構造化ストリーミングにおける複数のステートフルオペレーター

翻訳:Junichi Maruyama. - Original Blog Link
データエンジニアリングの世界では、ETLが誕生したときから使われているオペレーションがある。フィルターする。結合する。集約する。最後に結果を書く。これらのデータ操作は時代が変わっても変わりませんが、レイテンシーとスループットの要求範囲は劇的に変化しています。一度に数イベントを処理したり、1日に数ギガバイトを処理したりすることは、もはや不可能です。今日のビジネス要件を満たすには、テラバイト、あるいはペタバイトのデータを毎日処理する必要があり、そのレイテンシは分単位、秒単位で測定されます。
Apache SparkTMの構造化ストリーミングは、大容量データと低レイテンシに最適化されたオープンソースの��主要ストリーム処理エンジンであり、Databricks Lakehouseをストリーミングに最適なプラットフォームとするコアテクノロジーです。Project Lightspeedで提供される強化された機能のおかげで、単一のストリーム内でこれらの古典的なデータ操作をすべて実行できるようになりました。
Databricks Runtime 13.1および次期リリースApache SparkTM 3.5.0から、ストリームに複数のステートフルオペレータを含めることができるようになりました。結合後にシンクに書き出し、データを別のストリームに読み込んで集約する必要がなくなりました。複数のストリームに分割する代わりに、1つのストリーム内で結合と集約を実行することで、複雑さ、待ち時間、コストを削減できます。この投稿では、ステートフル・ストリーミングの概念を簡単に説明し、このエキサイティングな機能の例を紹介する!
ステートフル・オペレーターとは?
構造化ストリーミングは、マイクロバッチと呼ばれる一度に小バッチのデータに対して操作を実行する。構造化ストリーミングの演算子は、ステートレスとステートフルの2つのカテゴリーに分けられる。
ステートレス・ストリームは、以前のマイクロバッチに含まれるデータについて何も知る必要のない操作を実行する。例えば、10より大きな値を持つ行だけを保持するようにレコードをフィルタリング��することは、その時点で処理されているもの以外のデータに関する知識を必要としないため、ステートレスである。
ステートフル・ストリームは、現在のマイクロバッチ内にあるもの以外の情報を必要とする処理を実行する。例えば、5分間のウィンドウで値のカウントを計算したい場合、Structured Streamingは、レコードがいくつのマイクロバッチにまたがっていても、5分分のレコードについて、集計の各キーの実行カウントを保存する必要がある。この保存されたデータはステートと呼ばれ、ステートの保存を必要とする演算子はステートフル演算子である。最も一般的なステートフル演算子は、集約、結合、重複排除である。
ウォーターマークとは?
Structured Streamingのすべてのステートフル・オペレーターは、ウォーターマークを指定する必要がある。ウォーターマークは、データの許容される遅延時間と、状態を保持する時間の2つをコントロールすることができる。
例えば、各レコードがイベントのタイムスタンプを含むデータセットを処理し、そのタイムスタンプに基づいて5分のウィンドウで集計するとしよう。あるレコードが順番通りに届かなかったらどうする?タイムスタンプが12:11のレコードを処理した後に、タイムスタンプが12:04のレコードが到着した場合、そのレコードを12:00-12:05の集計に含めるか?12:00-12:05のウィンドウの状態をいつまで維持するのか?もし定期的にパージしなければ、ステート・データは最終的にメモリーを満杯にし、パフォーマンス低下の原因になる。そこでウォーターマークの出番だ。
.withWatermark設定を使うことで、レコードが何秒、何分、何時間、�何日遅れてもよいかを指定することができ、その結果、Structured Streamingはステートに保存されたレコードが不要になったタイミングを知ることができます。この例では、データのevent_timestampカラムに基づいて、10分遅れまでデータを受け付けることを指定しています:
