Databricksデータインテリジェンスプラットフォームによる"オミクス"データ管理の変革
によって アミール・カーマニー による投稿
人間のゲノムの初稿が完成してから二十年、生物学研究の風景は革命的な変化を�遂げました。ゲノム学の分野は急速に拡大し、単一細胞RNAシーケンシング、プロテオミクス、メタボロミクスなどの多様なデータタイプを含むより広範な"オミクス"革命を引き起こしています。
これらの最先端技術は、生物学的機能について最も詳細なレベルで前例のない洞察を提供し、疾患メカニズム、生物の適応、薬物や化学物質を含む環境要因との相互作用についての深い理解を提供しています。このオミクス爆発の影響は広範で、薬物発見、精密医療、農業、バイオマニュファクチャリングを革新することを約束しています。
しかし、生命科学組織の大多数は、既存のデータインフラストラクチャと使用されている技術によって引き起こされる様々な課題のために、これらの洞察を完全に活用することに苦労しています。これらの課題を克服するためには、データプラットフォームの近代化が研究開発におけるマルチオミクスの成功的な適用にとって重要です。
このブログでは、Databricks Data Intelligence Platformなどの新技術がこれらの問題にどのように対処できるかを探り、より効果的かつ効率的なマルチオミクスデータ管理の道を開く方法を探ります。
多くの組織は、既存のアーキテクチャのためにこのデータを活用することに苦労しています。
既存のデータインフラストラクチャは、マルチオミクスデータの複雑さを管理するのに苦労しており、特にデータ統合とこれらの大量データセットの分析にスケーラブルな解決策を提供することが困難です。さらに、彼らは高度な分析とAIの増加する需要に対するネイティブサポートを欠いています。
