Mosaic AI Agent Framework
Entwickeln von RAG-Apps (Retrieval Augmented Generation) in Produktionsqualität


Retrieval Augmented Generation (RAG) ist ein GenAI-Anwendungsmuster. RAG findet Daten/Dokumente, die für eine Frage oder einen Task relevant sind, und stellt sie als Kontext für Large Language Models (LLMs) bereit, um präzisere Antworten geben zu können.
Mosaic AI Agent Framework ist eine Tool-Sammlung, die Entwicklern dabei hilft, leistungsfähige GenAI-Anwendungen mit RAG zu erstellen und zu implementieren, deren Ergebnisse konsequent gemessen und auf Richtigkeit, Sicherheit und Governance geprüft werden. Mit Mosaic AI Agent Framework können Entwickler die Qualität ihrer RAG-Anwendung bequem bewerten, schnell iterieren, ihre Hypothesen testen und ihre Anwendung ganz einfach neu bereitstellen. Dabei nutzen sie angemessene Governance und alle erforderlichen Schutzmaßnahmen, um kontinuierlich höchste Qualität zu gewährleisten.
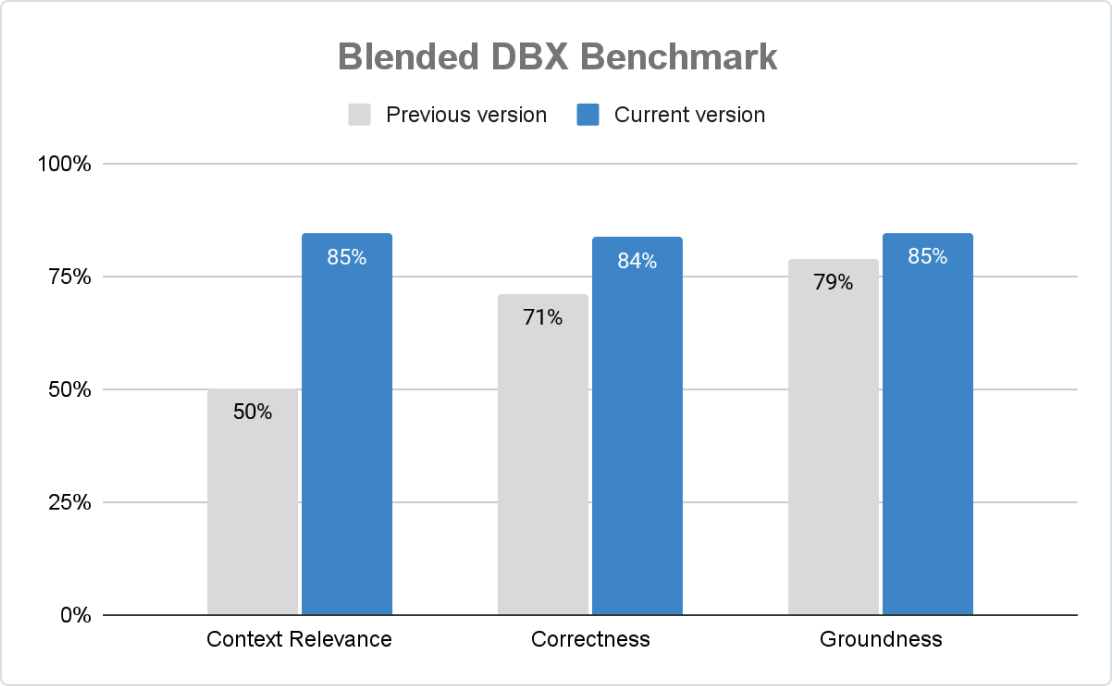
Höchste Produktionsqualität
Agent Framework sorgt für präzise, sichere und regelkonforme GenAI-Anwendungen im großen Maßstab. Mit Mosaic AI Agent Evaluation können Unternehmen Bewertungskriterien individuell anpassen – mithilfe von regelbasierten Checks, LLM-Jurys und menschlichem Feedback. Eine integrierte, KI-gestützte Auswertung sowie eine intuitive Benutzeroberfläche fördern die kontinuierliche Verbesserung.