Structured Streamingは、受信した最新のイベントタイムスタンプからwithWatermark設定で指定された時間間隔を差し引くことで、各マイクロバッチの終了時にウォーターマークタイムスタンプを計算して保存する。各マイクロバッチの開始時に、受信レコードのイベントタイムスタンプと、現在ステートにあるデータとを、ウォーターマークタイムスタンプと比較する。ウォーターマークの値よりも早いタイムスタンプを持つ入力レコードとステートは取り除かれる。
このウォーターマークの仕組みにより、Structured Streamingは、1つのストリームにステートフルな演算子がいくつあっても、遅いレコードやステートを適切に処理することができる。以下の例では、ウォーターマークが使用されているのを見ることができる。
Examples
さて、ステートフル演算子とはどのようなものかを大まかに理解したところで、実際にいくつか使ってみましょう。同じストリームで複数のステートフル演算子を使用する方法の例をいくつか見ていきましょう。
連鎖したタイムウインドウ集約
この例では、生のイベントのストリームを受け取っている。10分ごとに発生したイベントの数をユーザーごとにカウントし、結果を書き出す前に、それらのカウントを時間ごとに平均したい。そのためには、2つのウィンド��ウ集約を連鎖させる必要がある。
まず、標準的な readStream 呼び出しを使って、userId, eventTimestamp 形式のソースデータを読み込みます:
Structured Streamingに付属しているストリーミング・ソースのどれでも、ここで使うことができる。
次に、userId に対して最初のウィンドウ集約を実行します。ウィンドウのベースとなるタイムスタンプカラムとウィンドウの長さを定義することに加えて、Structured Streaming に、結果が出力されステートがドロップされるまでの遅いデータの待ち時間を指示するためのウォーターマークを定義する必要があります。我々は、データが遅れるのは1分までと決めている。これがそのコードだ:
ウィンドウ集約を行う場合、Structured Streaming は自動的に結果にウィンドウカラムを作成します。この window カラムは、ウィンドウを定義する開始タイムスタンプと終了タイムスタンプを持つ構造体です。1時間後の userId 1 と userId 2 の出力は以下のようになります:
| window | userId | count |
|---|---|---|
| {"start": "2023-06-02T11:00:00", "end": "2023-06-02T11:10:00"} | 1 | 12 |
| {"start": "2023-06-02T11:00:00", "end": "2023-06-02T11:10:00"} | 2 | 7 |
| {"start": "2023-06-02T11:10:00", "end": "2023-06-02T11:20:00"} | 1 | 8 |
| {"start": "2023-06-02T11:10:00", "end": "2023-06-02T11:20:00"} | 2 | 16 |
| {"start": "2023-06-02T11:20:00", "end": "2023-06-02T11:30:00"} | 1 | 5 |
| {"start": "2023-06-02T11:20:00", "end": "2023-06-02T11:30:00"} | 2 | 10 |
| {"start": "2023-06-02T11:30:00", "end": "2023-06-02T11:40:00"} | 1 | 15 |
| {"start": "2023-06-02T11:30:00", "end": "2023-06-02T11:40:00"} | 2 | 6 |
| {"start": "2023-06-02T11:40:00", "end": "2023-06-02T11:50:00"} | 1 | 9 |
| {"start": "2023-06-02T11:40:00", "end": "2023-06-02T11:50:00"} | 2 | 19 |
| {"start": "2023-06-02T11:50:00", "end": "2023-06-02T12:00:00"} | 1 | 11 |
| {"start": "2023-06-02T11:50:00", "end": "2023-06-02T12:00:00"} | 2 | 17 |
