Announcing the Databricks storage ecosystem: Governing the enterprise data estate, wherever it lives
Powered by open source OpenSharing, our new storage partner ecosystem brings Databricks Data Intelligence Platform directly to your on-premises and hybrid infrastructure—without copying a single byte.
by Rupal Jain and Denis Dubeau
- The challenge: Organizations need to keep vast amounts of data on-premises, in private clouds, and at the edge environments to meet strict data sovereignty and regulatory requirements, maintain low latency at the edge, or handle immense data gravity—all while still bringing modern cloud AI and governance to those environments.
- What it is: The Databricks Storage Ecosystem natively connects hybrid and on-premises storage platforms to Databricks using the OpenSharing protocol. This allows organizations to establish centralized data governance and scale GenAI across their entire hybrid infrastructure.
- The outcome: Using a zero-copy architecture, enterprises can run Databricks Serverless Compute, Genie, and LLMs directly on their on-premises datasets without copying a single file. This instantly turns isolated data into active, AI-ready assets for advanced use cases, such as training models on classified engineering data or analyzing network telemetry in place.
The Data That Can't Move
For years, the enterprise data strategy was simple: move everything to the cloud. Migrate the data lakes and the warehouses to the cloud, and then governance follows. It was a clean story — until it wasn't.
Today, some of the world's most sophisticated enterprises are telling us clearly: they cannot — and will not — move all of their data to the cloud. Leading semiconductor manufacturers are training models on engineering-classified datasets that must never leave their premises. Global trading firms sit on massive volumes of historical tick data where the economics of cloud egress make migration impossible. Tier-1 banks have adopted "Hybrid Forever" strategies, modernizing on-premises storage while maintaining strict data sovereignty. Major pharmaceutical companies run millions of daily drug experiments against petabyte-scale on-premises data estates subject to stringent regulatory controls.
These aren't edge cases. They represent a structural shift in how enterprises think about data: from "Migrate Everything" to "Govern Everything."
The drivers are real and compounding:
- Data sovereignty & regulation: Financial services, healthcare, and government organizations operate under mandates — GDPR, HIPAA, NIS2, sector-specific data residency rules — that require data to remain within specific jurisdictions or air-gapped environments. Cloud migration is not optional; it is legally prohibited for certain datasets.
- Data gravity & costs: At petabyte and exabyte scale, the economics of cloud migration break down entirely. Egress fees, storage costs, and sheer data volume make the "move it once" model financially unsustainable. Some of the world's largest retailers are actively repatriating analytics workloads from cloud back to on-premises infrastructure for precisely this reason.
- Latency & edge workloads: Retail, manufacturing, and telco workloads require low-latency access to on-premises and edge data. Telecommunications providers ingest enormous volumes of network telemetry on-premises daily to power AI-driven network operations that cannot tolerate cloud round-trips.
- AI on dark data: Vast stores of backup data, unstructured archives, and secondary datasets — representing hundreds of exabytes across the enterprise — contain immense AI value that has never been unlocked because governance didn't reach it.
The signal is unmistakable. We have received requests from hundreds of customers explicitly requesting on-premises and hybrid storage connectivity to Unity Catalog. The Software-Defined Storage (SDS) market stands at hundreds of billions of dollars in 2026, and the enterprise partners who manage this estate — collectively holding more than 2 Zettabytes of data under management — are building with us.
Introducing the Databricks Storage Ecosystem
Today, we are excited to announce the Databricks Software-Defined Storage (SDS) Ecosystem — a new partner category purpose-built to bring Databricks Intelligence Platform to enterprise data wherever it lives: on-premises, in private clouds, and at the edge environments. If you are an enterprise running petabytes of data on these platforms today, you no longer have to choose between your existing non-cloud storage infrastructure and Databricks AI.
