Apache Spark™ 3.4 for Databricks Runtime 13.0の紹介

Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
Original Blog : Introducing Apache Spark™ 3.4 for Databricks Runtime 13.0
(翻訳: junichi.maruyama )
本日、Databricks Runtime 13.0の一部として、Databricks上でApache Spark™ 3.4が利用可能になったことを発表します。Spark 3.4のリリースに多大な貢献をされたApache Sparkコミュニティーの皆様に心より感謝申し上げます。
Sparkのさらなる統一、Sparkをどこでも使えるアプリケーションの実現、生産性の向上、使い方の簡素化、新機能の追加を目的として、Spark 3.4では以下のような新機能を導入しています:
- Spark Connectを使えば、どんなアプリケーションからでも、どこからでもSparkに接続できます。
- 複数のテーブル形式のカラムDEFAULT値、タイムゾーンなしのタイムスタンプ、UNPIVOT、カラムエイリアス参照によるクエリの簡素化など、新しいSQL機能により生産性が向上します。
- 新しいPySparkエラーメッセージフレームワークとSparkエクゼキュータメモリプロファイリングにより、Python開発者のエクスペリエンスを向上させました。
- ストリーミングの改善により、パフォーマンスが向上し、クエリの数が減り、中間ストレージが不要になることでコストが削減され、カスタムロジックのための任意のステートフル操作のサポート、Protobuf形式のレコードの読み取りと書き込みのネイティブサポートが可能になります。
- PySparkユーザーがSparkクラスター上でPyTorchを使った分散トレーニングを行えるようにします。
本ブログでは、Apache Spark 3.4.0のトップレベルの機能と強化された機能の概要を説明します。これらの機能の詳細については、今後のブログポストで詳しく説明しますので、ぜひご覧ください。また、すべてのSparkコンポーネン��トの主要な機能と解決されたJIRAチケットの包括的なリストに興味がある場合は、Apache Spark 3.4.0 リリースノートをチェックすることをお勧めします。
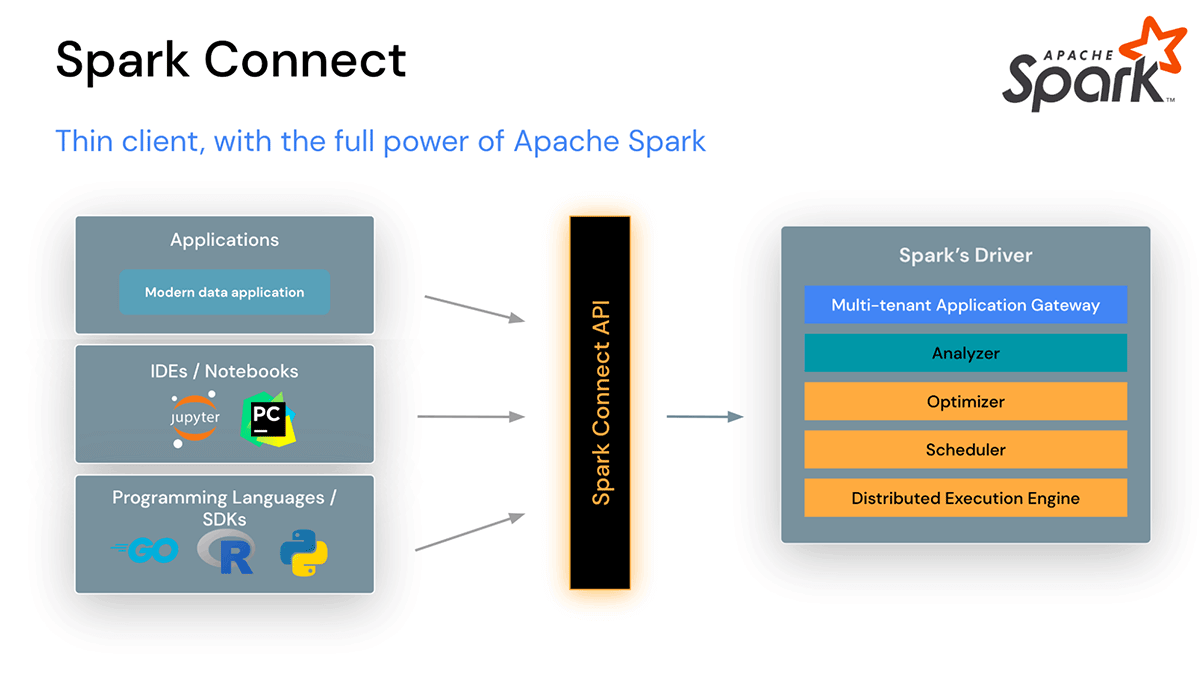
Spark Connect
Apache Spark 3.4では、Spark Connectがクライアントとサーバーを分離したアーキテクチャを導入し、任意のアプリケーションからSparkクラスタへのリモート接続を可能にしました。このクライアントとサーバーの分離により、最新のデータアプリケーション、IDE、ノートブック、およびプログラミング言語がSparkに対話的にアクセスできるようになります。Spark Connectは、Spark DataFrame API(SPARK-39375)のパワーを活用します。