これらのカウントを時間ごとに平均化するには、上記のwindow列のタイムスタンプを使用して別のwindow集計を定義する必要がある。複数のステートフル・オペレータを有効にする前は、この時点で、次の図に示すように、上記の結果を writeStream でシンクに書き出し、そのデータを新しいストリームに読み込んで 2 番目の集約を実行する必要がありました。
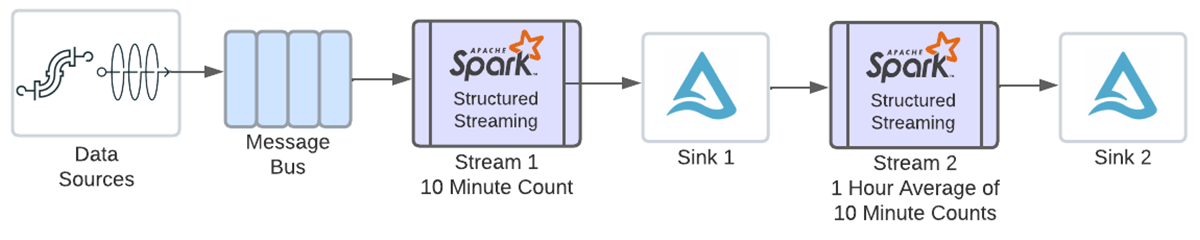
この新機能のおかげで、同じストリームで両方の操作を連鎖させることができるようになった。
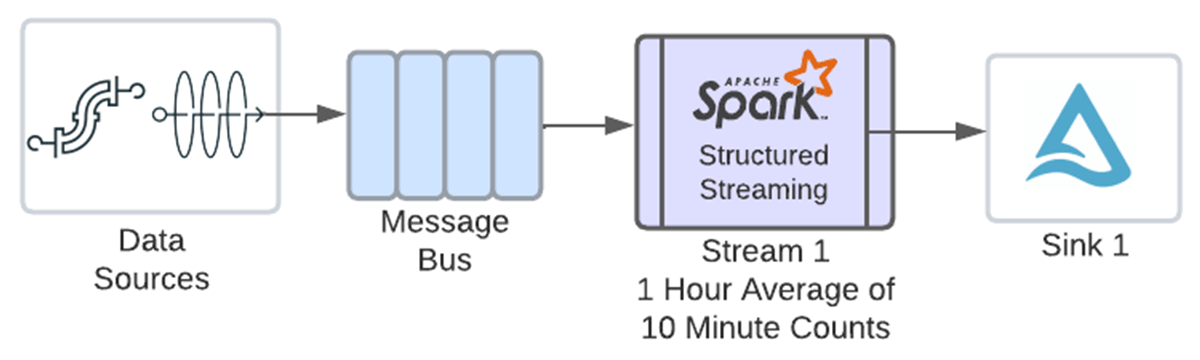
ウィンドウ集約を簡単に連鎖させるために、前の集約で作成したウィンドウ列を直接ウィンドウ関数に渡せる便利な構文を追加しました。以下のコードでは、eventCount.window カラムが渡されているのがわかります。これで、window関数はwindow列の構造体を適切に解釈し、その構造体を使用して別のウィンドウを作成できるようになります。これは1時間のウィンドウを定義し、カウントを平均化します。入力ソースは1つだけであり、そのウォーターマークは前の集計の前に指定されているため、別のウォーターマークを定義する必要はないことに注意してください:
2回目の集計後、userId1と2のデータは以下のようになる:
| window | userId | avg |
|---|---|---|
| {"start": "2023-06-02T11:00:00", "end": "2023-06-02T12:00:00"} | 1 | 10 |
| {"start": "2023-06-02T11:00:00", "end": "2023-06-02T12:00:00"} | 2 | 12.5 |
最後に、writeStreamを使ってDataFrameをシンクに書き出します。この例ではデルタ・テーブルに書き込んでいる:
”アペンド” 出力モードをサポートするシンクであれば、どのシンクでもサポートされる。アペンドモードを使用しているので、ウィンドウが閉じるまで、指定されたウィンドウのデータはシンクに書き込まれない。ウィンドウは、ウォーターマークの値がウィンドウ定義の終了時刻+許容遅延時間よりも遅くなるまで閉じません。上記の1時間ウィンドウの例では、イベントのタイムスタンプが12:01より後のデータを受信し始めると、ウォーターマークの値は、定義されたウィンドウの終了時刻に許容される遅延時間を1分足したものより後になる。そのため、ウィンドウは閉じられ、データはシンクに送られる。ウォーターマークの計算は時計の時刻とは関係なく、受信しているデータのイベントタイムスタンプに基づいている。
ウィンドウ集約によるストリーム-ストリームの時間間隔結合
この例では、2 つのストリームを結合して、1 時間のウィンドウで集計します。クリックデータを含むストリームと広告インプレッションを含むストリームを結合し、1時間ごとに広告ごとのクリック数をカウントします。
ストリーム-ストリーム結合もステートフルなオペレータです。一致するレコードは異なるマイクロバッチから来る可能性があるため、レコードは両方の結合データセットの状態に保たれます。私たちは、Structured Streamingが一定期間後にステートレコードを削除することで、ステートが無限に増えてメモリやパフォーマンスの問題を引き起こさないようにしたいと考えています。そのためには、各入力ストリームにウォーターマークを定義し、結合条件に時間間隔句を追加しなければならない。
まず、各データセットを読み込み、ウォーターマークを適用する。2つのストリームのウォーターマークは、同じ時間間隔を指定する必要はない。この例では、インプレッションは2時間遅れまで、クリックは3時間遅れまで許容する:
ここで、2つの入力ストリームを結合する。以下がそのコードである:
時間間隔句に注意してください。これは、クリックが結果の結合セットに含まれるためには、広告インプレッションから0秒から1時間以内に発生しなければならないことを示しています。この時間制約により、Structured Streamingは状態において行が不要になったタイミングを判断することができます。
結合データセットができたら、各広告について各時間帯に発生したクリックをカウントすることができます。別のウォーターマークを指定したり、集約関数に何かを追加したりする必要はありません!
