Databricks SQLの新機能をチェック!
よりシンプルで、より速く、より低コストなデータウェアハウジング
によって ガウラヴ・サラフ 、 Kevin Clugage による投稿
Databricks SQLがさらにシンプルに、速く、コストダウン!最新の新機能とパフォーマンス向上をお届けします。すでに7,000社以上の顧客がデータウェアハウスとして利用しており、Databricks史上最も急成長しているプロダクトです!
データウェアハウスの決定版
「レイクハウス」
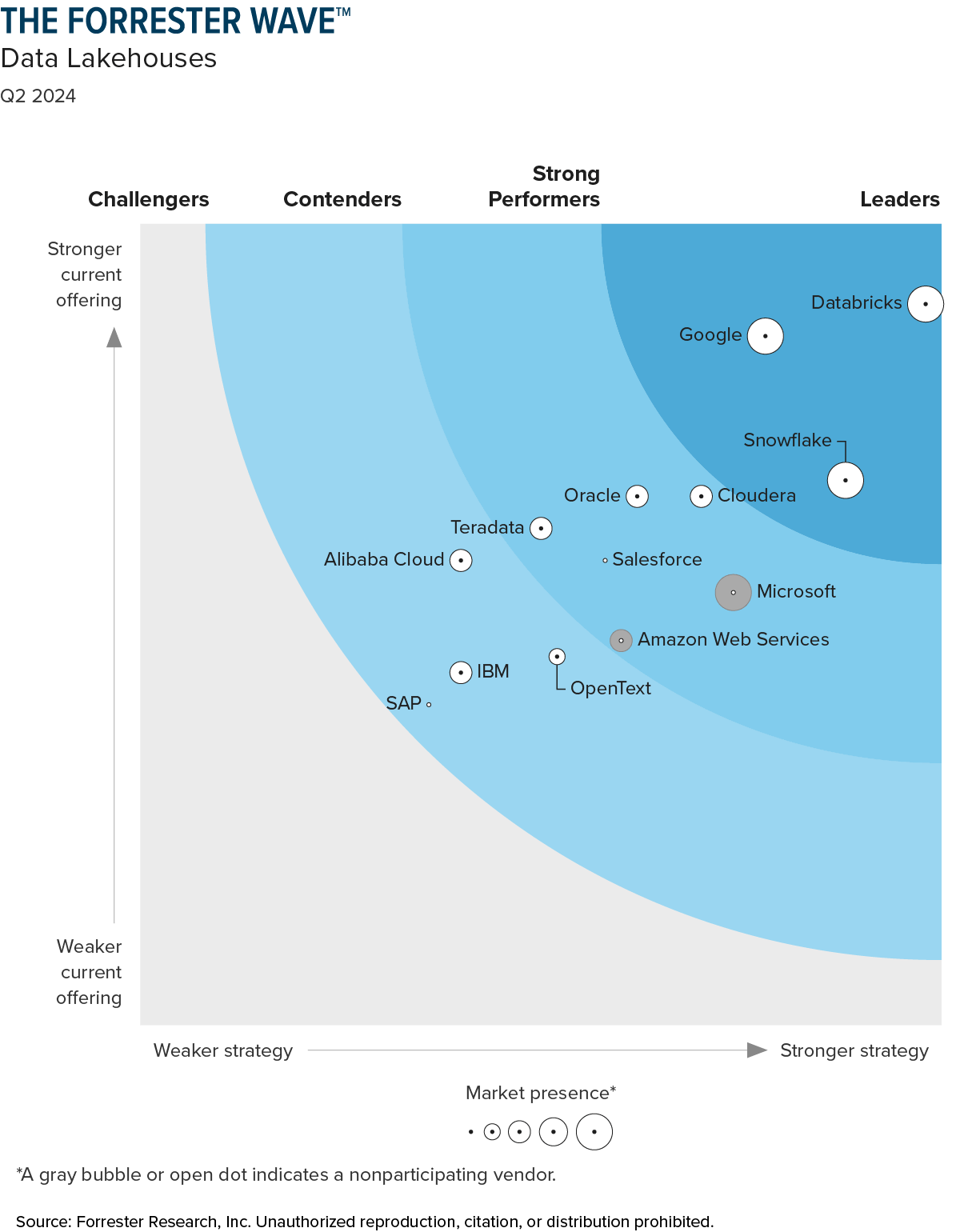
Databricks SQLは、私たちが2020年初頭に提唱したレイクハウスアーキテクチャに基づいて構築されています。このアプローチにより、コストが高く、独自仕様のデータウェアハウスはレガシーシステムになると予測し、実際にMIT Technology Insightsレポートでは、74%の企業がすでにレイクハウスアーキテクチャを採用していることが示されています。多くの企業が利用するレイクハウスベースのデータプラットフォームは、最近発表されたForrester Wave for Data Lakehousesレポートでもレビューされ、Databricksは、現在の提供内容と戦略の両カテゴリで最高スコアを獲得し、リーダーとして認められました!