For too long, enterprises had to choose between the on-premises storage infrastructure they rely on and the cloud-native AI they want to build. Forcing customers to migrate massive amounts of data using complex pipelines just to unlock that intelligence is a broken model. By uniting these industry-leading partners, we are ending that compromise and delivering Databricks Intelligence directly to where the enterprise data lives. But this launch is just day one. We are building the foundation to ensure that soon, every piece of hybrid data–structured or unstructured–is instantly ready for generative AI without ever copying a byte. —Stephen Orban, SVP, Product Partnerships & Ecosystem, Databricks
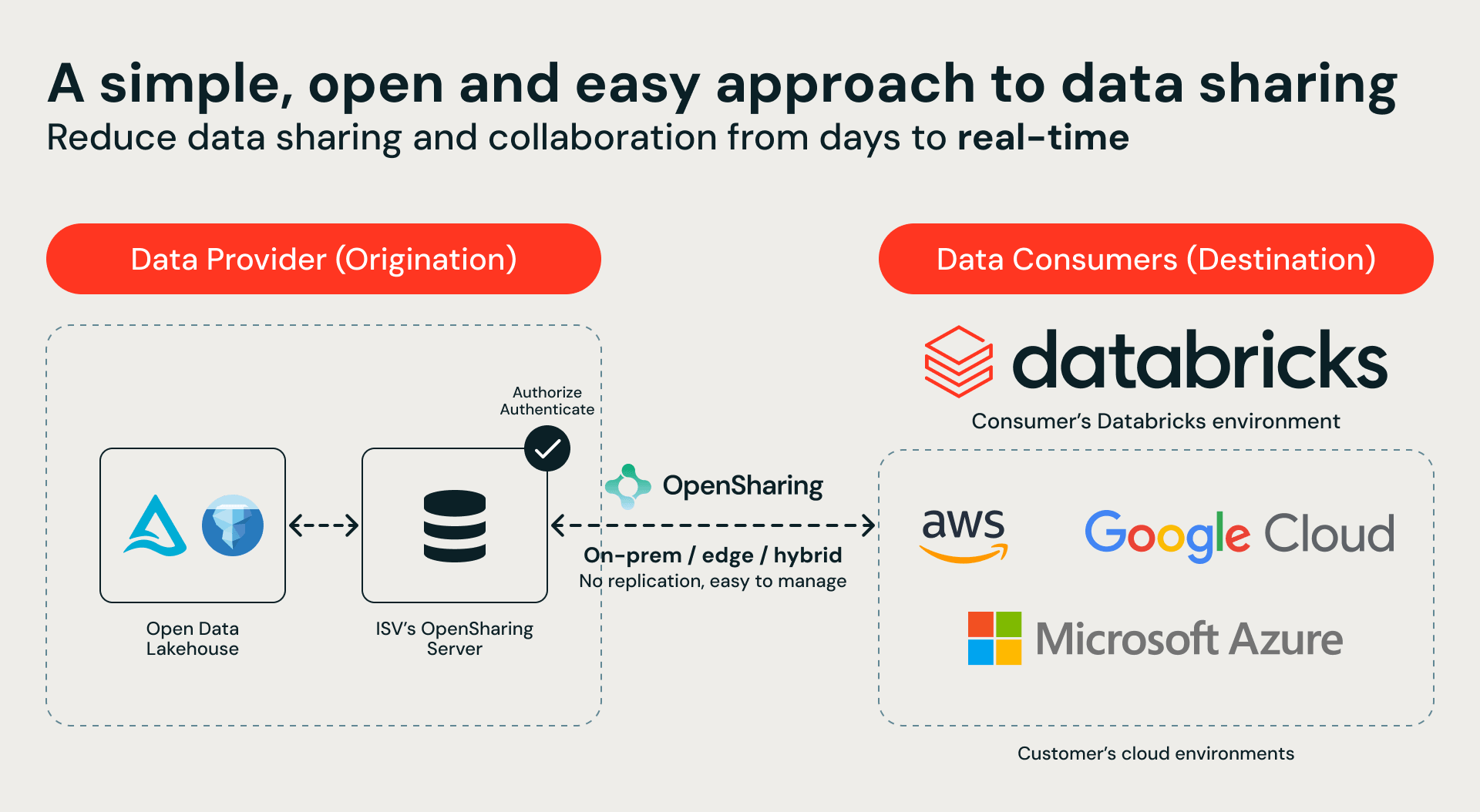
At the heart of this ecosystem is OpenSharing, an open-source protocol for secure, governed data sharing. Our storage partners are implementing OpenSharing servers to expose their data estates directly to Databricks Serverless Compute. The path is simple: the storage partner stands up a OpenSharing endpoint, you connect it to Unity Catalog, and you instantly gain secure, governed access to your on-premise data in Databricks without data migration.
This integration provides a single, unified catalog across your entire hybrid environment. Customers can now use Databricks Serverless Compute, Genie, AgentBricks, and model training to query and reason over data that never leaves the premises. The result? Zero data movement, no duplication of data and zero compliance risk.
This is not a roadmap aspiration. Customers can try these integrations today. Partners building these integrations follow the Partner Well-Architected Framework — a technical blueprint covering architecture, security, and certification criteria.
Customers want to break down data silos and unify all of their Data and AI estate - including large amounts of data that still sits on-premises. Thanks to on-premises storage partners leveraging the open source Open Sharing protocol, customers can now seamlessly unify, govern, and analyze all of their data estate in Databricks Unity Catalog - unlocking the full value of their data in the Databricks Data Intelligence Platform. —Jonathan Keller, VP, Product Management, Databricks
Our Launch Partners
We are proud to announce integrations with the following leading storage providers:

MinIO — General Availability (demo, blog)
MinIO AIStor is the bridge that seamlessly connects the Databricks Data Intelligence Platform with enterprise data that can't move to the cloud. By natively implementing the open Open Sharing protocol at the storage layer, AIStor eliminates complexity and enables Databricks customers to efficiently query live on-premises Apache Iceberg™️ and Delta tables under full Unity Catalog governance. It extends Serverless Compute, Genie, and Agent Bricks to on-premises data, bringing the full power of the Databricks Platform to an enterprise's most critical data.