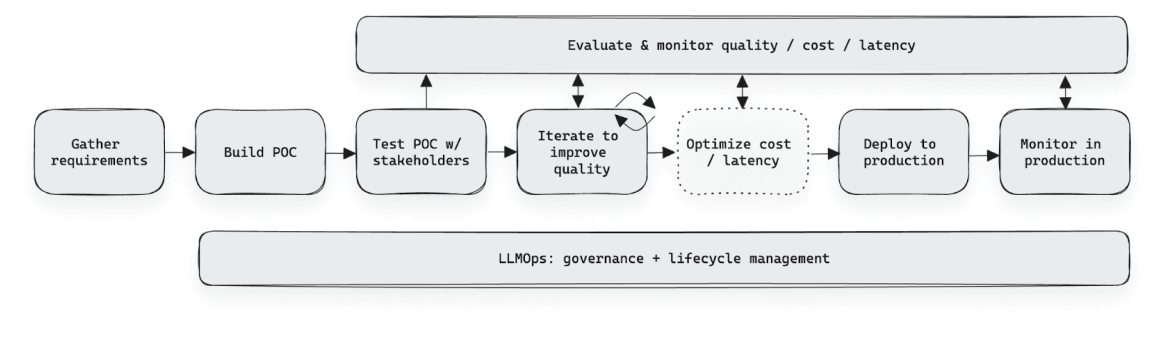
Schnelle Entwicklungsiteration
Das Agent Framework beschleunigt die Entwicklung von GenAI-Anwendungen, indem es die Feedback-Erhebung und Auswertung vereinfacht. Mit der Agent Evaluation Review App können Fachexpertinnen und -experten Bewertungen vornehmen, Label vergeben und Kriterien definieren – ganz ohne Tabellen oder Spezialtools. Dank des strukturierten Feedbacks können Teams die Modellgenauigkeit verbessern, Schwächen gezielt beheben und neue Versionen sicher und regelkonform ausrollen, ohne dass dafür Anpassungen im Code erforderlich sind.
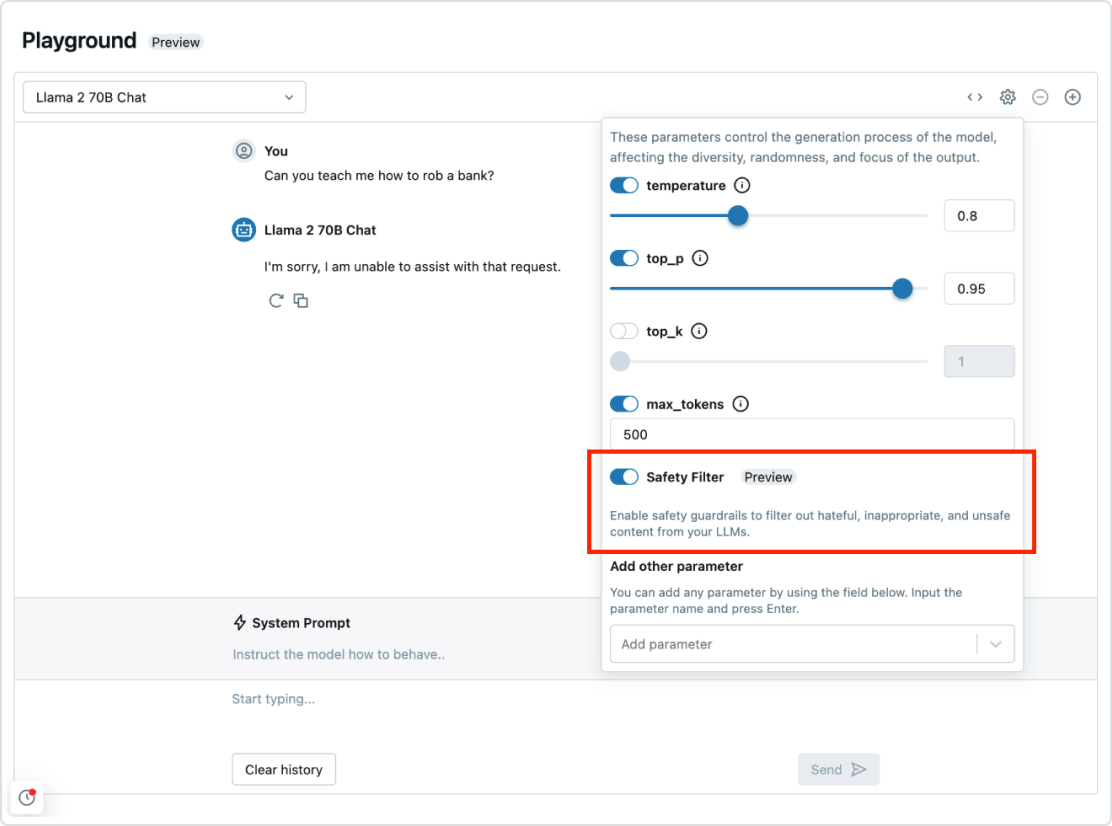
Governance und Schutzeinrichtungen
Mosaic AI Agent Framework fügt sich nahtlos in die übergeordnete Databricks Data Intelligence Platform ein. So steht Ihnen alles zur Verfügung, was Sie für die Implementierung eines kompletten RAG-Systems brauchen: von Sicherheit und Governance bis hin zu Datenintegration, Vektordatenbanken, Qualitätsbewertung und optimierter Bereitstellung per Mausklick. Mit Governance und implementierten Sicherheitsfunktionen können Sie auch toxische Antworten abfangen und gewährleisten, dass Ihre Anwendung den Unternehmensvorgaben entspricht.
