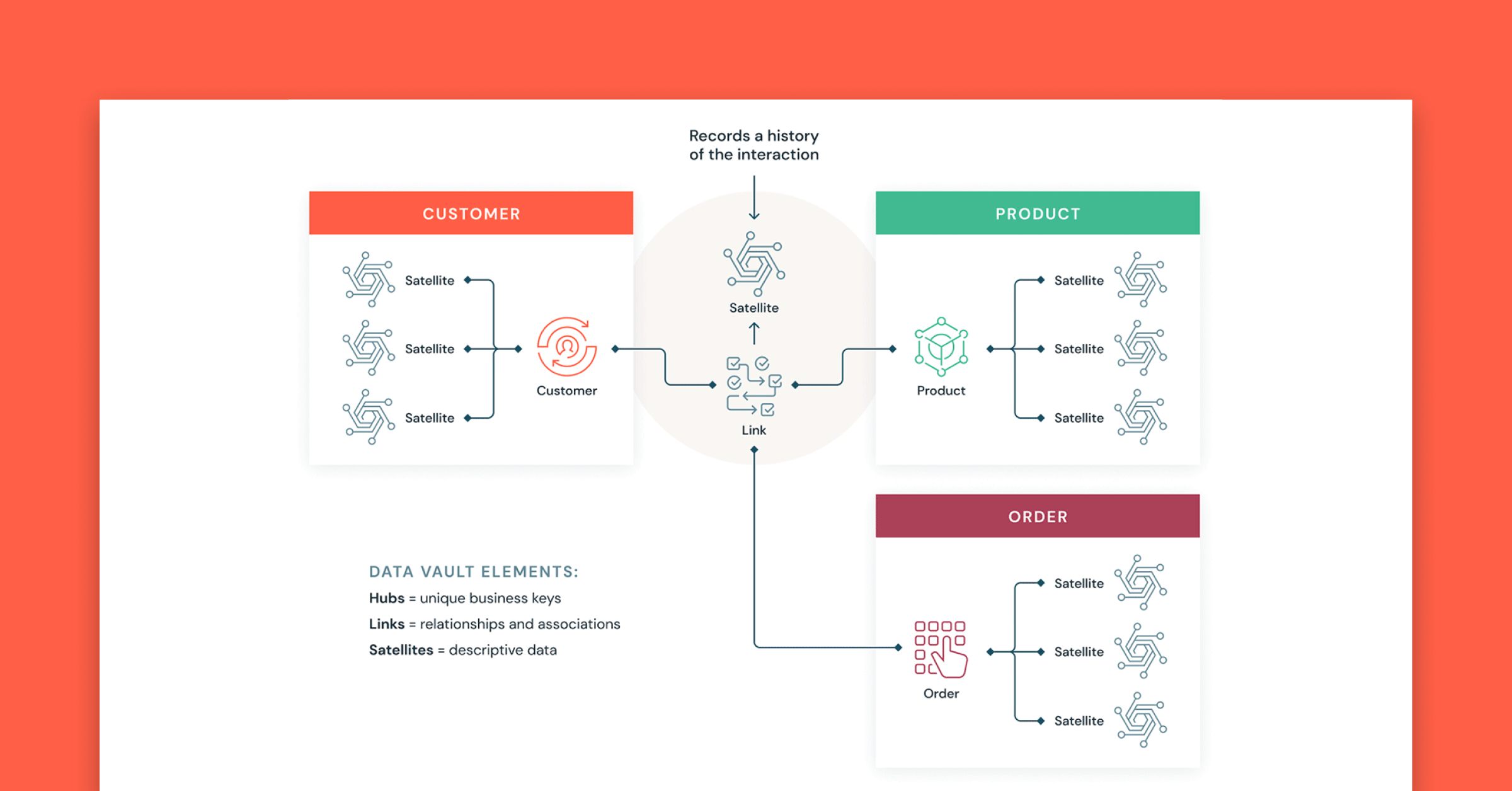
Databricksへの移行戦略:成功のための教訓
Databricksの顧客移行経験からの洞察とベストプラクティス

データウェアハウスのワークロードを移行することは、あらゆる組織にとって最も難しいながらも重要なタスクの一つです。移行の動機がビジネスの成長とスケーラビリティの要件であれ、既存のレガシーシステムの高いライセンス・ハードウェアコストの削減であれ、単にファイルを転送するだけではありません。Databricks では、プロフェッショナルサービス(PS)チームが何百もの顧客やパートナーと共に移行プロジェクトに取り組み、数多くの成功事�例を積み上げてきました。このブログでは、移行の範囲設定、設計、構築、実行においてデータプロフェッショナルが考慮すべきベストプラクティスと教訓を探ります。
移行を成功させるために: 5段階のプロセス
Databricksでは、私たちの経験と専門知識に基づいて、移行プロジェクトのための5段階のプロセスを開発しました。
移行プロジェクトを開始する前に、まずディスカバリーフェーズから始めます。このフェーズでは、移行の背後にある理由と既存のレガシーシステムの課題を理解することを目指しています。私たちはまた、ワークロードをDatabricksデータインテリジェンスプラットフォームに移行する利点を強調します。ディスカバリーフェーズでは、顧客やDatabricksからの主要なステークホルダーとの協力的なQ&Aセッションとアーキテクチャ討議が行われます。さらに、自動化されたディスカバリープロファイラーを使用してレガシーワークロードに洞察を得たり、Databricksプラットフォームの消費コストを見積もったりして、TCO削減を計算します。
ディスカバリーフェーズを終えた後、より詳細な評価に移ります。この段階では、自動化されたアナライザを使用して既存のコードの複雑さを評価し、必要な労力とコストの高レベルの見積もりを得ます。このプロセスは、現在のデータプラットフォームのアーキテクチャとそれがサポートするアプリケーションについての貴重な洞察を提供します。また、これにより移行の範囲を精緻化し、時代遅れのテーブル、パイプライン、ジョブを排除し、ターゲットアーキテクチャを考慮し始めることができます。
移行戦略と設計フェーズでは、ターゲットアーキテクチャの詳細とデータ移行、ETL、ストアドプロシージャコードの翻訳、レポートとBIの近代化の詳細設計を最終化します。この段階では、ソースとターゲットの資産間のテクノロジーもマッピングします。移行戦略、ターゲットアーキテクチャ、移行パターン、ツール、選択したデリバリーパートナーが確定したら、Databricks PSと選択したSIパートナーは、パイロット(フェーズI)またはプロジェクトの複数のフェーズのための移行作業指示書(SOW)を準備します。Databricksには、成功した移行を確保するための自動化ツールを提供する認定されたMigration Brickbuilder SIパートナーがいくつかあります。さらに、Databricksプロフェッショナルサービスは、SIパートナーと共に移行保証サービスを提供することができます。
