Hochwertige KI-Agent-Systeme entwickeln und implementieren
Verbinden Sie Ihre Daten sicher mit beliebigen KI-Modellen, um zielgenau fachspezifische Anwendu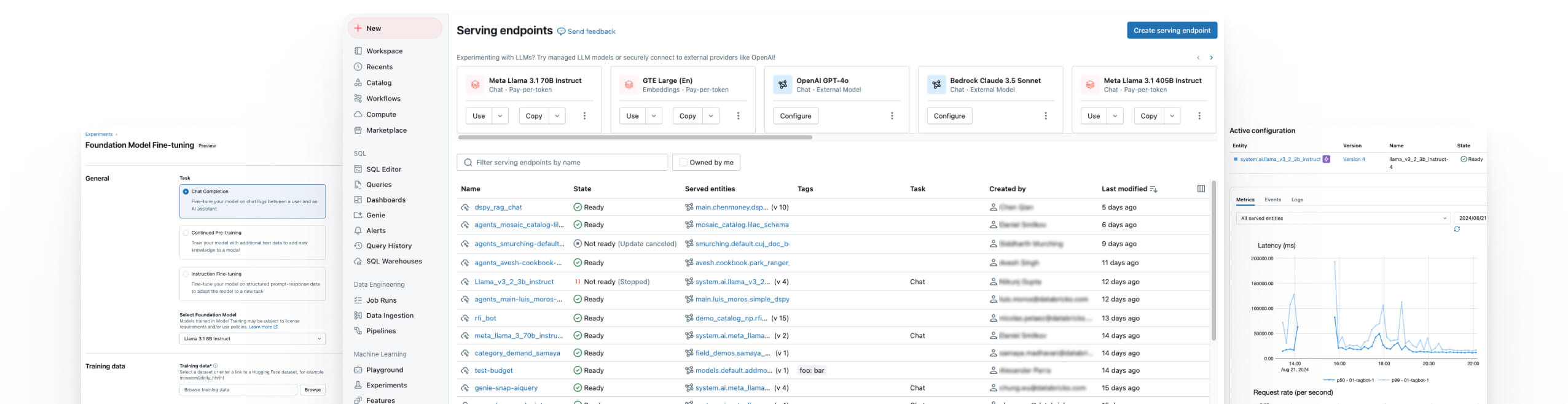
ERFOLGREICHE SPITZENTEAMS DANK DATABRICKS

Die einzige Unified Platform für Agent-Systeme
Schluss jetzt mit generischen KI-Modellen. Databricks bietet alle Tools, die Ihnen den Aufbau von Agent-Systemen ermöglichen, um korrekte datengestützte Ergebnisse zu erhalten.Agents, die auf Ihre Daten aufsetzen
Entwickeln Sie innerhalb kürzester Zeit Agents, die für Ihre Unternehmensdaten systemübergreifend optimiert sind. Sie können beliebige Modelle – von klassischem ML bis GenAI – nutzen, um die beste Lösung für Ihre spezifischen Anwendungsanforderungen zu entwickeln.
