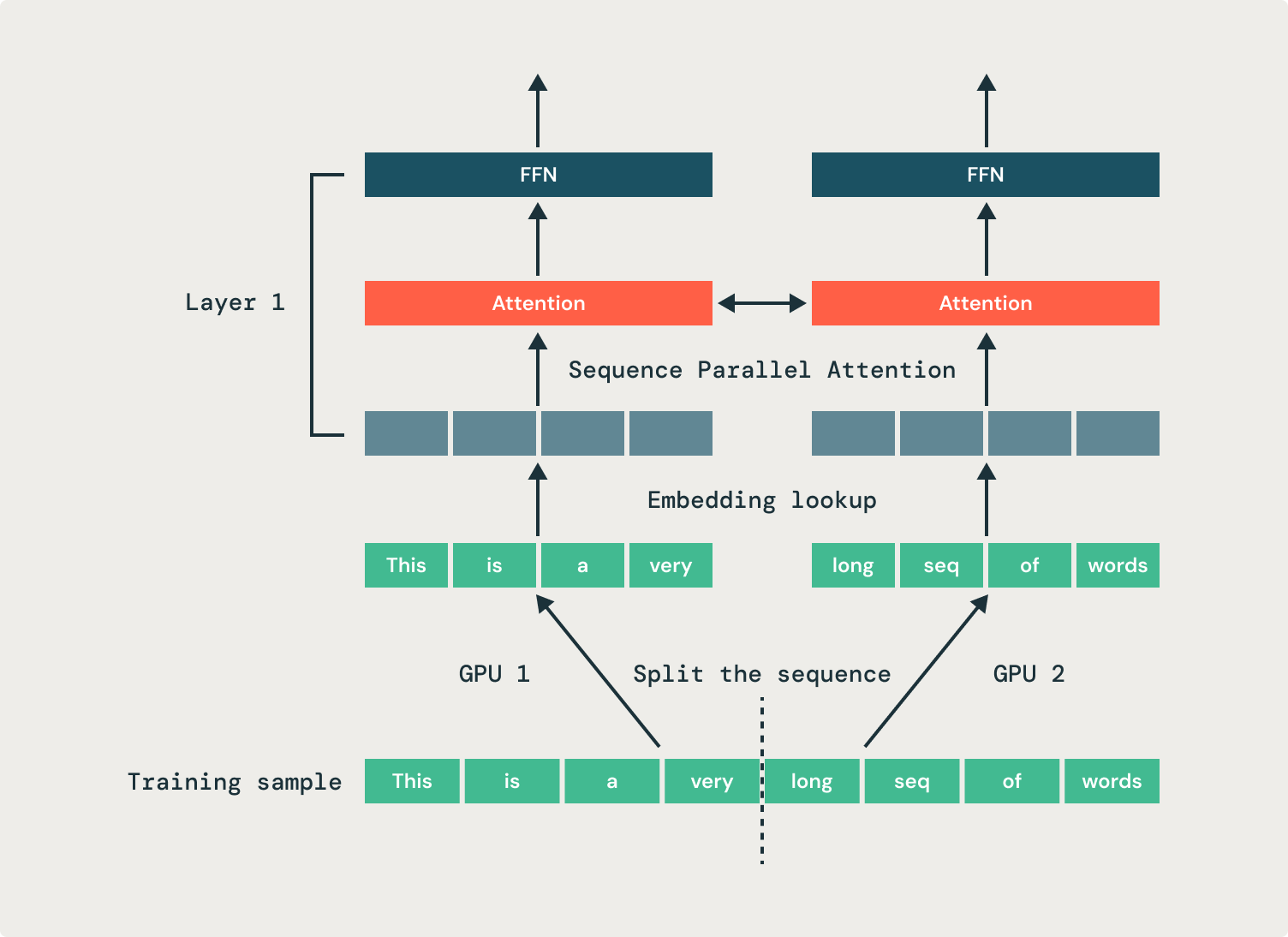
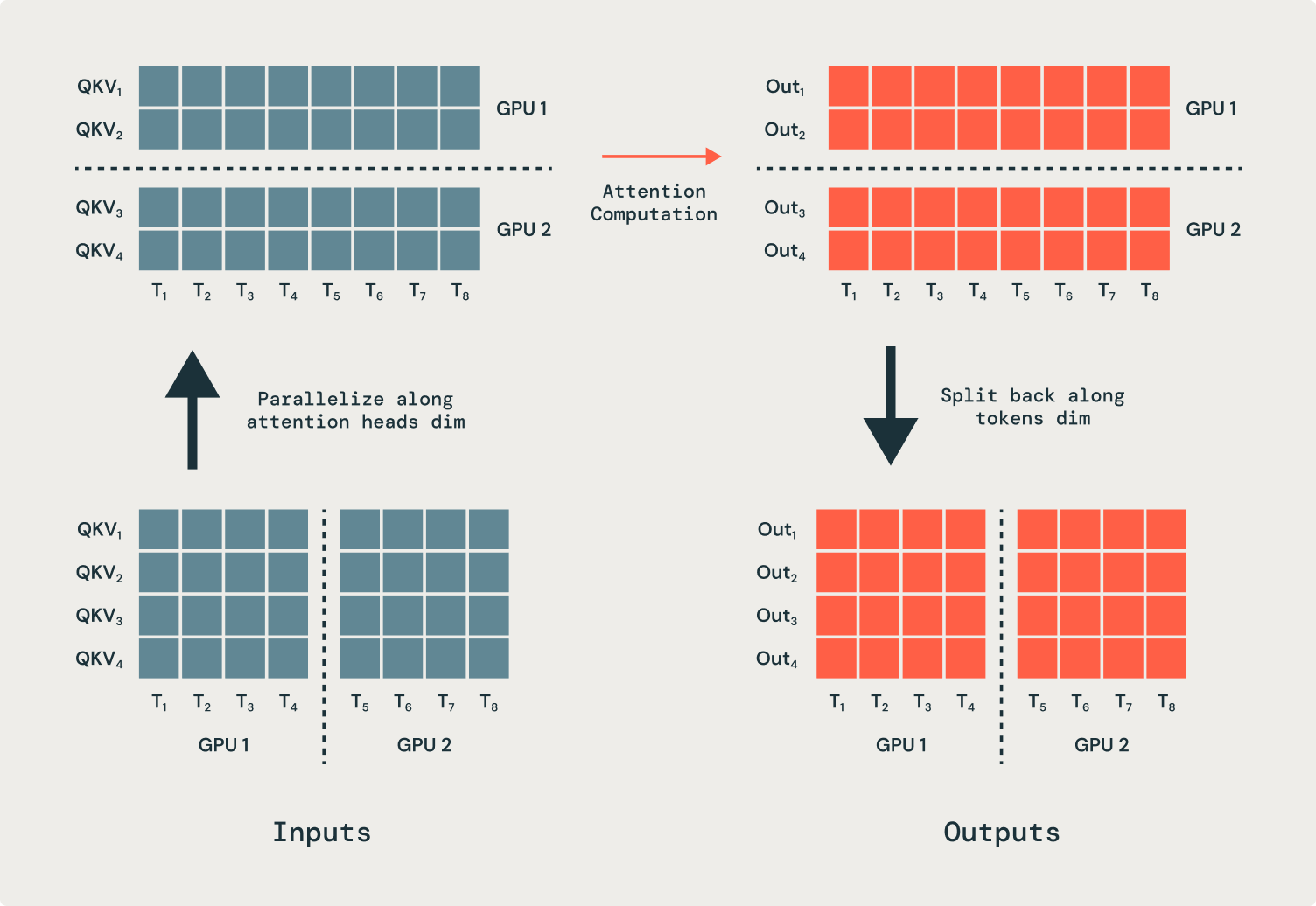
トランスフォーマー内のすべての操作はシーケンス次元から独立していますが、注意力は重要です。その結果、注意操作は部分的なシーケンスを入力および出力するように変更する必要があります。私たちは、多くのGPUに注意力の頭を並列化し、通信操作(全てから全てへ)を必要とします。これにより、トークンを処理するための正しいGPUに移動します。注意操作の前に、各GPUは各シーケンスの一部を持っていますが、各注意頭は完全なシーケンスで動作する必要があります。図2に示されている例では、最初のGPUは最初のアテンションヘッドのすべての入力を送信し、2つ目のGPUは2つ目のアテンションヘッドのすべての入力を送信します。注意操作の後、出力は元のGPUに戻されます。
シーケンス並列性により、大規模なコンテキスト全体を理解し、推論するカスタムモデルを可能にするLlama 3.1のフルコンテキスト長の微調整を提供することができます。
エンタープライズ向けエージェントAIプレイブック

ファインチューニングパフォーマンスの最適化
微調整のためのシーケンス並列化のようなカスタム最適化は、私たちが基礎となるモデル実装を細かく制御することを必要とします。このようなカスタマイズは、既存のLlama 3.1モデリングコードだけではHuggingFaceで可能ではありません。しかし、サービングの容易さと外部互換性のために、最終的に微調整されたモデルはLlama 3.1 HuggingFaceモデルチェックポイントである必要があります。したがって、私たちの微調整ソリューションは、訓練のために高度に最適化可能であるだけでなく、相互運用可能な出力モデルを生成することもできる必要があります。
