
Databricks でデータサイエンスの能力を最大化
オープンなレイクハウス基盤に構築されたコラボレーション型の統合データサイエンス環境により、データの準備、モデリング、インサイトの共有まで、エンドツーエンドのシームレスなデータサイエンスワークフローを実現。クリーンで信頼性の高いデータへの迅速なアクセス、事前構成されたコンピューティングリソース、IDE 統合、多言語対応、高度な可視化ツールなど、データサイエンスチームに最大限の柔軟性を提供します。

データサイエンスワークフロー全体におけるコラボレーション
Databricks の Notebook では、Python、R、Scala、SQL な��どの言語を使用し、インタラクティブな視覚化によるデータ探索が可能で、新たな知見を発見できます。また、共同編集、コメント作成、自動バージョニング、Git の統合、ロールベースのアクセス制御により、高い信頼性でのセキュアなコード共有が可能です。

インフラ管理からの解放
ノート PC のデータ許容量やコンピューティング利用枠の制限など、インフラに関する懸念は不要になり、データサイエンスに注力できます。Databricks のプラットフォームでは、ローカル環境からクラウドへの移行、Notebook の自動管理クラスタへの接続が容易で、分析のワークロードを柔軟にスケーリングできます。

任意のローカル IDE でスケーラブルなコンピューティング
IDE(統合開発環境)の選択肢はさまざまです。Databricks では、任意の IDE の接続が可能です。使い慣れた環境で、無制限のデータストレージとコンピューティングを利用できます。さらに、Databricks で直接使用できる RStudio や JupyterLab が、シームレスなエクスペリエンスを提供します。
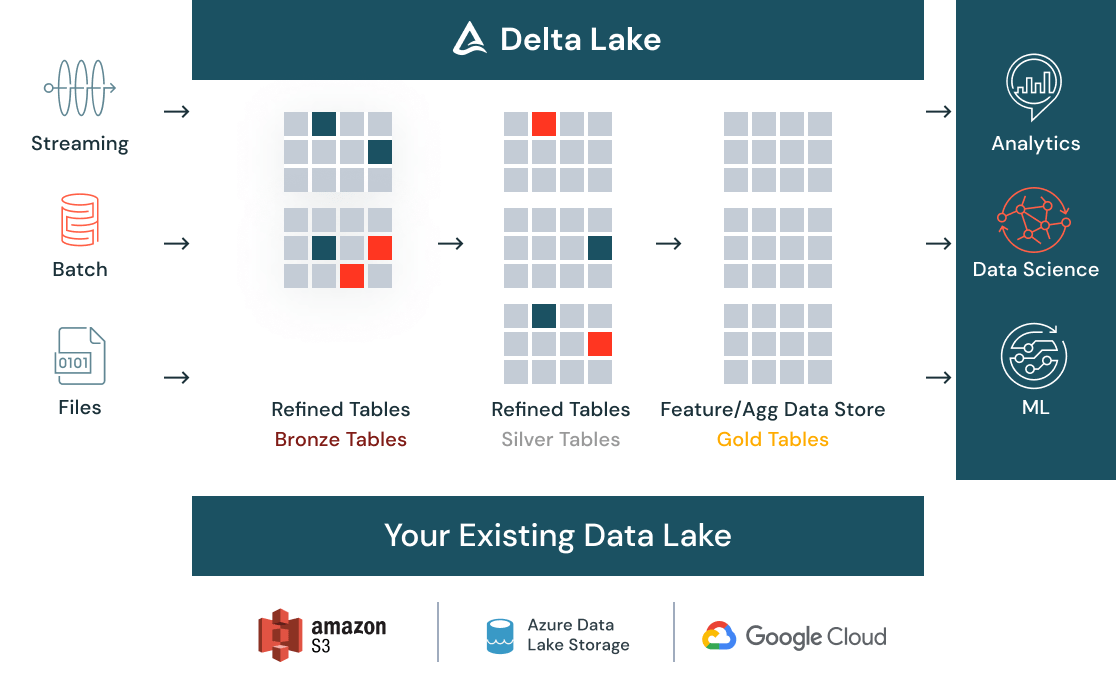
データサイエンスのためのデータ供給
バッチ、ストリーミング、構造化、非構造化のあらゆるデータを Delta Lake は単一システムに集約し、クリーニング、カタログ化します。これにより、組織全体が一元化されたデータストアを使用してデータを探索できるようになります。データ品質の自動チェック機能により、分析の要件に適合する高品質なデータを供給します。データの追加や変換に際しても、バージョニング機能により、コンプライアンス要件に対応します。