Spark Connectを使用すると、クライアントアプリケーションはSparkクラスタの外部で実行できるため、自身の環境に影響を与えるだけで、Sparkドライバの依存関係の衝突がなくなり、組織はSparkのアップグレード時にクライアントアプリケーションに変更を加える必要がなくなり、開発者はIDEで直接クライアント側のステップスルーデバッグを行うことができる。
Spark Connectは、今後リリースされるDatabricks Connectを強化します。
PyTorch MLモデルに対する分散学習
Apache Spark 3.4では、PySparkにTorchDistributorモジュールが追加され、Sparkクラスター上でPyTorchによる分散トレーニングを行うことができるようになりました。このモジュールでは、環境とワーカー間の通信チャネルを初期化し、CLIコマンドのtorch.distributed.runを利用して、ワーカーノード間で分散トレーニングを実行します。このモジュールは、シングルノードのマルチGPUクラスタとマルチノードのGPUクラスタの両方でトレーニングジョブの分散をサポートしています。以下は、その使用方法のコード例です:
詳細とサンプルノートブックについて, see https://docs.databricks.com/machine-learning/train-model/distributed-training/spark-pytorch-distributor.html
生産性の向上
テーブルのカラムのDEFAULT値のサポート(SPARK-38334): SQLクエリで、CSV、JSON、ORC、Parquet形式のテーブルのカラムのデフォルト値を指定できるようになりました。この機能は、テーブルの作成時または作成後に動作します。その後の INSERT、UPDATE、DELETE、MERGE コマンドは、明示的な DEFAULT キーワードを使用して、任意の列のデフォルト値を参照することができます。また、INSERTの割り当てにターゲットテーブルより少ない列のリストが明示されている場合、対��応する列のデフォルト値が残りの列に代入されます(デフォルトが指定されていない場合はNULLとなります)。
例えば、新しいテーブルを作成するときに、カラムにDEFAULT値を設定する:
また、これらの例に示すように、UPDATE、DELETE、MERGEステートメントで列のデフォルトを使用することも可能です:
タイムゾーンを持たない新しいタイムスタンプ値 (SPARK-35662): Apache Spark 3.4では、タイムゾーンを持たないタイムスタンプ値を表現するための新しいデータ型が追加されました。これまで、Sparkの既存のTIMESTAMPデータ型を使ってSQLクエリーに組み込んだり、JDBCで渡したりして表現された値は、セッションのローカルタイムゾーンであると仮定され、処理前にUTCにキャストされました。このようなセマンティクスは、カレンダーを扱うようないくつかのケースでは望ましいのですが、ログファイルなど、タイムゾーンに依存しないタイムスタンプ値を表現したいケースも多くあります。このため、Sparkには新しいTIMESTAMP_NTZデータ型が含まれています。
