高品質なAIエージェントシステムの構築とデプロイ
自社のデータをあらゆるAIモデルとセキュアに接続し、高精度かつ特定のドメインに特化したアプリケーションを構築できます。
トップチームが Databricks で成功
エージェントシステムのための統合プラットフォーム
汎用的なAIモデルへの依存から脱却しましょう。Databricksは、高精度かつデータドリブンな結果をもたらすAIエージェントシステムの構築ツールを提供します。独自データに基づくエージェント構築
社内の複数システムにまたがる企業データを活用し、自社要件に合わせて最適化されたエージェントを迅速に開発できます。従来の機械学習(ML)から生成AIまで、あらゆるモデルを柔軟に組み合わせ、ビジネスニーズに最適なソリューションを適用します。
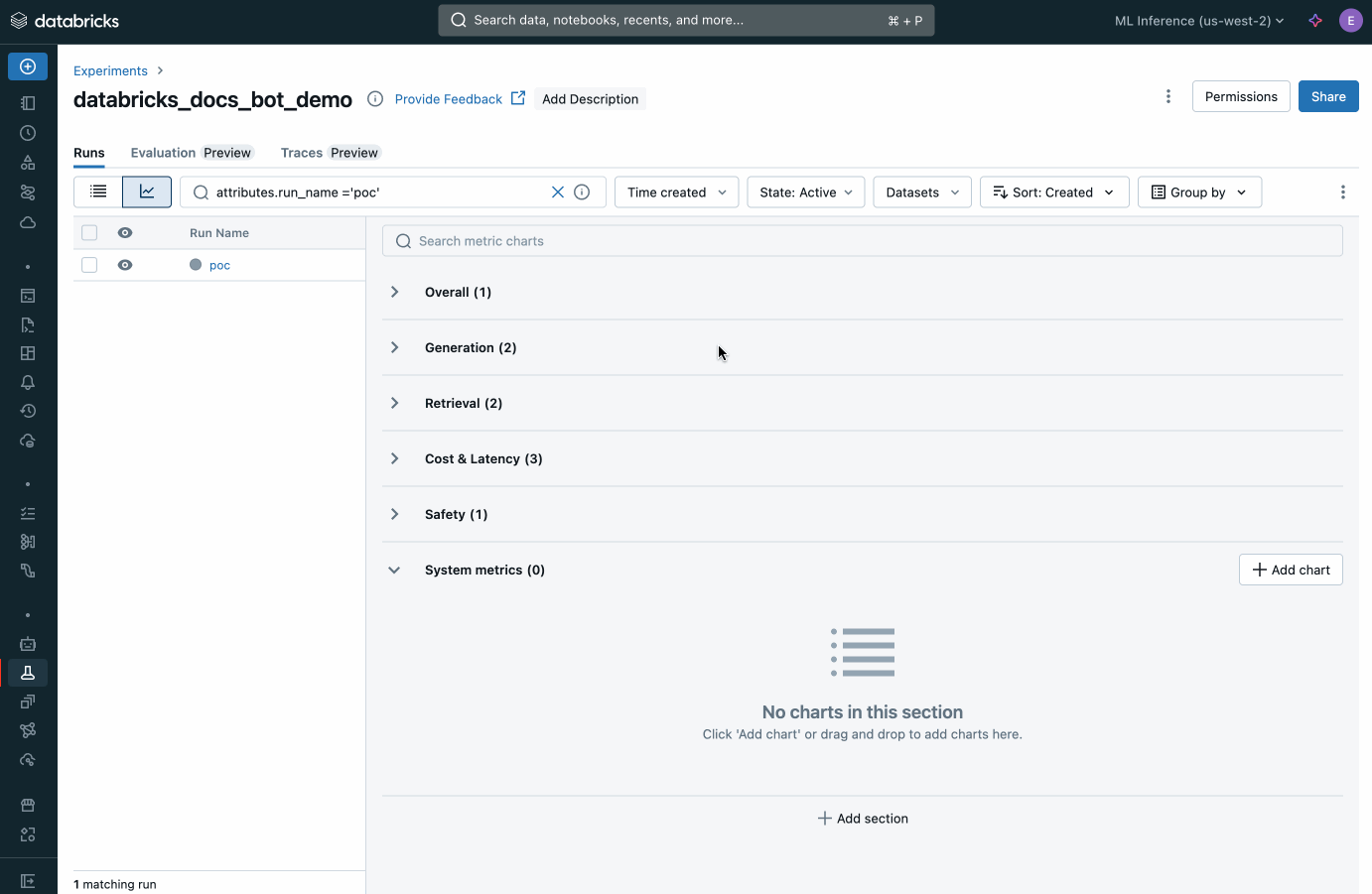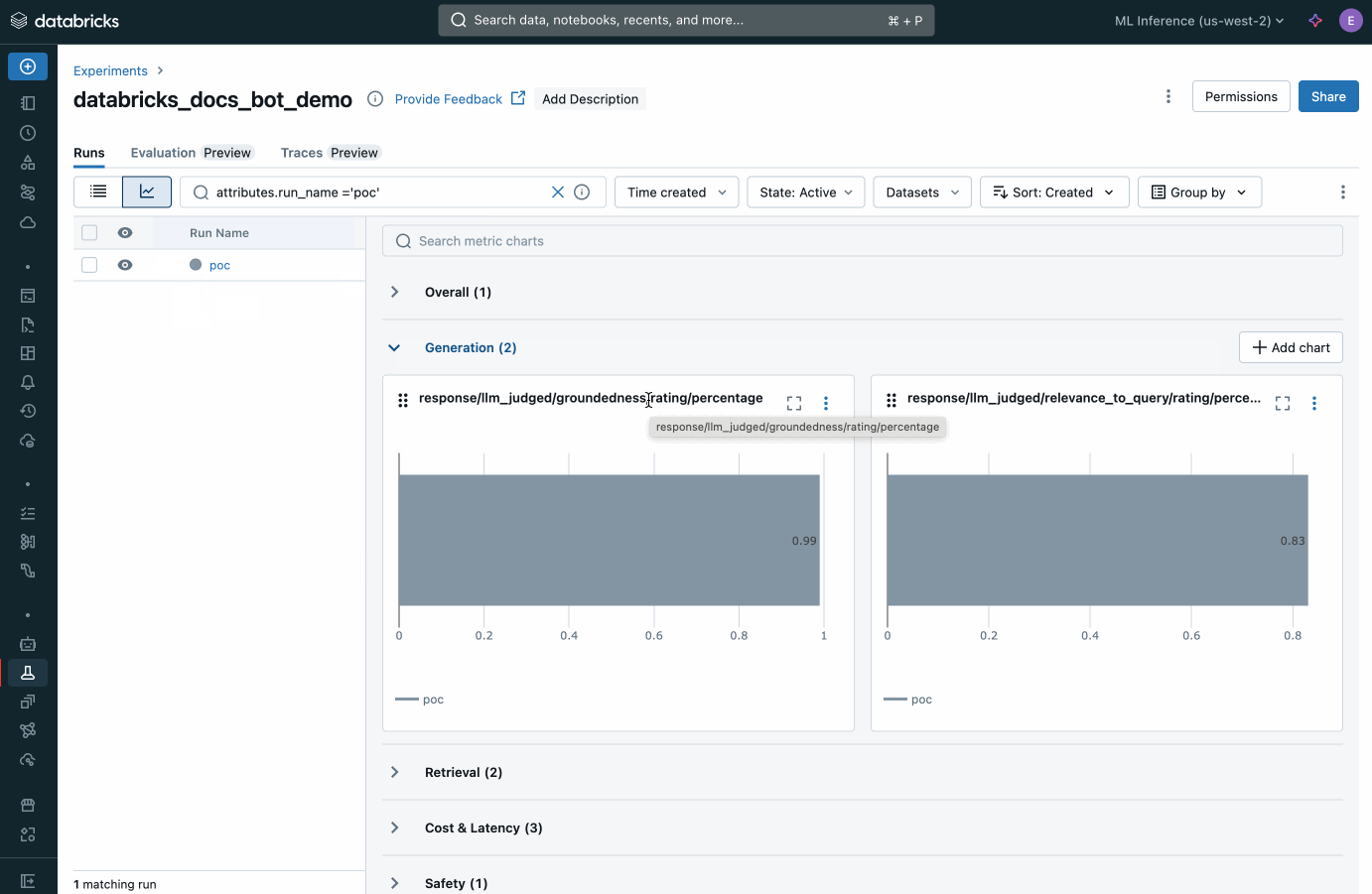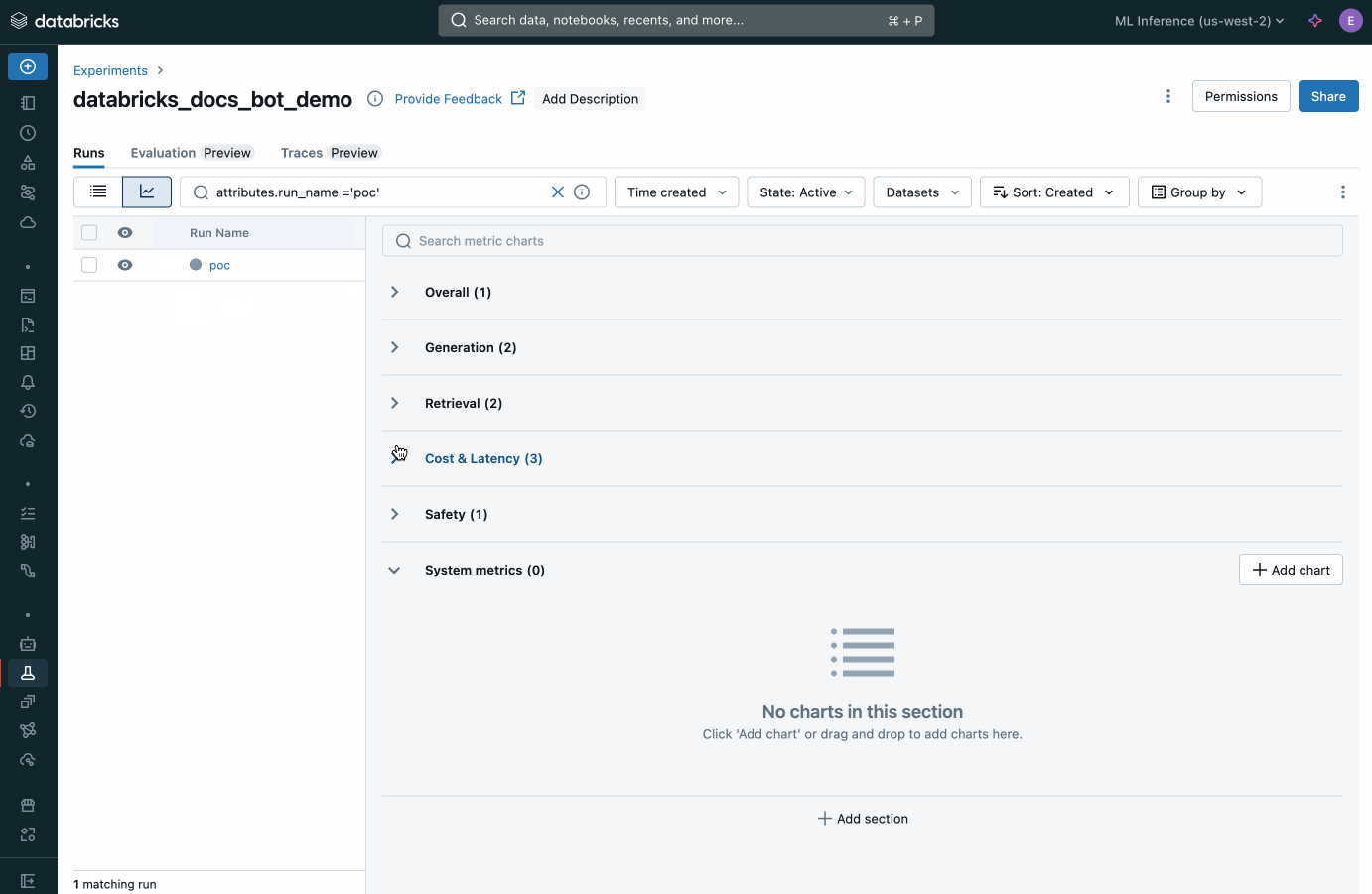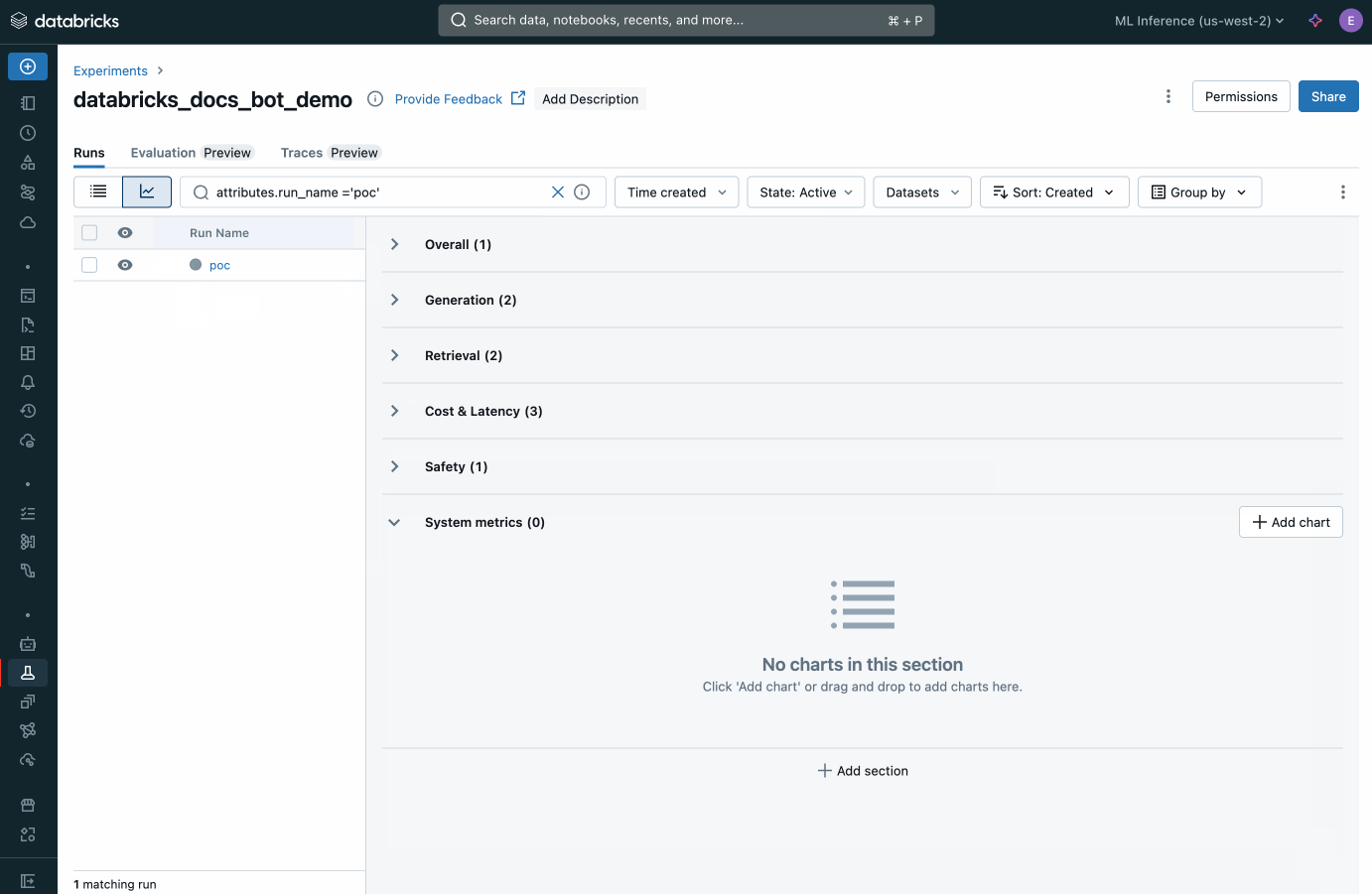
カスタム評価(エージェント評価)
Databricksは、あらゆるAIモデルに対応した組み込みのエージェント評価機能を提供します。