作業指示書(SOW)が署名された後、Databricks Professional Services(PS)または選択されたデリバリーパートナーがプロダクションパイロットフェーズを実施します。このフェーズでは、明確に定義されたエンドツーエンドのユースケースがレガシープラットフォームからDatabricksに移行します。データ、コード、レポートは、自動化ツールとコードコンバータアクセラレータを使用してDatabricksに近代化されます。ベストプラクティスは文書化され、スプリントレトロスペクティブは改善のための領域を特定するための学んだすべての教訓を捉えます。Databricksのオンボーディングガイドは、通常、アジャイルなScrumチームを使用して並行して実行される残りのフェーズの設計図として作成されます。
最終的に、我々は本格的なマイグレーション実行フェーズに進みます。私たちは、学んだ教訓をすべて統合するパイロット実行アプローチを繰り返します。これにより、組織内にDatabricksのエクセレンスセンター(CoE)を設立し、顧客チーム、認定されたSIパートナー、および私たちのプロフェッショナルサービスチームと協力してチームを拡大し、移行の専門知識と成功を確保します。
学んだ教訓
大きく考えて、小さく始める
戦略フェーズでは、ビジネスのデータランドスケープを完全に理解することが重要です。同様に重要なのは、製品のパイロットフェーズ中に特定のエンドツーエンドのユースケースをいくつかテストすることです。どんなに計画を立てても、一部の問題は実装中にしか発生しないかもしれません。早期に直面して解決策を見つける方が良いです。パイロットユースケースを選ぶ素晴らしい方法は、最終目標から始めることです - 例えば、あなたのビジネスにとって重要なレポーティングダッシュボードを選び、それを作成するために必要なデータとプロセスを把握し、その後、テストとして目標プラットフォームで同じダッシュボードを作成してみてください。これにより、移行プロセスが何を伴うかについての良いアイデアを得ることができます。
ディスカバリーフェーズを自動化する
私たちは、移行の範囲を理解するためにアンケートを使用し、データベース管理者にインタビューを行うことから始めます。さらに、私たちの自動化されたプラットフォームプロファイラは、データベースのデータ辞書とhadoopシステムメタデータをスキャンし、CPU利用率、% ETL対% BI使用率、さまざまなユーザーによる使用パターン、サービスプリンシパルについての実際のデータ駆動型の数値を提供します。この情報は、Databricksのコストと結果としてのTCO節約を見積もるのに非常に役立ちます。コード複雑度分析器も価値があります。これは、移行するDDL、DML、ストアドプロシージャ、その他のETLジョブの数と、それらの複雑さの分類を提供します。これにより、移行費用とタイムラインを決定するのに役立ちます。
自動コードコンバーターを活用する
自動化されたコード変換ツールの利用は、移行を迅速化し、費用を最小限に抑えるために不可欠です。これらのツールは、ストアドプロシージャやETLなどのレガシーコードをDatabricks SQLに変換するのに役立ちます。これにより、ドキュメンテーションが不足しているために見落とされる可能性のあるレガシーコードで実装されたビジネスルールや機能がないことを確認します。さらに、変換プロセスは通常、開発者の開発時間を80%以上節約し、彼らがすぐに変換されたコードをレビューし、必要な調整を行い、ユニットテストに集中することを可能にします。自動化ツールがデータベースコードだけでなく、レガシーなGUIベースのプラットフォームからのETLコードも変換できるこ�とを確認することが重要です。
コード変換を超えて―データも重要です