Individuelle Evaluierung
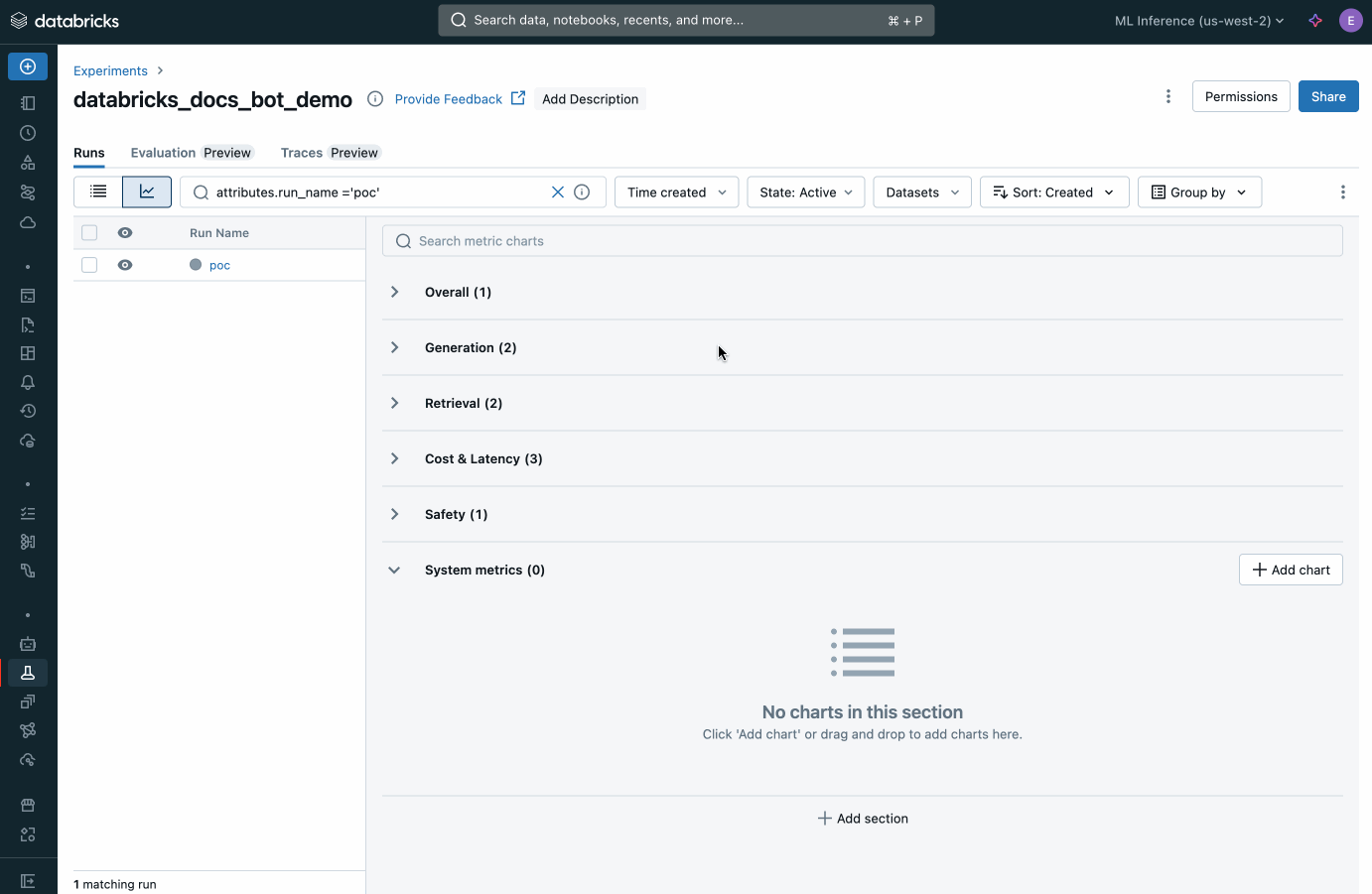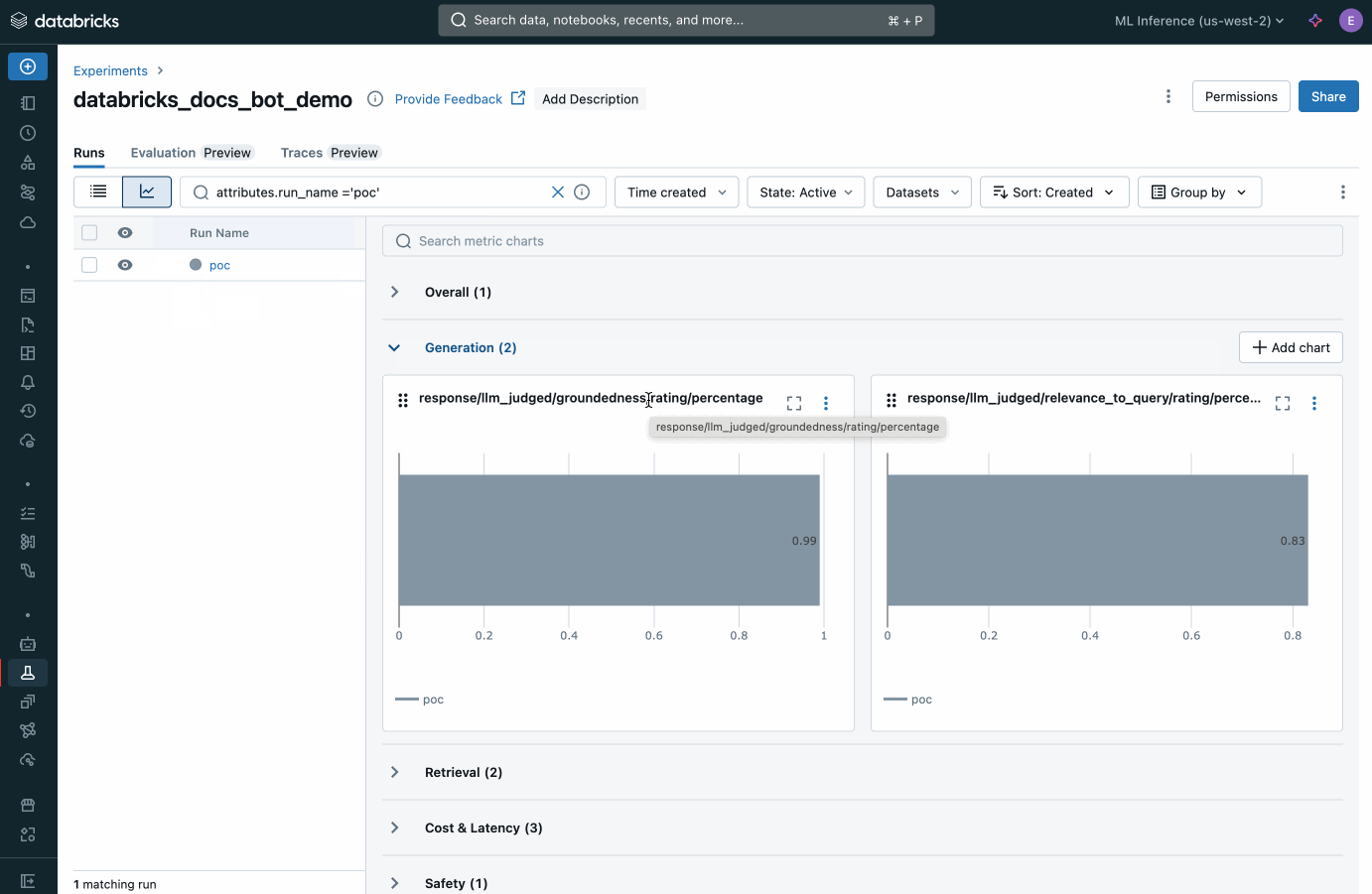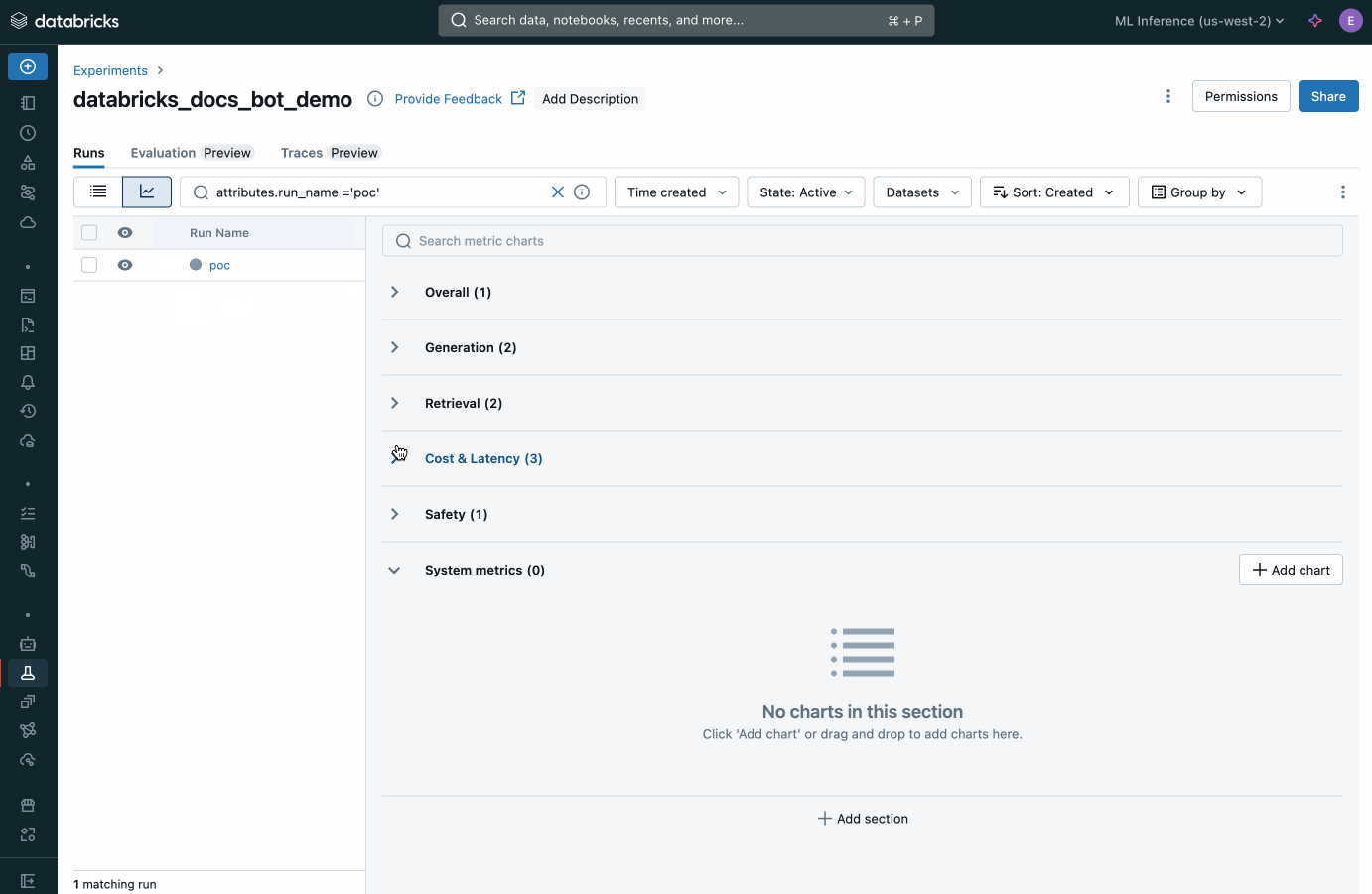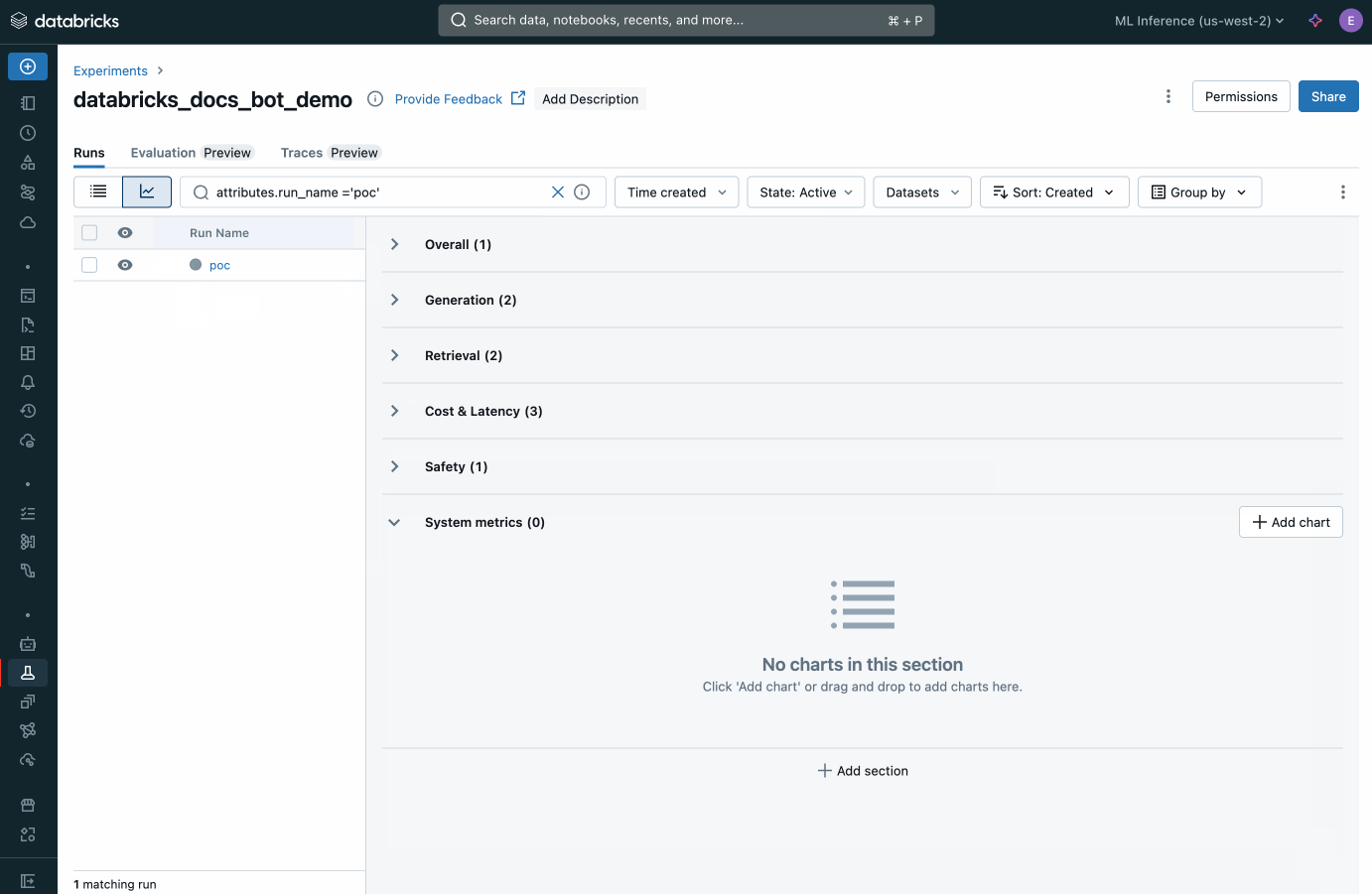
Databricks bietet eine integrierte Evaluierung für Agents und unterstützt alle KI-Modelle. Messen Sie die Qualität der von Agents generierten Ergebnisse mit KI-Judges, bewerten Sie Problemlösungen und implementieren Sie sie im Handumdrehen neu. Ob ML- oder GenAI-Apps: Sie können Produktionsprobleme ermitteln, Ursachen analysieren und Abhilfemaßnahmen ergreifen.
Governance
Sorgen Sie mit lückenloser Agent-Governance für Datensicherheit. Implementieren Sie Sicherheitsvorkehrungen für alle Ihre Modelle, automatisieren Sie Zugriffskontrollen, legen Sie Obergrenzen fest und verfolgen Sie die Datenherkunft im gesamten Workflow.