データの相互運用性、アクセシビリティ、再利用性といった問題は一般的であり、孤立したオミクスプラットフォーム間の標準化の欠如により、これらの問題はさらに悪化しています。さらに複雑なことに、組織は、厳格に規制された環境で、データのアクセシビリティと患者のプライバシー、規制遵守のバランスを取らなければなりません。
生命科学組織が直面する主要なデータ課題
現在、組織はこれらの問題にどのように対処していますか?今日、ほとんどの人々は、オミクスデータを扱うために同時に多くの技術を使用しています。しかし、この戦略にはいくつかの課題があります。
データのボリュームと複雑さ
オミクスデータは非常に大量で複雑であり、分析には高度な計算方法が必要です。例えば、マルチオミクスデータ統合のための先進的な深層学習手法の台頭に伴い、これらのデータセットの高次元性が大�きな「ノイズ」を導入し、行動可能な洞察を導き出すことを難しくすることがあります。特に、オミクス研究においては、高次元低サンプルサイズ(HDLSS)問題が挑戦的であり、機械学習(ML)モデルの過学習のリスクが、結果の一般化性を低下させる可能性があります。この問題を解決するためには、堅牢なデータ前処理と高度な計算技術が必要であり、多くの既存のデータインフラストラクチャはこれらを処理するように設計されていません。
標準化と相互運用性
異なるオミクスプラットフォーム間での共通の標準が欠如していることは、データの相互運用性と再利用性を確保する上で大きな課題を提示します。標準化されたプロトコルがなければ、多様なデータセットを一貫したフレームワークに統合することは困難な作業となります。
規制上の考慮事項