お客様との会話で浮かび上がるレイクハウスの大きな利点は、低コストとAI・BIを統合したプラットフォームにあります。レイクハウスを使えば、オープンフォーマットのデータを1つのコピーでAIとBIの両方に活用でき、複数のプラットフォーム間でのデータの重複や同期を不要にし、コストを大幅に削減、アーキテクチャをシンプルにします。
AIによるパフォーマンス向上:4倍の改善
昨年、従来のヒューリスティックやコスト最適化に基づくシステムパフォーマンスアプローチは、ほとんどの場合で誤っていると宣言しました! それが当時の最善策だったとしても、現在のAI時代は全く新しいアプローチを可能にしています。今日、私たちはプラットフォーム全体で新世代のAIシステムを活用し、システムパフォーマンスを飛躍的に向上させています。これらのAIシステムは、ワークロードを分析し、自動的に効率とパフォーマンスを最適化します。
- リキッドクラスタリングがGAに!クラスタリングキーを自動で選び、データを書き換えずに再定義できる柔軟性を提供。データレイアウトは分析ニーズに合わせて進化し、テーブルパーティショニングやZORDERの手動調整が不要に。
- Predictive I/O(インデックスレス�インデクシング)は、インデックスのパフォーマンスを保ちながら作成や維持の負担を解消。Mosaic AIの進歩により、パラメータが桁違いに大きいモデルでも予測レイテンシーの増加なしで実行可能に。より広範なワークロードをサポート。
- Intelligent Workload Managementは、機械学習モデルでサーバーレスSQLウェアハウスのリソースを最適化し、高並列性に対応。大量のアナリストやクエリがデータウェアハウスを使用するBIワークロードに最適。
- 予測最適化もGAに!テーブルのパフォーマンス向上に役立つメンテナンスを自動で実行。クラスタリングやファイルサイズの調整、ファイルの削除など、手動作業は一切不要。
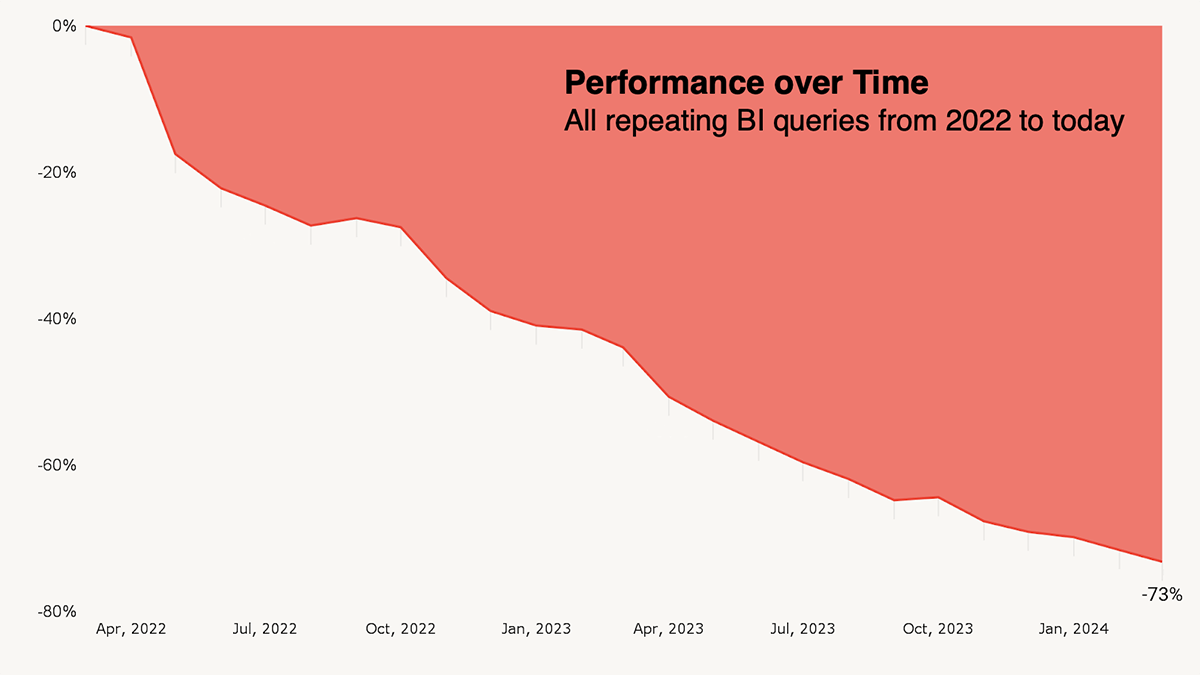
これらは私たちの組み込みAIシステムのほんの一部で、素晴らしいのはその動作の詳細を知らなくても、自動的に魔法のように動くことです。この分野に多くの時間を費やしているため、私たちはパフォーマンスに強くこだわっていると言えるでしょう。時間が経つにつれて、その違いが明らかになっています。顧客の反復ワークロードを調べたところ、同じBIクエリのパフォーマンスは2年前に比べて73%も向上しており、これは4倍の速さです!