移行はしばしば、明確に定義されたプロジェクトの誤った印象を生み出します。移行について考えるとき、通常はソースエンジンからターゲットへのコードの変換に焦点を当てます。ただし、新しいプラットフォームを使用可能にするために必要な他の詳細を見落とさないようにすることが重要です。
例えば、コードの移行や変換と同様に、データ移行のアプローチを最終化することが重要です。データ移行は、適用可能な場合にはDatabricks LakeFlow Connectを使用するか、または私たちのCDC Ingestionパートナーツールのいずれかを選択することで効果的に達成できます。初期の開発フェーズでは、レガシーEDWからの履歴とキャッチアップロードを行いつつ、実際のソースからDatabricksへのデータ取り込みを同時に構築する必要があるかもしれません。さらに、Databricksワークフロー、Delta Live Tables、または同様のツールを使用した明確に定義されたオーケストレーション戦略を持つことが重要です。さらに、移行が完了したと考える前に、移行したデータプラ�ットフォームはソフトウェア開発とCI/CDプラクティスに合わせるべきです。
ガバナンスとセキュリティを無視しないでください。
ガバナンスとセキュリティは、移行の設計とスコープを決定する際によく見落とされる他のコンポーネントです。既存のガバナンスの実践に関係なく、一元化されたアクセス制御、監査、系統、データ発見機能のための真実の唯一の情報源として、DatabricksのUnity Catalogの使用をお勧めします。Unity Catalogの移行と有効化は、完全な移行に必要な労力を増加させます。また、私たちのガバナンスパートナーが提供する一部のユニークな機能を探索してみてください。
データ検証とユーザーテストは、成功した移行に不可欠です
プロジェクトの成功には、適切なデータ検証と、ユーザー受け入れテストフェーズ中のビジネス主題専門家(SME)からの積極的な参加が重要です。Databricksの移行チームと認定されたシステムインテグレータ(SI)は、並列テストとデータ調整ツールを使用して、データがすべてのデータ品質基準を満たし、不一致がないことを確認します。エグゼクティブとの強い連携は、ビジネスSMEのユーザー受け入れテスト中の適時かつ集中的な参加を確保し、生産への迅速な移行と新��システムが導入された後の旧システムとレポートの廃止についての合意を促進します。
実現する - 移行を運用化し、観察する
データ品質フレームワーク、例外処理、再処理、データパイプラインの観察可能性制御など、良好な運用ベストプラクティスを実装し、プロセスメトリクスをキャプチャして報告します。これにより、偏差や遅延を特定し報告することが可能となり、即時の是正措置を取ることができます。Databricksの機能であるLakehouse Monitoringと私たちのシステム請求テーブルは、観測可能性とFinOpsトラッキングを支援します。
専門家を信頼する
移行は困難な場合があります。常にバランスを取るトレードオフや予期しない問題や遅延を管理する必要があります。移行の人、プロセス、技術の側面には、実績のあるパートナーとソリューションが必要です。Databricksプロフェッショナルサービスの専門家と私たちの認定移行パートナーを信頼することをお勧めします。彼らは、高品質な移行ソリューションをタイムリーに提供する豊富な経験を持っています。お問い合わせして、移行評価を開始してください。