オミクスデータがアクセス可能である一方で、患者のプライバシーを保持し、HIPAAやGDPRなどの規制を遵守することは、複雑なバランスを必要とします。この課題は、データがしばしば異なる管轄区域で共有されるグローバルな研究環境ではさらに高まります。さらに、遺伝学データが診断設定で使用されたり、疾患リスク(例えば、多因子遺伝リスクスコア)を予測するための機械学習モデルの訓練に使用されるようになると、訓練プロセスの全ての側面(データ取得、品質管理、モデル訓練、説明可能性)を追跡する能力がま�すます重要になってきます。
ユーザーエクスペリエンス
製薬業界は、IT専門家、データサイエンティスト、医学研究者、そして様々な生物学的サンプルに対する複雑な実験を行うベンチサイエンティストを含む、多様な専門家へのアクセスから利益を得ています。現存するデータプラットフォームのほとんどは、異なる技術(高性能コンピューティング(HPC)、伝統的なデータウェアハウス、異なるネイティブクラウドサービス)に基づいて構築されており、オミクスデータの急速に進化する風景に適応するためには大幅な技術的メンテナンスが必要です。
また、これらのシステムの複雑さと使用に関連する急な学習曲線のため、ドメイン知識を持つ非技術的なチームメンバーが洞察にアクセスすることが阻害されます。この課題は、ライフサイエンス組織内での効果的な協力とデータ駆動型の意思決定を大きく阻害します。
GenAIアプリケーションの台頭
多オミクスデータを使用して新しい基礎モデルを訓練することは、生物医学研究と薬物発見を革新しています。例えば、単一細胞オミクスデータの台頭に伴い、scGPTやGeneformerのようなモデルは、大規模なマルチオミクスデータセットを利用して薬物反応を予測し、新たな治療ターゲットを特定し、個別化医療の進歩を推進しています。EvolutionaryScaleやProfulent.bioなどの企業は、多オミクスデータに基づいて新しい合成タンパク質を生成するための大規模言語モデル(LLMs)を訓練しています。しかし、これらのモデルを運用化することは、特に訓練効率とコスト効率性の観点から、大きな課題を提示します。大量のデータセットを処理するための計算要求は、データ管理と大規模なモデルのコスト効率の良い訓練を両立できる高度なインフラを必要とします。