SQLアナリスト向けのAIアシスタント
また、私たちはAIをユーザーエクスペリエンスに取り入れ、Databricks SQLをSQLアナリストにとってより使いやすく、生産性を向上させました。Databricks AIアシスタントは、現在一般に利用可能で、SQLアナリストがSQLを作成、編集、デバッグするのを支援する組み込みの、コンテキストに応じたAIアシスタントです。このアシスタントは、私たちのプラットフォームの同じデータインテリジェンスエンジンに基づいて構築されているため、あなたのビジネスのユニークなコンテキストを理解しています。アシスタントは、SQLアナリストがクエリを作成したり、エラーを修正したりするのに非常に役立つため、Databricksで急速に採用されています。これにより、時間を大幅に節約し、生産性を向上させることができます。
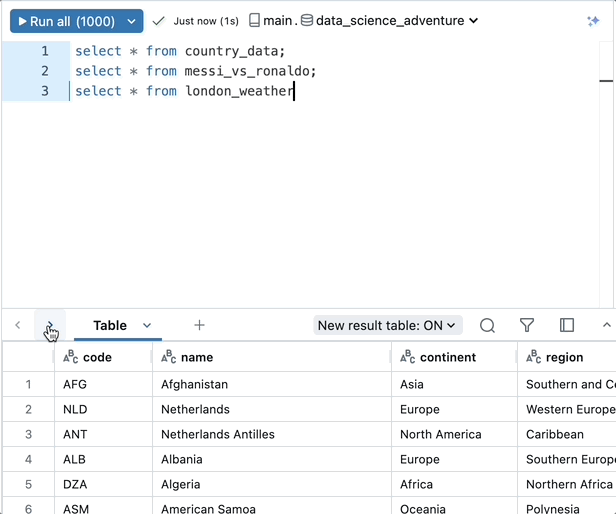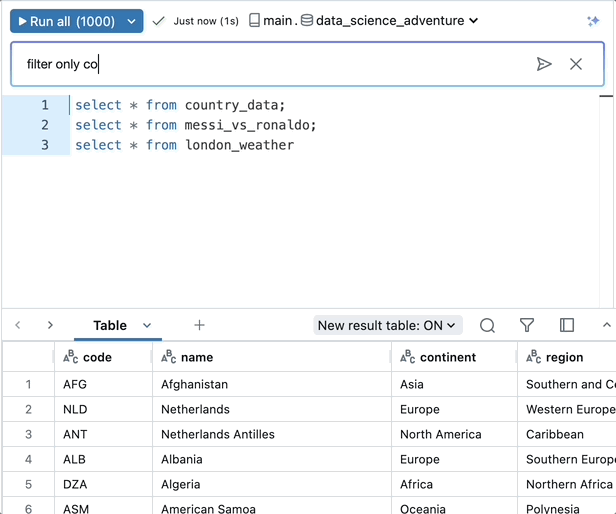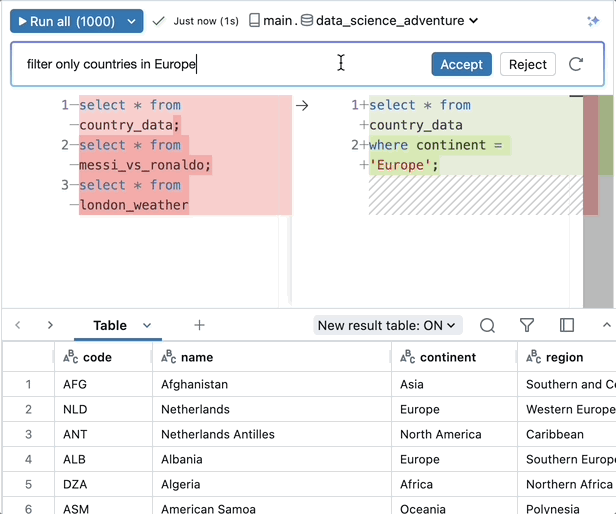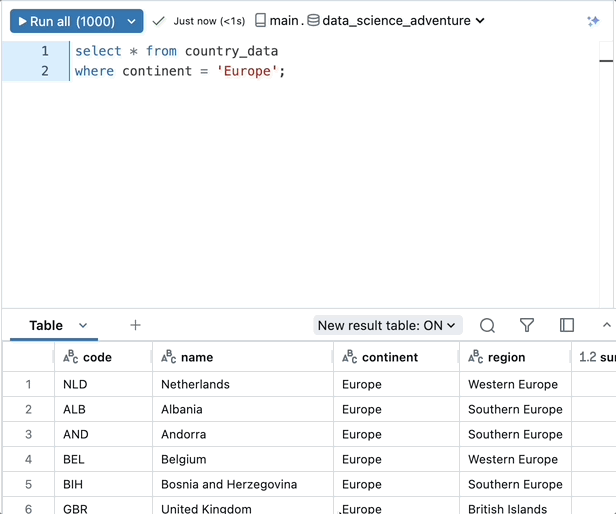
SQLを通じて直接AIモデルを活用する
生成AIやMLモデルの普及に伴い、SQLアナリストがSQL内でAIモデルに直接アクセスしたいというニーズが高まっているのは当然のことです。昨年、Databricks SQLにAI関数を導入したのもそのためで、導入以降急速に普及しています。現在、AI関数はパブリックプレビュー中で、ベクター検索などの新しい関数も追加されています。AI関数はLLMの技術的な複雑さを抽象化し、アナリストやデータサイエンティストが基盤となるインフラを気にせず、簡単にこれらのモデルを活用できるようにします。
- ai_query()関数を使用すると、SQLから任意のAIモデルにクエリを投げることができます。これには生成AIモデルや従来のMLモデルも含まれ、外部のLLMモデルも利用可能です。
- 組み込みのLLM関数
さらに、LLMの力を使って非構造化テキストを分析できる9つの新しい生成AI関数も追加されました。例えば、以下のようなことが可能です:
テーブルの列に含まれるテキストから重要な情報を抽出する。