データ探索のためのローコード、ビジュアルツール
Databricks Notebook 内の視覚化ツールをネイティブに使用して、データの準備、変換、分析を行い、さまざまな専門レベルのユーザーがデータを扱うことができ��ます。データの変換と視覚化が完了したら、バックグラウンドで実行されるコードを生成できます。定型コードを作成する時間を節約できるため、価値の高い作業に時間を費やすことができます。
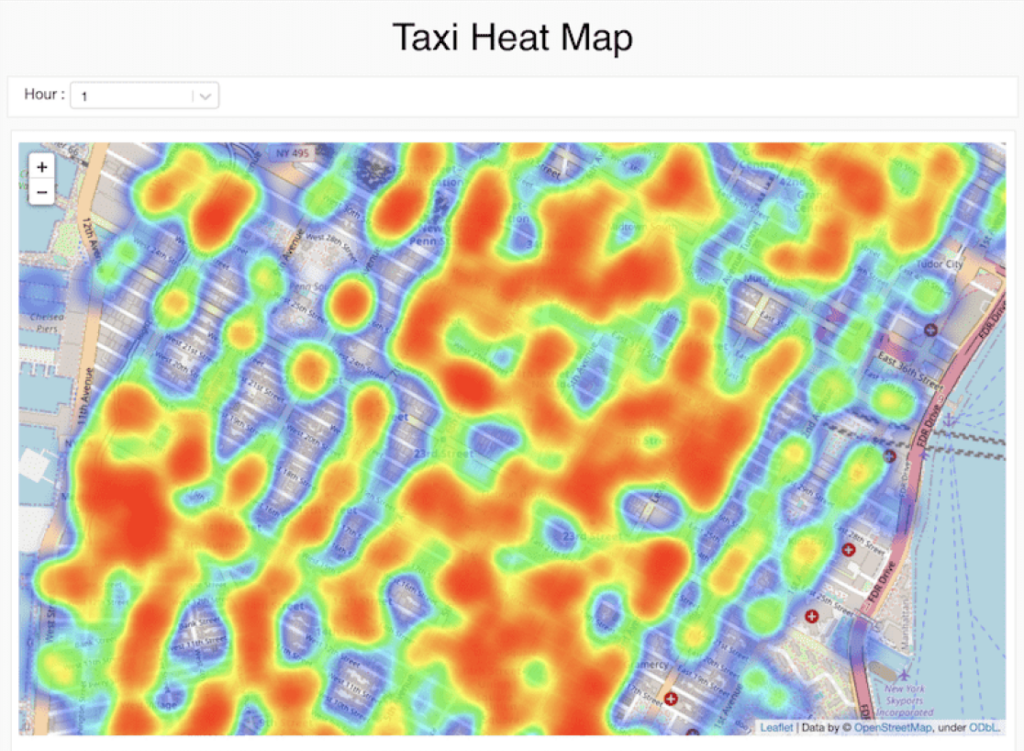
新たな気づきの発見と共有
分析をダイナミックダッシュボードに素早く反映し、分析結果を容易に共有、エクスポートできます。ダッシュボードは常に最新の状態で、インタラクティブなクエリの実行も可能です。ロールベースのアクセス制御で、セル、視覚化、Notebook を共有し、HTML や IPython ノートブックなどの複数のフォーマットでエクスポートできます。