AIによる��自動判定(AI-as-a-judge)を用いてエージェントの出力品質を測定・検証し、迅速な改善と再デプロイを実現します。従来のMLから生成AIアプリケーションに至るまで、本番環境における課題の特定、根本原因の分析、および是正措置の実行をシームレスに支援します。
ガバナンス
エージェントシステム全体を網羅するエンドツーエンドのガバナンスにより、強固なデータセキュリティを維持します。すべてのモデルにガードレール(安全対策)を適用し、アクセス制御の自動化やレート制限の設定を行うとともに、ワークフロー全体のデータリネージ(来歴)を追跡します。
44%の精度向上



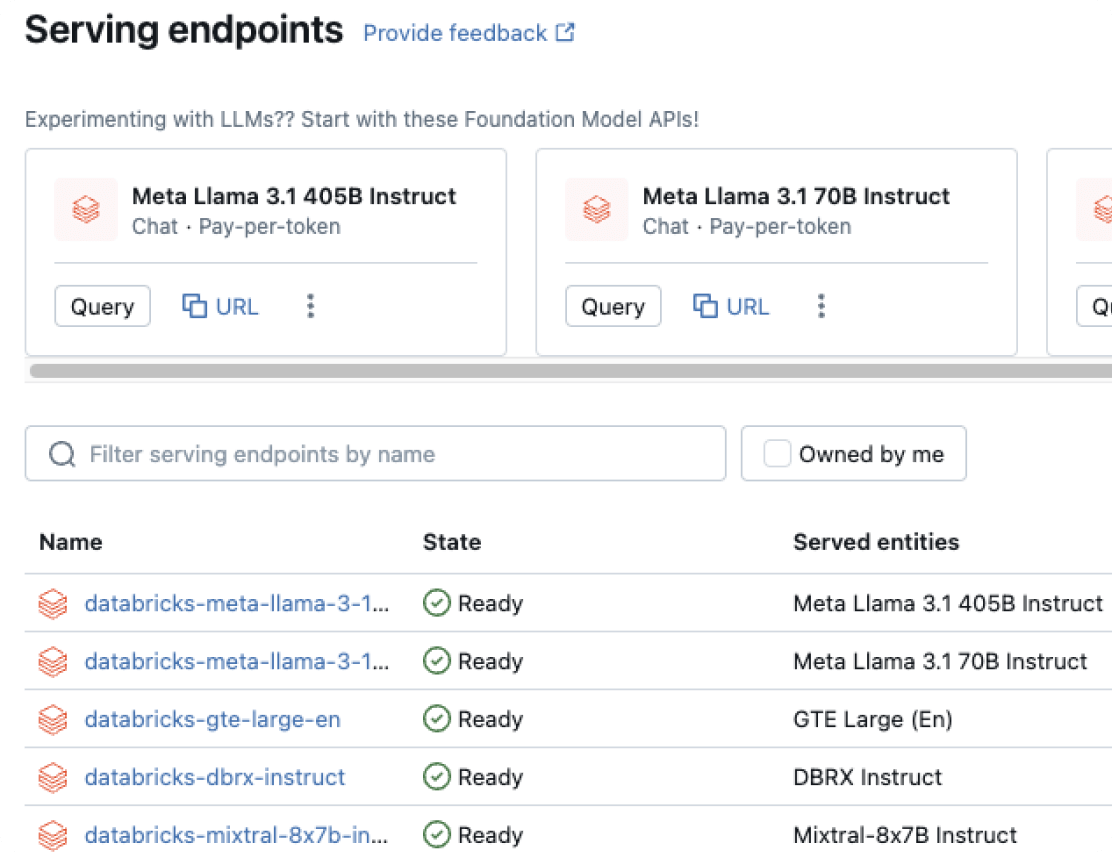
エンドツーエンドのAIエージェント構築ツール

Agent Bricks
自社のエンタープライズデータを基盤としたAIエージェントを構築します。合成データの生成、カ��スタム評価、自動チューニングにより、品質とコストを最適化できます。
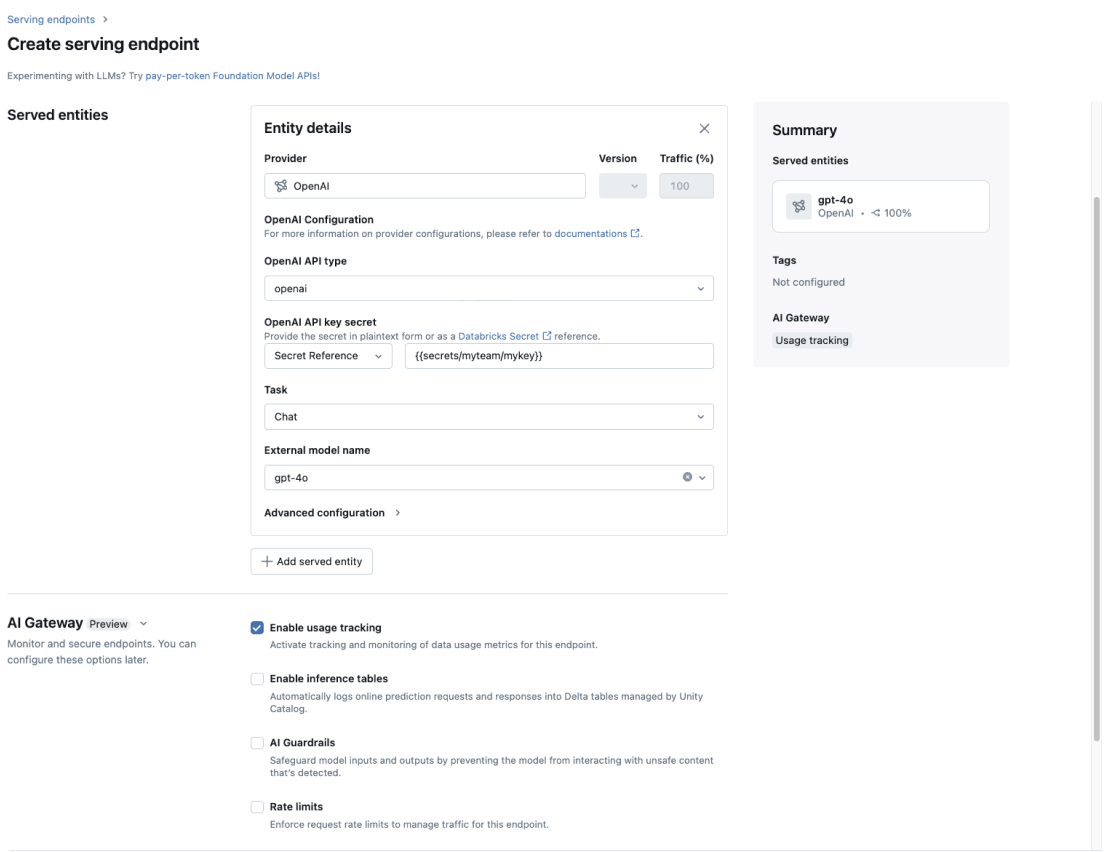
AI ゲートウェイ
組織内で利用されるすべての生成AIモデルに対し、一貫したデータガバナンスを適用します。
ベクトル検索
ソースデータとリアルタイムに同期する、検索拡張生成(RAG)向けの高パフォーマンスなベクトルデータベースです。