オミクス用Databricksデータインテリジェンスプラットフォームの紹介
Databricks Data Intelligence Platformは、研究者やIT専門家がオミクスデータを管理する際に遭遇する複雑さを効果的に対処するための強力な基盤を提供し、マルチオミクスデータプラットフォームとして機能します。以下に、Databricksが各主要な課題を克服するためにどのように役立つかを説明します:

データのボリュームと複雑さ
Databricksは、オミクス研究に典型的な広大で複雑なデータセットを処理できるスケーラブルなクラウドインフラストラクチャ上に構築されています。Apache Sparkと高性能な計算エンジンPhotonとの統合により、Databricksはコスト効率の良い分散データ処理を可能にします。さらに、強力なデータ管理インフラストラクチャの上にML/AIスタックが構築されていることにより、データ管理と高度な分析のための別々の技術スタックを管理する手間を減らし、価値を得るまでの時間を短縮します。
DatabricksのPhotonエンジンは、Project GlowなどのSparkベースのゲノムパイプラインとツールに大幅なブーストを提供し、特にゲノムワイド関連研究(GWAS)を通じた遺伝子ターゲットの特定における大規模なゲノムデータセットの分析を加速し、簡素化します。
標準化と相互運用性
Databricksのレイクハウスアーキテクチャは、データレイクとデータウェアハウスからの非構造化、半構造化、および構造化データを統合することで、シームレスな相互運用性を実現し、Delta LakeやUnity Catalogなどのオープンソース技術に基づいた単一の統一プラットフォームを提供します。このアプローチは、多様なデータセットの統合を促進し、ベンダーロックインを減らし、異なるシステム間でのデータ統合を簡素化するためのオープンデータ形式とインターフェースをサポートします。
Databricksは、オ��ープンソース技術を活用し、一元化されたデータカタログUnity Catalogを提供することで、データが容易に発見可能でアクセス可能であり、外部システムとの統合がコンプライアンスと監査可能な方法で行えることを確保しています。これにより、研究者はFAIR原則(Findability、Accessibility、Interoperability、Reusability)を科学的データ管理に適用し、協力、再現性、データ駆動型の洞察を促進することができます。
規制上の考慮事項
Databricks Unity Catalogは、組織がHIPAAやGDPRなどの厳格な規制要件を満たすとともに、データの検索性とアクセシビリティを向上させることを可能にします。中央のメタデータリポジトリと強力なセマンティック検索機能を備えたUnity Catalogを使用すると、ユーザーはコンテキストと意味に基づいて関連するデータアセットを迅速に見つけることができます。プラットフォームの細かいアクセス制御、アイデンティティ連携、そして包括的な監査ログは、データのセキュリティとコンプライアンスを確保します。
さ�らに、Unity Catalogは、高度なメタデータ管理、タグ付け、データ系統追跡を提供し、実験の発見性と再現性を向上させます。さらに、規制遵守を確保するために、Databricksは堅牢なデータ暗号化と秘密管理機能を提供します。