これを実現するために、私たちはHuggingFace Llama 3.1モデルをトレーニング前に同等の内部Llama表現に変換します。この内部表現は、効率的なカーネル、選択的な活性化チェックポイント、効果的なメモリ使用、シーケンスIDのアテンションマスキングなどの改善を通じて、トレーニング効率を大幅に最適化しています。結果として、私たちの内部Llama表現は、最大40%高いトレーニングスループットを実現し、40%小さいメモリフットプリントを必要としながら、シーケンス並列性を可能にします。これらのリソース利用の改善は、モデルの品質を向上させるための迅速な反復が可能になるため、顧客にとってより良いモデルを提供することにつながります。
トレーニングが終了したら、モデルを内部表現からHuggingFace形式に戻し、保存されたアーティファクトがすぐにProvisioned Throughputの提供を通じて提供できるようにします。以下の図3は、この全プロセスを示しています。

次のステップ
UIまたはPythonでプログラム的にLlama 3.1の微調整を今すぐ始めましょう。 Mosaic AIモデルトレーニングを使用すると、ビジネスニーズに合わせて高品質でオープンソースのモデルを効率的にカスタマイズし、データインテリジェンスを構築できます。私たちのドキュメンテーション(AWS, Azure)を読み、私たちの価格ページを訪れて、DatabricksでLLMsの微調整を始めましょう。