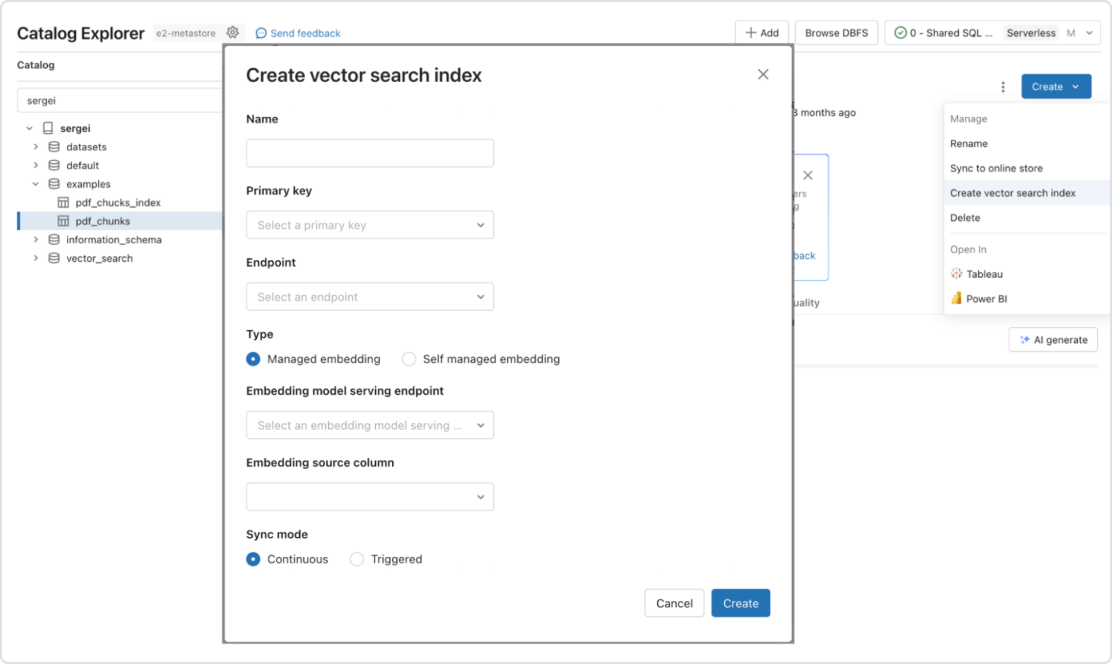
Automatisierte Echtzeit-Pipeline für beliebige Datentypen
Mosaic AI unterstützt nativ die Bereitstellung und Indizierung Ihrer Daten für den Online-Abruf. Unstrukturierte Daten (Text, Bilder und Videos) werden von Vector Search automatisch indiziert und bereitgestellt. So werden sie für RAG-Anwendungen zugänglich, ohne dass separate Datenpipelines erstellt werden müssten. Im Hintergrund verwaltet Vector Search Ausfälle, verarbeitet Wiederholungsversuche und optimiert die Batch-Größen, um Ihnen beste Leistung, maximalen Durchsatz und niedrigste Kosten zu bieten. Für strukturierte Daten stellt Feature and Function Serving Abfragen von Kontextdaten im Millisekundenbereich bereit, z. B. Benutzer- oder Kundendaten, die Unternehmen häufig in Prompts einfügen, um sie auf der Grundlage von Benutzerinformationen anzupassen.