プラットフォームはまた、Delta Sharing Protocolなどのオープンソース技術を統合し、パーティ間での安全なデータ共有を可能にします。Databricks Clean Roomsは、データ居住要件を満たしながら、異なる組織の研究者間での安全な協力を促進します。
これらの機能は、組織が厳格なデータ保護基準を維持しながら、認証されたユーザーが分析と研究のために必要なデータを効率的に発見、アクセス、共有することを可能にします。これは、安全でコンプライアンスのある環境で、組織の境界を越えても可能です。
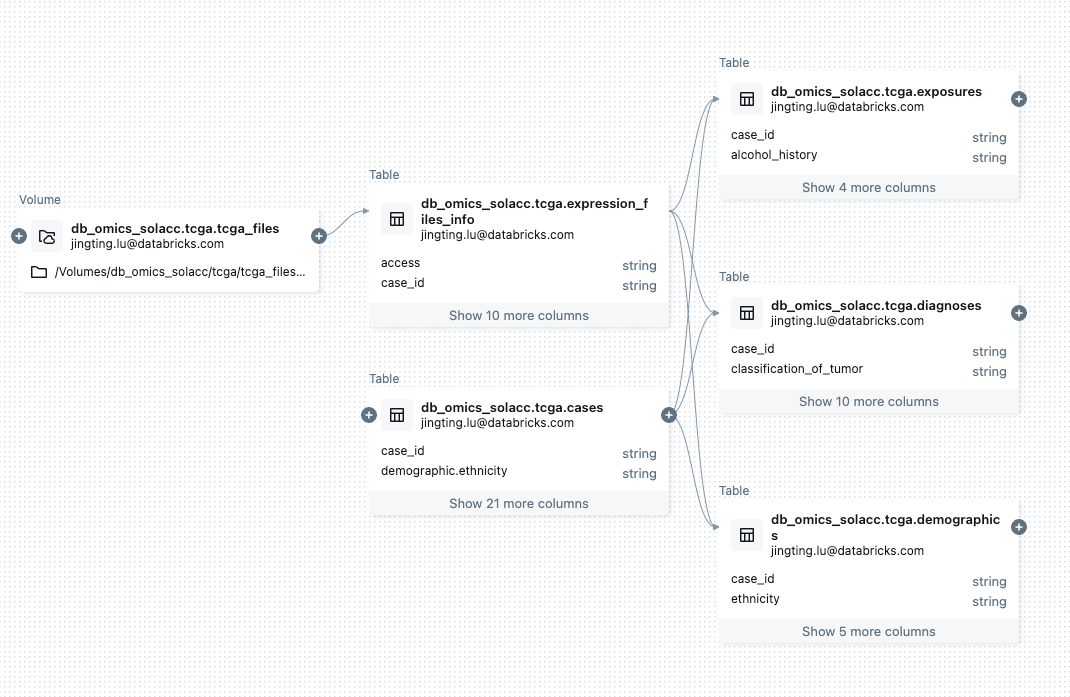
ユーザーエクスペリエンス
Databricksは、インフラストラクチャ管理を簡素化し、さまざまなデータタイプを統合する包括的な自己サービスデータプラットフォームを提供しています。ユーザーフレンドリなインターフェースは、自然言語クエリとコンテキスト認識型AIパワードアシスタンスを特徴とし、直感的なデータアクセスと分析を可能にします。このアプローチはデータとのやり取りを明確にし、プラットフォームを技術的なユーザーだけでなく、技術的な背景を持たないドメイン専門家にも利用可能にします。
Databricksは、データアクセスを簡素化し、ITオーバーヘッドを削減しながら、異なるチーム間の協力を強化することで、薬物発見と開発における意思決定とイノベーションを加速します。
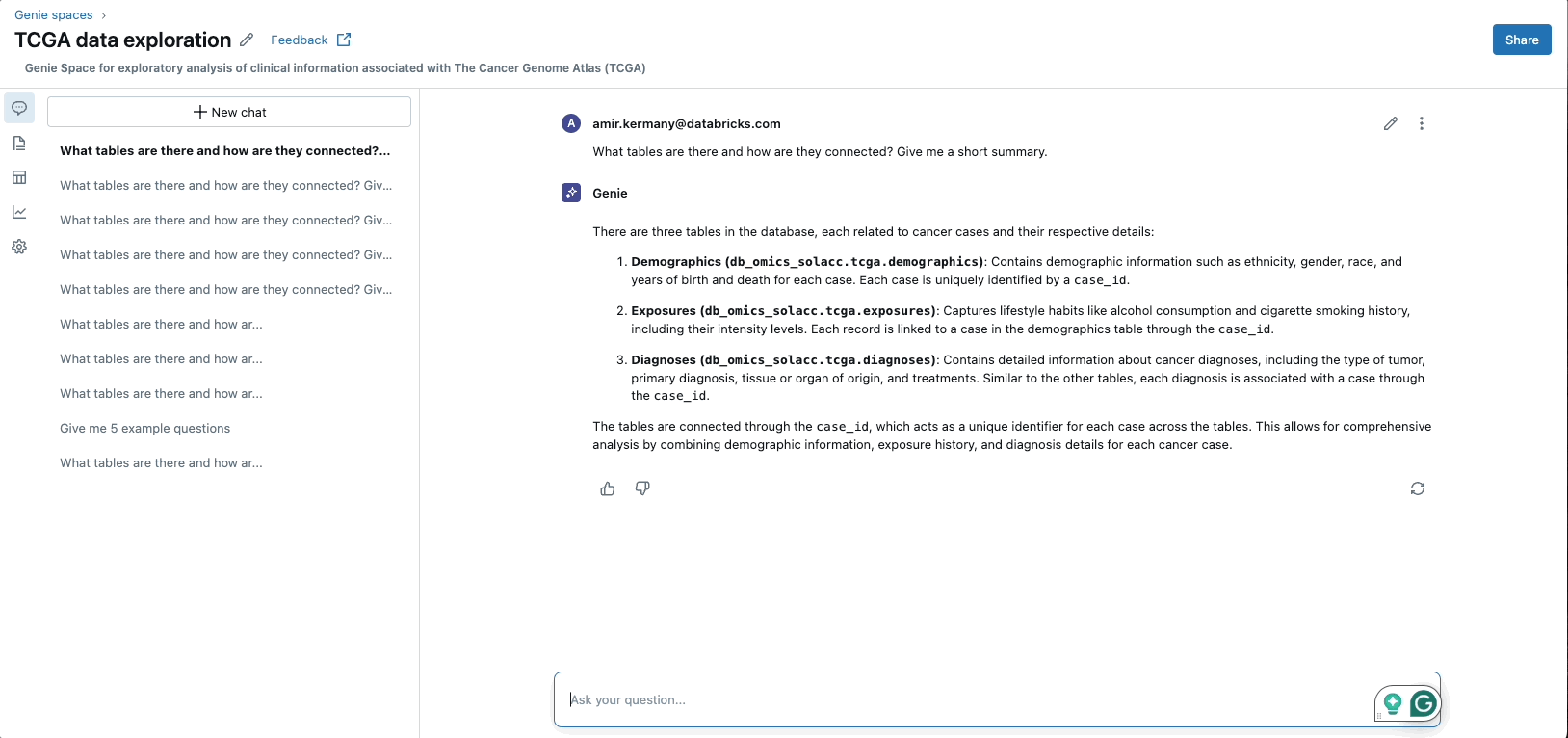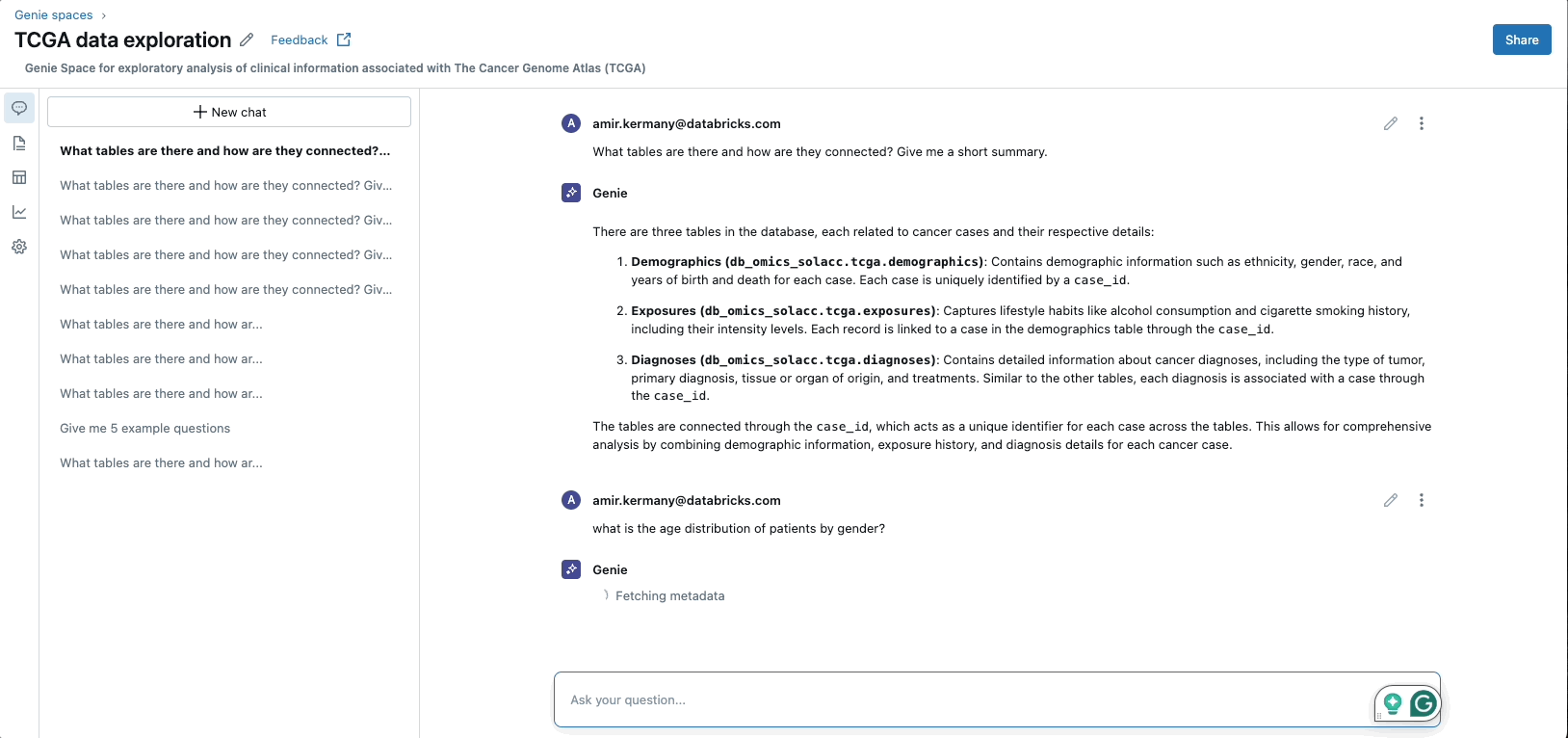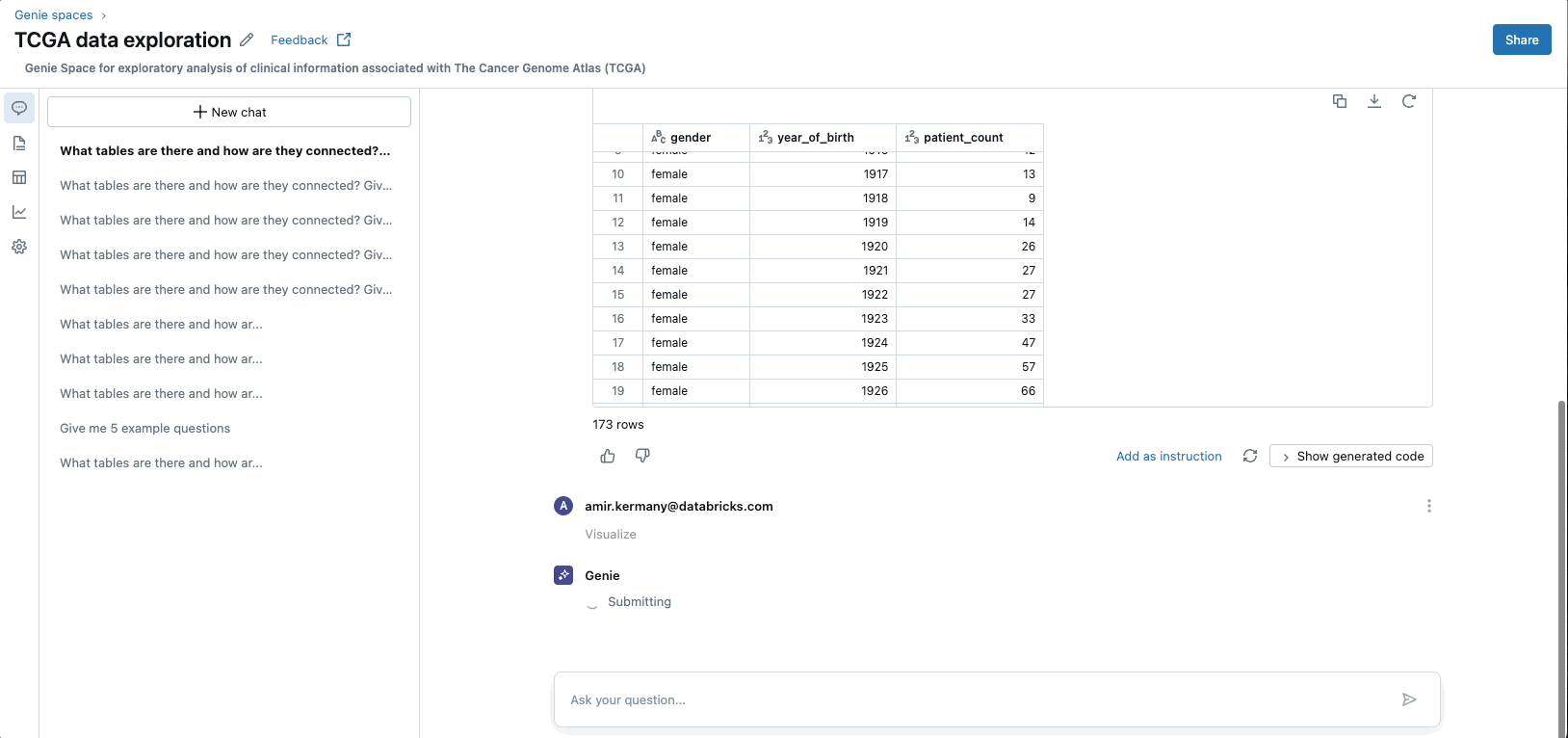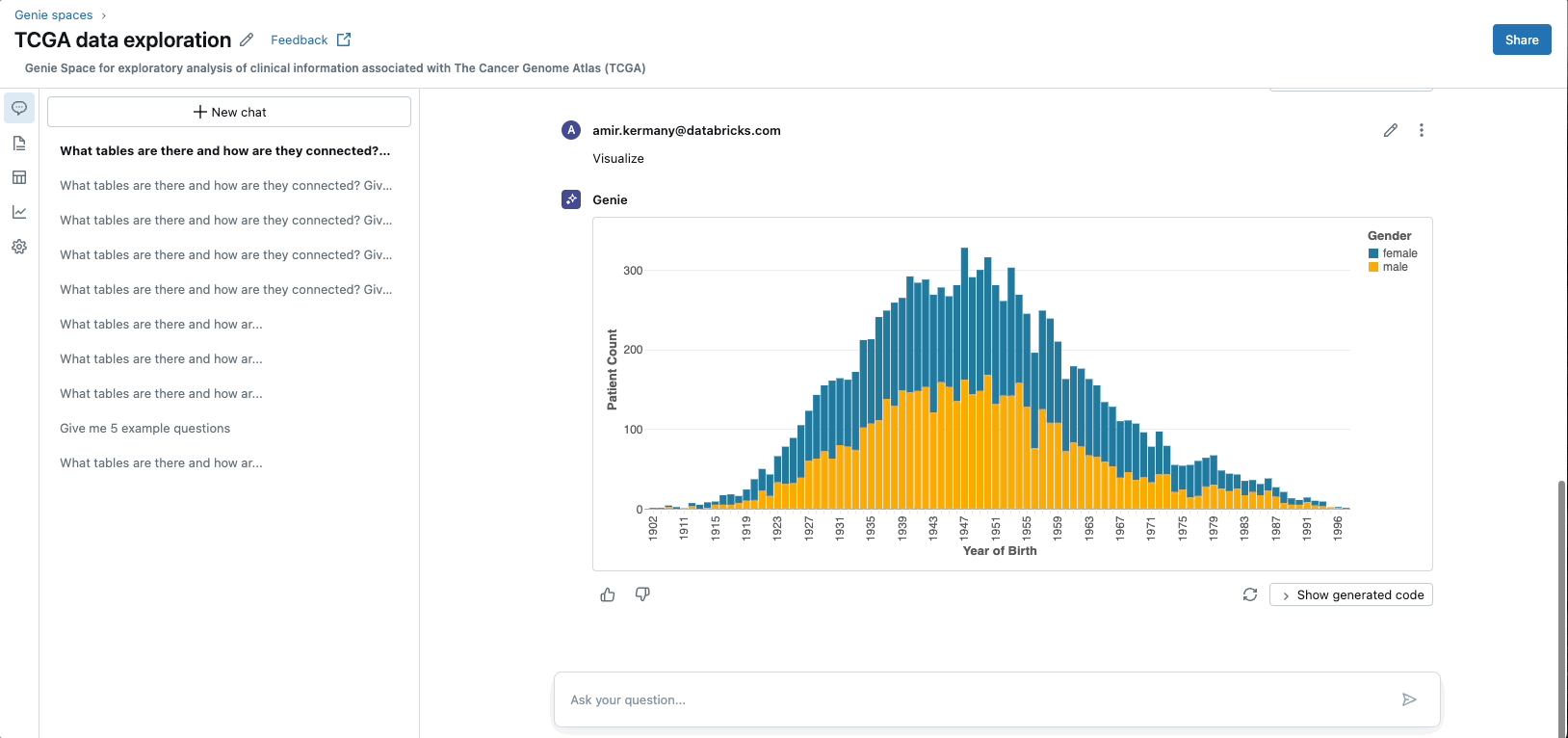
GenAIアプリケーションの台頭