44 % Steigerung bei der Genauigkeit
10 Mio. $ Produktivitätssteigerung
96 % Treffsicherheit bei den Antworten



Tools für umfassende KI-Agent-Systeme

Agent Bricks
Bauen Sie KI-Agents, die auf Ihren Unternehmensdaten basieren. Databricks Agent Bricks ermöglicht es Ihnen, Qualität und Kosten zu optimieren – mit synthetischen Daten, individueller Evaluierung und automatischem Tuning.
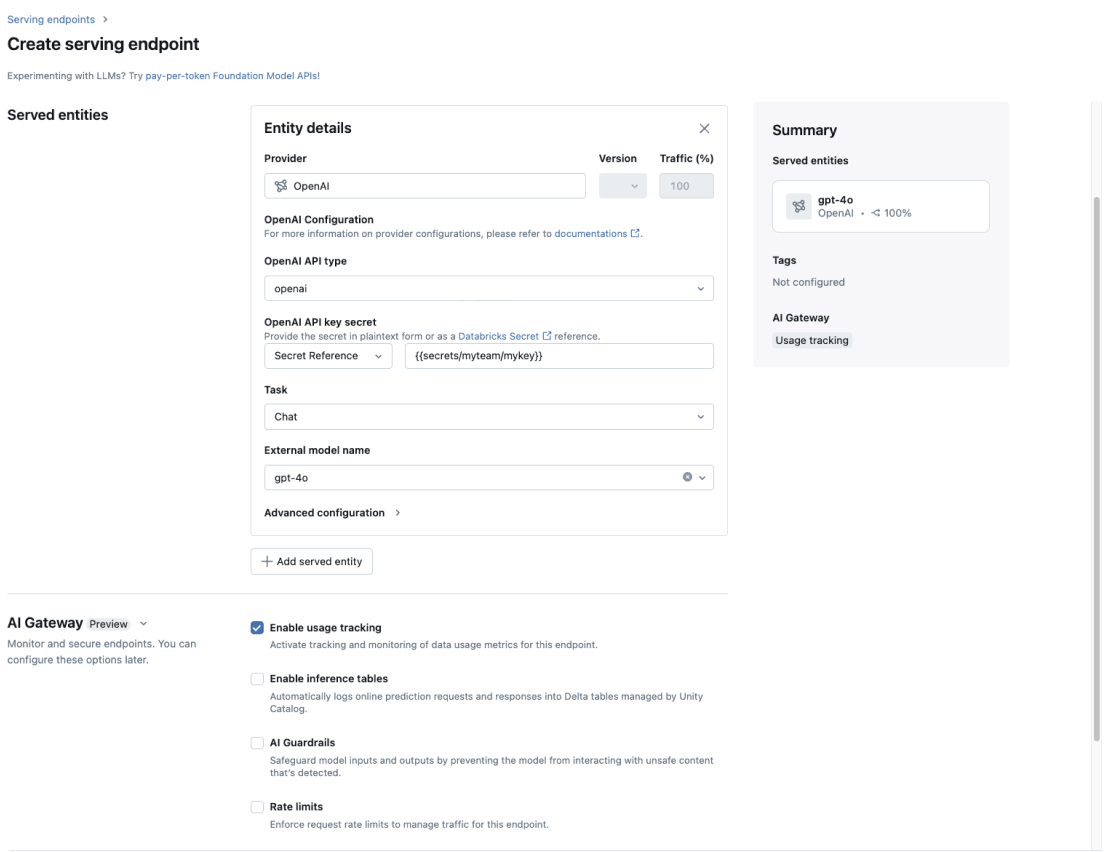
Unity AI Gateway
Ein zentraler Ort für die Data Governance aller LLMs und MCPs im Unternehmen.
AI Search
Leistungsstarke Vektordatenbank mit Echtzeitsynchronisierung der Quelldaten.