Lateral Column Alias References(横列エイリアス参照) (SPARK-27561): Apache Spark 3.4では、SQLのSELECTリストで横方向のカラム参照を使用して、前の項目を参照できるようになりました。この機能により、クエリを作成する際に、複雑なサ��ブクエリや一般的なテーブル式を書く必要性がなくなり、非常に便利になりました。
Dataset.to(StructType) (SPARK-39625): Apache Spark 3.4では、ソースデータフレーム全体を指定されたスキーマに変換するDataset.to(StructType)という新しいAPIが導入されました。その動作は、入力クエリをテーブルスキーマに合わせて調整するテーブル挿入に似ていますが、インナーフィールドに対しても動作するように拡張されています。これには以下のようなものがあります:
- 指定されたスキーマに合わせてカラムとインナーフィールドの並び替えを行う
- 指定されたスキーマで必要とされないカラムやインナーフィールドを遠ざける
- カラムとインナーフィールドをキャストして、期待されるデータ型と一致させる
パラメータ化されたSQLクエリ (SPARK-41271, SPARK-42702): Apache Spark 3.4では、パラメータ化されたSQLクエリを構築する機能がサポートされました。これにより、クエリの再利用性が向上し、SQLインジェクション攻撃を防止してセキュリティを向上させることができます。SparkSession APIは、キーがパラメータ名、値がScala/Javaリテラルであるマップを受け取るsqlメソッドのオーバーライドで拡張されました:
この拡張により、SQLテキストはリテラル値のような定数が許されるあらゆる位置に、名前付きパラメータを含めることができるようになりました。
以下は、この方法でSQLクエリをパラメータ化した例です:
UNPIVOT / MELT操作 (SPARK-39876, SPARK-38864): バージョン3.4まで、Apache SparkのDataset APIはPIVOTメソッドを提供していましたが、その逆のMELTメソッドは提供していませんでした。後者は、PIVOTによって生成されたワイドフォーマットから元のロングフォーマットにDataFrameをピボット解除する機能を提供し、オプションで識別子のカラムを設定したままにすることができるようになりました。これは、groupBy(...).pivot(...).agg(...)の逆で、集計は逆にはできないことを除きます。この操作は DataFrameをいくつかの列が識別子列であり、他のすべての列(「値」)が行に「ピボット解除」され、指定された名前の非識別子列が2つだけ残る形式にするのに便利です。
OFFSET句 (SPARK-28330, SPARK-39159): Apache Spark 3.4では、SQLクエリでOFFSET句を使用できるようになったのです。このバージョン以前は、LIMIT句を使って�クエリを発行し、戻ってくる行の数を制限することができました。しかし、OFFSET句を使用すると、最初のN行を破棄することもできます!Apache Spark™は、この操作に必要な作業量を最小限に抑えるために、効率的なクエリプランを作成し実行します。これはページネーションによく使われますが、他の目的にも使えます。