DatabricksのMosaicAIプラットフォームは、スケーラブルで安全な計算インフラを提供することで、生成型AIモデルの事前学習、微調整、デプロイを可能にします。MosaicAIを使用すると、Databricksは、組織の独自のデータセットでの基礎モデルの訓練をコスト効率よく行うためのソリューションを提供します。さらに、MosaicAIは、高度にスケーラブルな ベクトル検索 と、 複合AIシステム の構築用の AIエージェントフレームワーク 、およびAIモデルのライフサイクル全体を管理するための LLMOps/MLOps 機能を提供しています。
これにより、組織は生成的AIの全潜在能力を解放し、AI投資からのビジネス価値を引き出すことができ、効果的、効率的、そしてスケールで運用されることを確保します。
今後の展望
今後の技術ブログでは、マルチオミクスのためのDatabricks技術の使用について探ります。これには、全ゲノム関連性研究の実施と、MosaicAIを用いたGeneformer基盤モデルの事前学習が含まれます。
要約すると、Databricksは、オミクスデータの管理に関する様々な課題に対応する包括的なプラットフォームを提供しています。スケーラブルなインフラストラクチャ、相互運用性のサポート、強力なセキュリティ機能、そして先進的なAI機能を備えたDatabricksは、製�薬会社が複雑なオミクスデータセットから実用的な洞察を抽出することを可能にします。Databricksを利用することで、組織は研究開発(R&D)の努力を加速させ、イノベーションと患者の結果の改善を実現することができます。
詳細を知る私たちのヘルスケアとライフサイエンスのためのデータとAIソリューションについて。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。