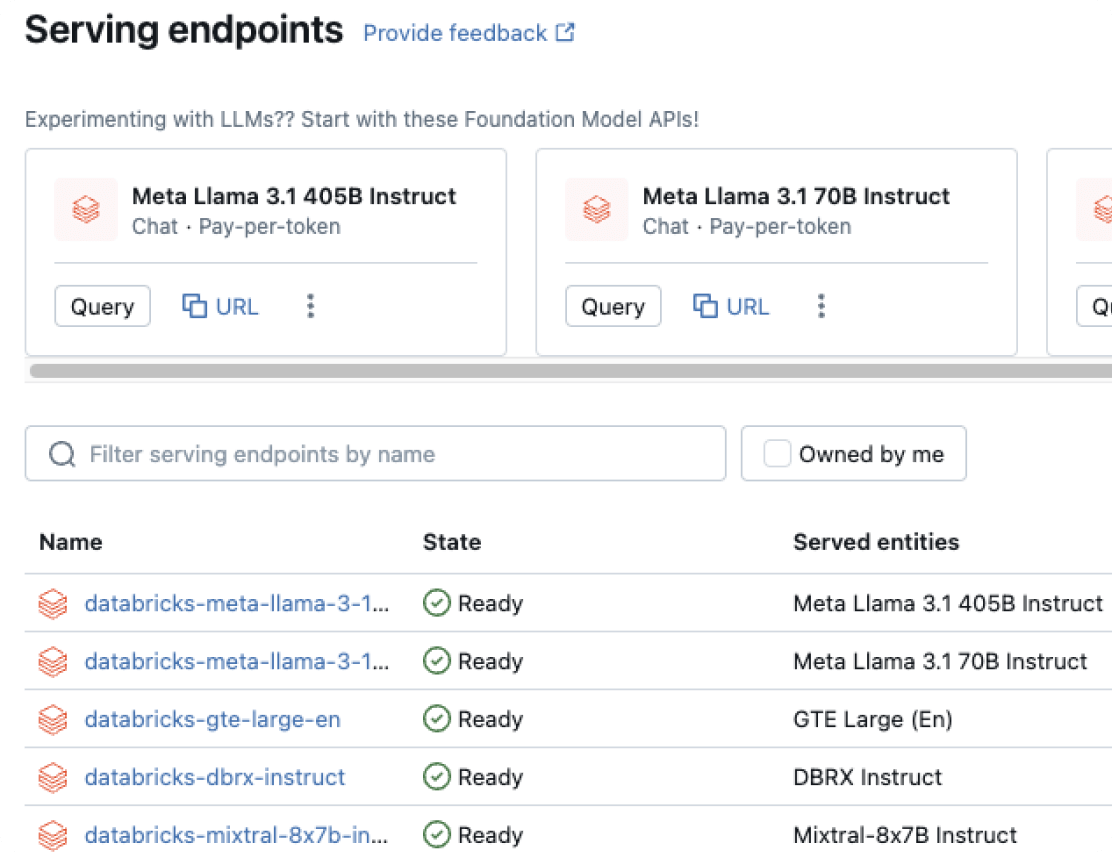
Agent Framework und Agent Evaluation
Entwickeln Sie mit Agent Framework KI-Agenten in Produktionsqualität. Als integraler Bestandteil des Frameworks stellt Agent Evaluation die Qualität der von Agents generierten Inhalte mittels KI-gestützter Evaluierungen sicher und bietet außerdem eine intuitive Benutzeroberfläche für Feedback durch reale Personen.
Modellbereitstellung
Einheitliche Implementierung für Agents, GenAI und klassische ML-Modelle.
Model Training
Optimierung von Open-Source-LLMs, Pretraining maßgeschneiderter LLMs und Erstellung klassischer ML-Modelle.
Databricks Notebooks
Steigern Sie die Teamproduktivität mit Databricks Collaborative Notebooks und ermöglichen Sie Echtzeit-Zusammenarbeit und optimierte Data-Science-Workflows.