FROM句のテーブル値ジェネレータ関数 (SPARK-41594): 2021年現在、標準SQLは ISO/IEC 19075-7:2021 - Part 7: Polymorphic table functionsのセクションで、テーブル値関数を呼び出すための構文をカバーしています。Apache Spark 3.4では、この構文がサポートされ、標準的な方法でデータのコレクションを簡単に照会および変換できるようになりました。既存および新規の組み込みテーブル値関数は、この構文をサポートしています。
NumPyインスタンスの公式サポート (SPARK-39405): NumPyインスタンスがPySparkで正式にサポートされたので、NumPyインスタンスでDataFrame(spark.createDataFrame)を作成し、SQL式の入力として提供したり、MLにも利用できるようになりました。
ETL を実行する

デベロッパーエクスペリエンスの向上
エラークラスに対するSQLSTATEの使用方法を強化 (SPARK-41994): データベース管理システム業界では、SQLクエリやコマンドの戻り状態をSQLSTATEと呼ばれる5バイトのコードで表現することが標準になっています。こうすることで、複数のクライアントとサーバーが互いに通信する方法を標準化し、実装を簡素化することができます。これは、JDBCやODBC接続で送信されるSQLクエリやコマンドに特に当てはまります。Apache Spark 3.4では、コミュニティで期待されているものと一致するSQLSTATE値を含むように更新することで、エラーケースの大部分をこの標準に準拠させることができます。例えば、SQLSTATE値22003は数値の範囲外を表し、22012はゼロによる除算を表しています。
エラーメッセージの改善 (SPARK-41597, SPARK-37935): より多くのSpark例外が新しいエラーフレームワーク(SPARK-33539)に移行され、エラーメッセージの品質が向上しました。また、PySparkの例外は新しいフレームワークを活用し、エラークラスとコードが分類されているため、例外が発生したときに特定のエラーケースに対して望ましい動作を定義できるようになりました。
PySparkのユーザー定義関数のメモリプロファイラ (SPARK-40281): PySparkのユーザー定義関数のメモリプロファイラには、もともとSparkの実行ファイルのプロファイリングサポートがありませんでした。プログラムの性能の重要な要素の1つであるメモリが、PySparkのプロファイリングには欠けていたのです。Sparkドライバ上で実行されるPySparkプログラムは、他のPythonプロセスと同様に他のプロファイラで簡単にプロファイリングできますが、Sparkエグゼキュータ上のメモリを簡単にプロファイリングする方法がありませんでした。PySparkにはメモリプロファイラが搭載され、ユーザーはUDFを一行ずつプロファイルし、メモリ消費を確認することができます。
ストリーミングの改善
Project Lightspeed: Apache Sparkでより速く、よりシンプルなストリーム処理を実現するために、Spark 3.4ではさらなる改良を加えています。