製品のレビューコメントを内容に基づいて分類する: すべての9つの関数はこちらから確認できます。
- ベクトル検索:新しいベクトル検索機能により、KNN検索を実行し、RAGを簡単に使用できます!これはDatabricksのベクトル検索を使用しています。ベクトル検索機能とAI_query機能を組み合わせることで、SQLアナリストは複雑な分析を簡単に実行できるようになりました。例えば、現在ではすべてのツイートを検索することができます
- 「AI_Forecast: 新しい時系列予測の組み込み関数で、カスタムMLモデルを構築せずにSQLで迅速にメトリクス(例:収益)を予測できます。
AI/BI:新しいタイプのビジネスインテリジェンス(BI)製品
データからの洞察を真に民主化することを目指し、私たちは生成AIを活用してデータのセマンティクスを深く理解し、組織内の誰もがセルフサービスでデータ分析を行えるビジネスインテリジェンス製品『Databricks AI/BI』を導入しました。複合AIシステム上に構築されたAI/BIは、Unity Catalogのメタデータ、ETLパイプライン、SQLクエリなど、データ資産全体のインサイトを活用します。主な2つのコンポーネントとして、低コードで素早くデータビジュアライゼーションやダッシュボードを作成できる『AI/BI Dashboards』、そしてユーザーフィードバックから継続的に学習し、幻覚なしで実際のビジネスの質問に幅広く回答するデータ向け会話型インターフェース『Genie』を提供しています。これらの革新により、Databricks SQLにおけるセルフサービス分析が大幅に強化され、統一されたガバナンス、ライネージトラッキング、安全なデータ共有、高パフォーマンスを実現しつつ、より多くの非技術的ユーザーが活用できるようになっています。
Databricks SQLによる完全な、エンドツーエンドのデータウェアハウジング
新しいAI機能に加えて、私たちは一連のSQL Warehouseの基本機能もリリースしました。数千社の顧客が、レガシーデータウェアハウスからDBSQLへ移行しています。この移行を実現するために、DBSQLにはレイクハウス上で従来のデータウェアハウスと同じ機能を提供するためのすべての機能が備わっていることを確認しました。