Managed MLflow
Ergänzt MLflow, eine einheitliche MLOps-Open-Source-Plattform zum Erstellen besserer Modelle und GenAI-Apps, um Zuverlässigkeit, Sicherheit und Skalierbarkeit auf Unternehmensniveau.
Überwachung der Datenqualität
Einfaches, skalierbares Monitoring, das Anomalien erkennt, die Aktualität nachverfolgt und konsistente Qualitätssignale für alle Daten- und KI-Assets liefert.
Die Databricks Data Intelligence-Plattform
Entdecken Sie die gesamte Bandbreite der auf der Databricks Data Intelligence Platform verfügbaren Tools zur nahtlosen Integration von Daten und KI in Ihrem Unternehmen.
Hochwertige Agent-Systeme erstellen

Daten mühelos transformieren
Datenaufbereitung mit nahtloser Integration für GenAI- und ML-Workflows
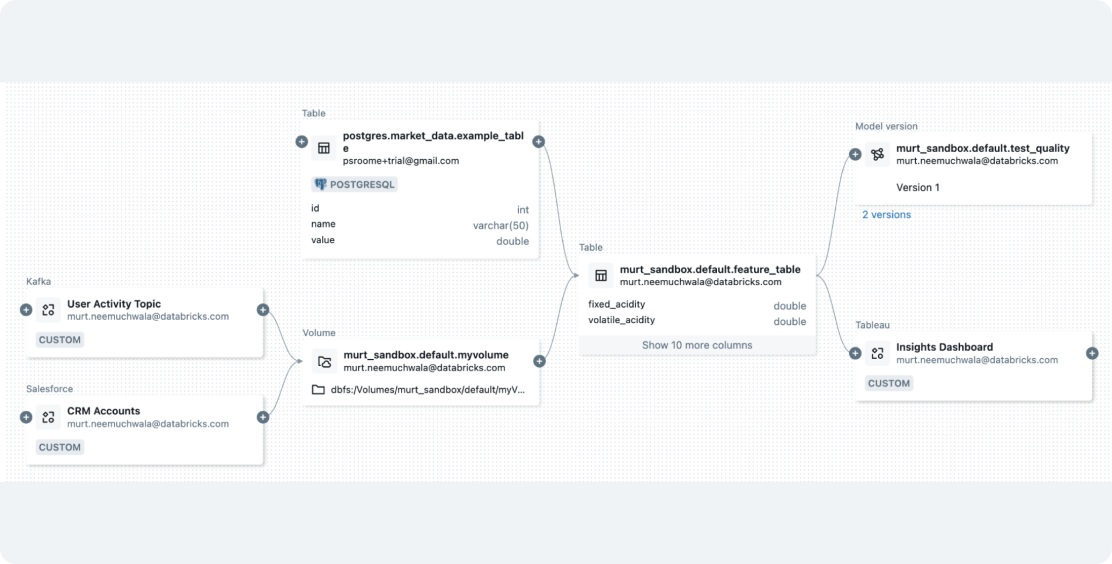
Mit Databricks können Sie beliebige Datentypen erfassen und Jobs orchestrieren, um sie für Ihre GenAI- oder ML-Anwendungen vorzubereiten. Dank integrierter Governance wird die Datenauswertung vereinfacht und es werden Vektorindizes für RAG mithilfe von Databricks AI Search erstellt. Dies trägt zur Vereinheitlichung von Daten- und Modellpipelines bei, um Workflows zu optimieren und Kosten zu senken.

Wagen Sie den nächsten Schritt
Kostenlose GenAI-Schulung
Vertiefen Sie Ihre GenAI-Kenntnisse mit diesem Kurs zum Selbststudium – und erwerben Sie ein branchenweit anerkanntes Abschlusszertifikat von Databricks.
Einstiegshandbuch
Dieses Tutorial zu KI-Agents begleitet Sie vom Proof-of-Concept (POC) bis hin zu einer hochwertigen, produktionsreifen Anwendung mit Databricks.




Häufig gestellte Fragen zu Databricks
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Transformation