AI and analytics initiatives are often constrained by where data resides, particularly in environments with strict security, sovereignty, or operational requirements. By bringing native OpenSharing to AIStor, we're enabling organizations to securely expose data where it lives while giving Databricks seamless access through open standards. This removes a major barrier between enterprise data and AI, allowing organizations to activate previously inaccessible data for AI, analytics, and agentic applications without compromising control. —Ugur Tigli, Chief Technology Officer, MinIO
Everpure (formerly Pure Storage) — Private Preview (demo, blog)
Everpure and Databricks enable organizations to use on-prem data directly in the cloud removing the need for data replication or duplication.This is delivered through an OpenSharing connector that bridges data in object storage with databricks core workspaces in a secure and gated manner.
Everpure and Databricks enable organizations to access and analyze on-premises data directly from the cloud without the need for replication or duplication. Continuously moving data between environments is costly and unsustainable at scale. Customers are looking for a simpler approach that balances cost, compliance, and data sovereignty while reducing operational complexity. —Chadd Kenney, VP of Product Management, Everpure
Qumulo — Private Preview in July 2026 (blog)
Qumulo has integrated OpenSharing with its new NeuralSearch, allowing customers to securely share Qumulo-stored data with Databricks across core, cloud, and edge environments—without replication, extra costs, or complexity. Using NeuralSearch, users can discover relevant datasets, including unstructured content, via natural-language queries and seamlessly share those curated tables with Databricks via OpenSharing.
Organizations can no longer afford the cost, complexity, and delays of copying massive datasets across environments just to support AI and analytics. By combining Qumulo NeuralSearch with Databricks OpenSharing, customers can securely discover, govern, and share both tabular and unstructured data across core data centers, edge locations, and public clouds – in real time, without moving the data itself. Together, we're helping organizations accelerate AI initiatives, unify governance, and unlock faster time-to-insights from globally distributed data while maintaining a single source of truth. —Brandon Whitelaw, SVP and Head of Product at Qumulo
VAST Data — Private Preview in August 2026
VAST Data is extending the VAST AI Operating System with OpenSharing support to help enterprises bridge Databricks workflows with data that resides across on-premises and hybrid infrastructure – without requiring massive data movement or migration. The integration will give customers more flexibility to access, process and operationalize data across cloud, data center and emerging AI infrastructure environments while supporting modern hybrid AI and analytics workloads.
AI infrastructure is becoming fundamentally hybrid. Customers increasingly want the ability to process data wherever it makes the most sense economically and operationally, while still maintaining seamless access across environments. OpenSharing support extends the VAST AI Operating System’s ability to bridge Databricks workflows with data that resides across cloud and on-premises infrastructure for modern AI and analytics applications. Unlike traditional storage platforms, VAST combines data services, distributed processing and AI infrastructure orchestration into a unified operating system for AI data at scale. —John Mao, Vice President, Global Technology Alliances at VAST Data
What's Next
Integrations Coming Soon
In addition to our launch partners, momentum across the storage ecosystem continues to accelerate. We have secured commitments from Cohesity, Commvault, HPE, NetApp, Nutanix, and Rubrik —to build native integrations by the end of the year.
Collectively, these partners, along with launch partners, manage hundreds of exabytes of enterprise data, spanning high-performance unstructured media, secondary backup archives, cost-effective cloud storage, and hyperconverged private cloud estates.
Unlocking Unstructured Data
Today's launch establishes structured, tabular data as fully governed and accessible across this ecosystem. But we know that exciting opportunity lies ahead in unstructured data: the images, PDFs, videos, medical scans, engineering simulations, and backup archives that represent the majority of enterprise data under management — and the raw material for the next generation of RAG pipelines and fine-tuned models.
We are actively working to extend the OpenSharing protocol with Volumes APIs — exposing unstructured files from on-premises storage directly to Databricks for GenAI workloads. With this coming, partners managing massive unstructured estates — from media and imaging archives to enterprise backup repositories — will unlock an entirely new class of AI use cases for their customers.
This is what it means to govern everything.
Join the Ecosystem
If you are a storage vendor interested in building an OpenSharing integration, visit the Partner Well Architected Framework or reach out to the Databricks Partner team to get started.
If you are an enterprise customer who wants to connect your on-premises storage estate to Databricks, contact your account team to learn more.
The era of "Migrate Everything" is over. The era of "Govern Everything" starts today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.