エージェントフレームワークと評価
本番運用レベルの高品質なAIエージェントを構築します。中核機能である「エージェント評価」は、AI支援による出力品質の保証と、人間の専門家がフィードバックを行うための直感的なUIを提供します。
モデルサービング
エージェント、生成AI、および従来のMLモデルのデプロイを統合する単一のプラットフォームです。
モデルトレーニング
オープンソースLLMのファインチューニング、独自LLMの事前学習、および従来のMLモデル構築をサポートします。
Databricks Notebooks
リアルタイムな共同作業を可能にするコラボレーティブ・ノートブック。データサイエンスのワークフローを効率化し、チームの生産性を高めます。
Managed MLflow
モデルと生成AIアプリ構築を支えるオープンソースの統合MLOpsプラットフォーム「MLflow」を、エンタープライズ基準の信頼性、セキュリティ、スケーラビリティで拡張します。
データ品質モニタリング
シンプルかつスケーラブルな監視機能により、異常検知やデータの鮮度をトラッキングし、すべてのAI資産で一貫した品質を担保します。
Databricks データ・インテリジェンス・プラットフォーム
本プラットフォームのあらゆるツールを活用し、組織全体のデータとAIをシームレスに統合します。
高品質なエージェントシステムの構築

データの容易な変換と準備
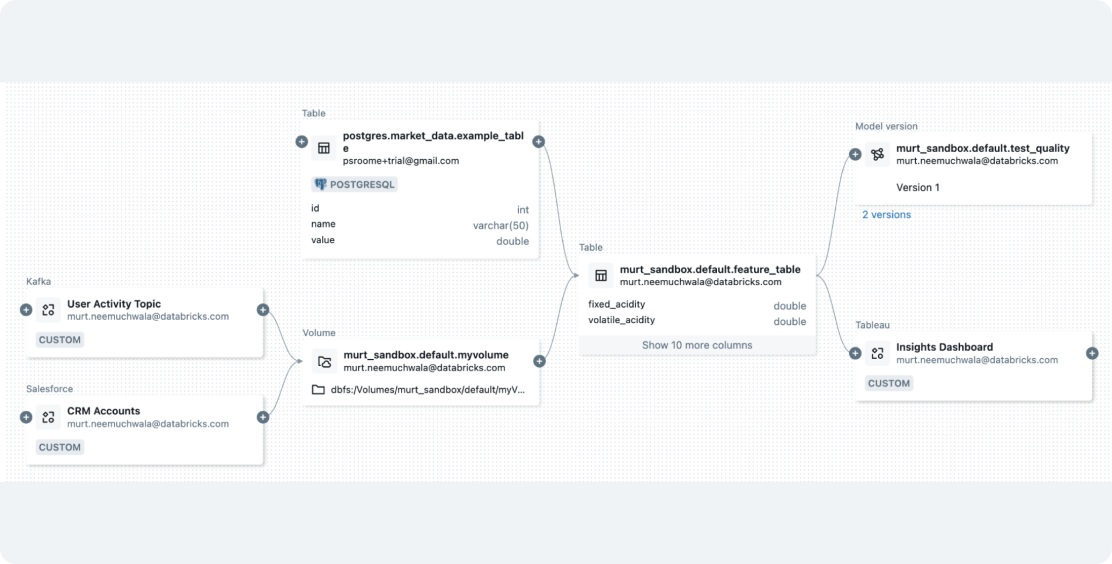
生成AIとMLワークフローのためのシームレスなデータ統合
Databricksを利用することで、多様なデータを取り込み、生成AIやMLアプリケーションで活用するためのジョブを効率的にオーケストレーションできます。組み込みのガバナンスによりデータの特徴量化を簡素化し、Databricks ベクトル検索を用いてRAG用のインデックスを作成します。これにより、データパイプラインとモデルパイプラインが統合され、ワークフローの効率化とコスト削減を実現します。