最後に、結果を書��き出します。writeStream構文は前の例と同じで、クエリ名、出力場所、チェックポイントの場所が異なるだけです。
Benefits
では、複数のステートフルな演算子を連結することで、複雑さ、待ち時間、コストをどのように削減できるのだろうか?上記のストリーム-ストリーム結合とウィンドウ集約を例にしてみよう。
この機能が追加される前は、ステートフルな演算子はそれぞれ独自のストリームを必要としていたため、結合用のストリームと、最初のストリームの出力を入力として使用するウィンドウ集約用の2つ目のストリームが必要だった。両方のストリームが同じSparkクラスタ上で実行されていたとしても、オフセットやコミットのログをチェックポイントしたり、Spark UI上でプロットするためのメトリクスを追跡したりするなど、各ストリームには独自のオーバーヘッドが発生する。最初のストリームはソースデータを読み込み、結合して外部ストレージのシンクに書き出す。次に、2つ目のストリームが結合されたデータを再び読み込み、ウィンドウ集約を行い、結果を別のシンクに書き出す。ストリームは両方とも監視する必要があり、どちらかのストリームでロジックが変更されるたびに、ストリーム間の依存関係を管理する必要がある。
現在では、複数のステートフル演算子を組み合わせることができるため、結合とウィンドウ集約の両方を同じストリームに含めることができる。
- 監視するストリームが1つになり、管理するストリーム間の依存関係がなくなるため、複雑さが軽減されます。また、保存さ�れるデータセットが1つだけなので、管理するデータが少なくなる。
- 結合後の中間データセットの書き込みと、ウィンドウ集約前のデータセットの読み出しの両方がなくなるため、待ち時間が短縮される。
- 中間データセットの書き込みと読み出しがなくなり、ストリーミングのオーバーヘッドが減るため、必要な計算量が減るため、コストが削減される。また、中間データセットのストレージコストも削減される。
3つ、4つ、5つのステートフル・オペレーターがあれば、どれだけの複雑さ、レイテンシー、コストが削減されるか考えてみてほしい!
その他の考慮事項
1つのストリームで複数のステートフル演算子を使用する場合、いくつか注意すべき点がある。
- まず、「追記」出力モードを使用しなければならない。update」および「complete」出力モードは、たとえ出力先のシンクがそれらをサポートしていても、使用することはできない。アペンドモードを使用しているため、ウィンドウ集約の出力は、ウィンドウ終了タイムスタンプが透かしより小さくなるまでシンクに書き込まれません。一致しない外部結合行は、そのイベントのタイムスタンプが透かしより小さくなるまで書き込まれません。
- 次に、mapGroupsWithState、flatMapGroupsWithState、applyInPandasWithState演算子は、任意のステートフル演算子がストリームの最後のものである場合にのみ、他のステートフル演算子と組み合わせることができます。mapGroupsWithState、flatMapGroupsWithState、applyInPandsWithStateの後に他のステートフル演算を実行する必要がある場合は、最初に任意のステートフル演算をシンクに書き出し、次に2番目�のストリームで他のステートフル演算子を使用する必要があります。
- 最後に、これはステートフル・ストリーミングであり、ストリームで1つのステートフル演算子を使用する場合でも、複数のステートフル演算子を使用する場合でも、同じbest practicesが適用されることを覚えておいてください。状態を大量に保存する場合は、状態管理にocksDBを使用することを検討してください。Databricks Lakehouse Platform上で実行する場合、非同期チェックポイントと状態リバランシングを使用することで、ステートフル・ストリーミングのパフォーマンスを向上させることもできます。
まとめ
今日のビジネス要件を満たすには、これまで以上に大量のデータを高速に処理する必要があります。Project Lightspeed Databricksは、Structured Streamingのレイテンシー、機能性、コネクター、デプロイとモニタリングのシンプ��ルさなど、あらゆる面を継続的に改善しています。この最新の機能強化により、Structured Streamingのユーザーは1つのストリーム内で複数のステートフルオペレーターを使用できるようになり、レイテンシー、複雑さ、コストを削減できます。Databricks Lakehouse Platformのランタイム13.1以上、またはリリース予定のApache SparkTM 3.5.0でお試しください!



{kind=link}
{kind=link}