- マテリアライズドビュー:ダッシュボードを動かすためのMVsを使用してデータの新鮮さを確保します。マテリアライズドビューは、クエリされたときではなく、基礎となるテーブルに新鮮なデータがあるときに自動的に更新されます。
- PK/FK制約を使用してクエリのパフォーマンスを最適化します。RELYを使用することで、冗長な結合と明確な集計を自動的に排除してクエリを高速化することができます。
- Variantは、半構造化データを処理するための新しいデータ型で、データをJSON文字列として保存するよりも大幅なパフォーマンス向上を提供し、高度にネストされたスキーマや進化するスキーマをサポートする柔軟性を提供します。
- Lateral Column Aliasesは、同じクエリ内で以前に指定した表現を参照して再利用することで、SQLの記述を容易にします。これにより、不必要なCTEやサブクエリを減らしてクエリを簡素化することができます。
- SQL Variables、Named Arguments & Python UDFsなどの機能も、Databricks SQLで直接スクリプトを作成するのを容易にしています。
忘れないでください、これらすべては素晴らしいAIパワードのSQLエディタと組み込みのダッシュボーディングツールで動作します。
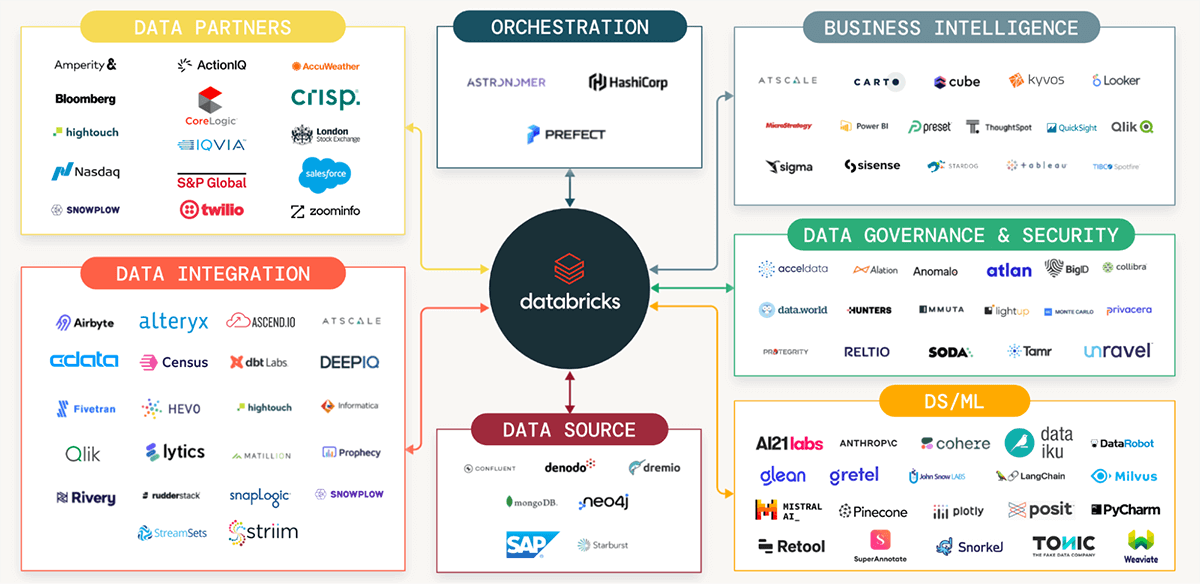
さらに、素晴らしいパートナーのおかげで、Power BI、Tableau、dbtなど、お気に入りのデータとAIツールの豊かで開放的で統合されたエコシステムも持っています。
あなたが今日使用しているツールは、ほぼ確実にDBSQLとすでに連携しています。
Databricks SQLをもっと学び、始めてみましょう。
データウェアハウジングとDatabricks SQLの最新情報については、Data + AI SummitのData Warehouse keynoteとData Warehousing, Analytics and BI trackの多数のセッションをご覧ください。
既存のウェアハウスを高性能でサーバーレスのデータウェアハウスに移行し、優れたユーザーエクスペリエンスと低コストを実現したい場合、Databricks SQLが解決策です
-- 無料でお試しください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。