オフセット・マネジメント - お客様のワークロードプロファイリングと性能実験によると、オフセット管理オペレーションは、特定のパイプラインの実行時間の30~50%を占めることがあります。これらの操作を非同期化し、設定可能なケイデンスで実行することで、実行時間を大幅に改善することができます。
複数のステートフルオペレーターをサポート - ユーザーは、ステートフルな操作(集約、重複排除、ストリームストリーム結合など)を同じクエリで複数回実行できるようになり、タイムウィンドウ集約の連鎖も可能になりました。これにより、ユーザーは、中間ストレージを挟んで複数のストリーミングクエリーを作成する必要がなくなり、インフラストラクチャやメンテナンスの追加コストが発生するほか、パフォーマンスもあまり良くありません。なお、これはappendモードでのみ機能します。
Python 任意ステートフル処理 - Spark 3.4以前のPySparkは、任意のステートフル処理をサポートしておらず、複雑でカスタムなステートフル処理ロジックを表現する必要がある場合は、Java/Scala APIを使用する必要がありました。Apache Spark 3.4からは、PySparkで直接ステートフルな複雑な関数を表現できるようになりました。詳細については、Python Arbitrary Stateful Processing in Structured Streaming のブログポストを参照してください。
Protobufのサポート - Protobufのネイティブサポートは、特にストリーミングのユースケースで高い需要がありました。Apache Spark 3.4では、組み込みのfrom_protobuf()関数とto_protobuf()関数を使用して、Protobuf形式のレコードの��読み取りと書き込みができるようになりました。
Apache Spark 3.4でのその他の改善点
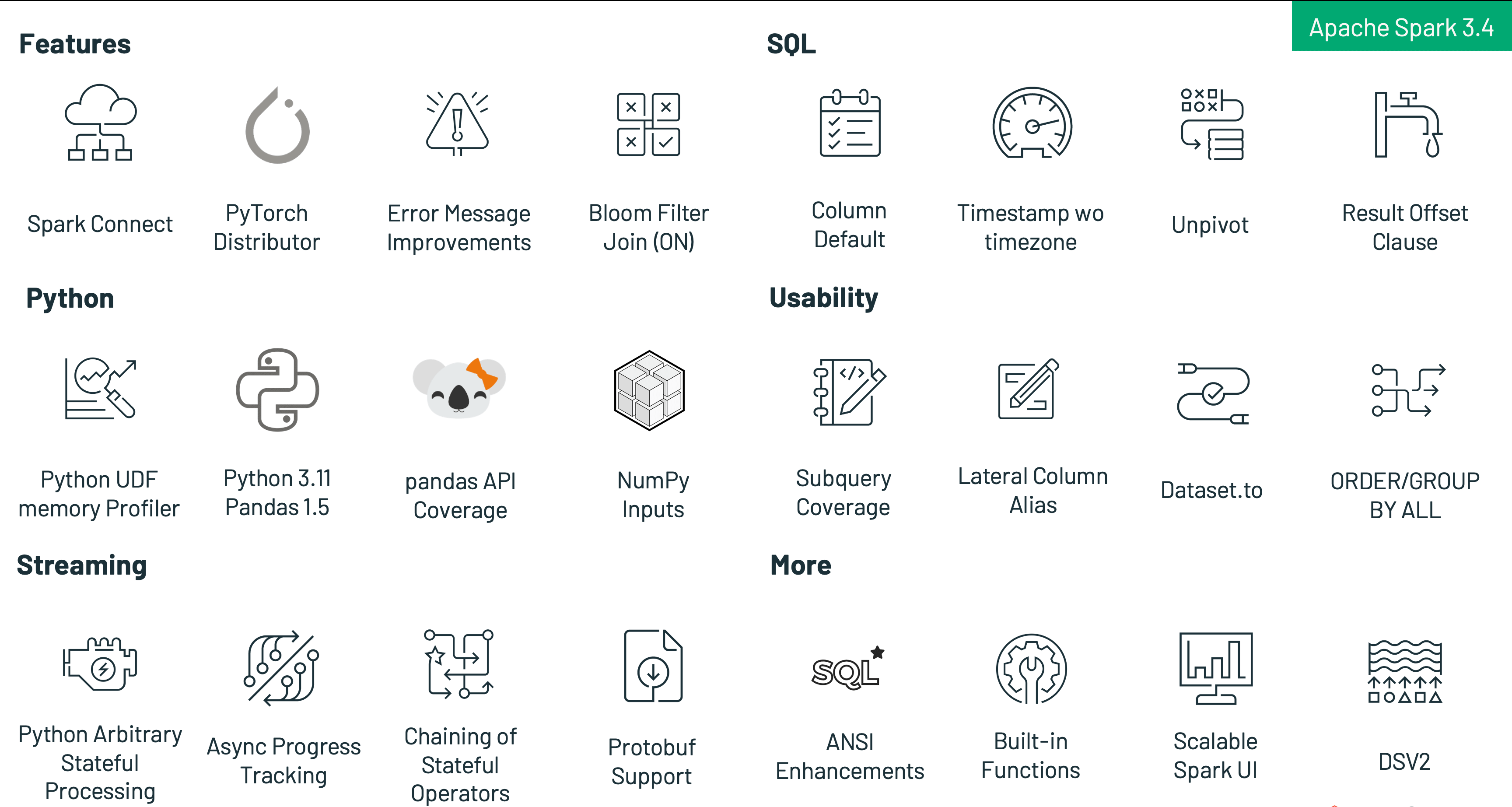
新機能の導入に加え、Sparkの最新リリースでは、ユーザビリティ、安定性、洗練性を重視し、約2600件の問題を解決しています。Databricks、LinkedIn、eBay、Baidu、Apple、Bloomberg、Microsoft、Amazon、Googleなど、個人と企業の両方で270人以上の貢献者が、この成果に貢献しました。このブログ記事では、Spark 3.4の注目すべきSQL、Python、ストリーミングの進化に焦点を当てていますが、このマイルストーンにはここで取り上げていない様々な改良点があります。ブルームフィルタ結合の一般的な利用可能性、スケーラブルなSpark UIバックエンド、より良いpandas APIカバーなど、これらの追加機能については、リリースノートで詳しく知ることができます。
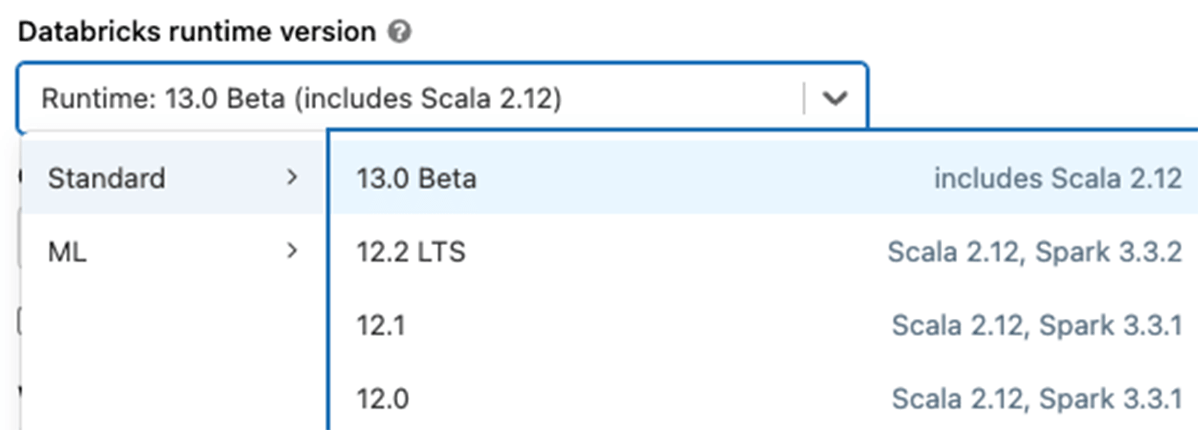
Databricks Runtime 13.0上でApache Spark 3.4を試すには、無料のDatabricks Community EditionまたはDatabricks Trialにサインアップすることで簡単にできます。一度アクセスすれば、Spark 3.4でクラスタを立ち上げるのは、バージョン "13.0 "を選択するだけと簡単です。この簡単なプロセスにより、数分でSpark 3.4の使用を開始することができます。