The database your
AI agents deserve
Lakebase is serverless Postgres for applications that scale

Build and run apps, agents
and AI on your data
The Databricks Platform
Unify your data, analytics and AI. Use it to power agents, apps and natural language insights.
Lakebase
The first serverless Postgres database integrated with the lakehouse, built for the AI era.
Genie
Your data-aware AI partner for faster work and deeper insights.
Agent Bricks
Build AI agents that continuously improve quality and accuracy, optimized on your data.
Lakehouse
Serverless data warehousing on open lake data, with governance and AI built-in.
How innovators win with data and AI
AWARDS AND RECOGNITION
Recognized for innovation in data and AI
0%
Over 60% of the Fortune 500 uses Databricks
0K+
Over 20,000 customers across the globe
0x
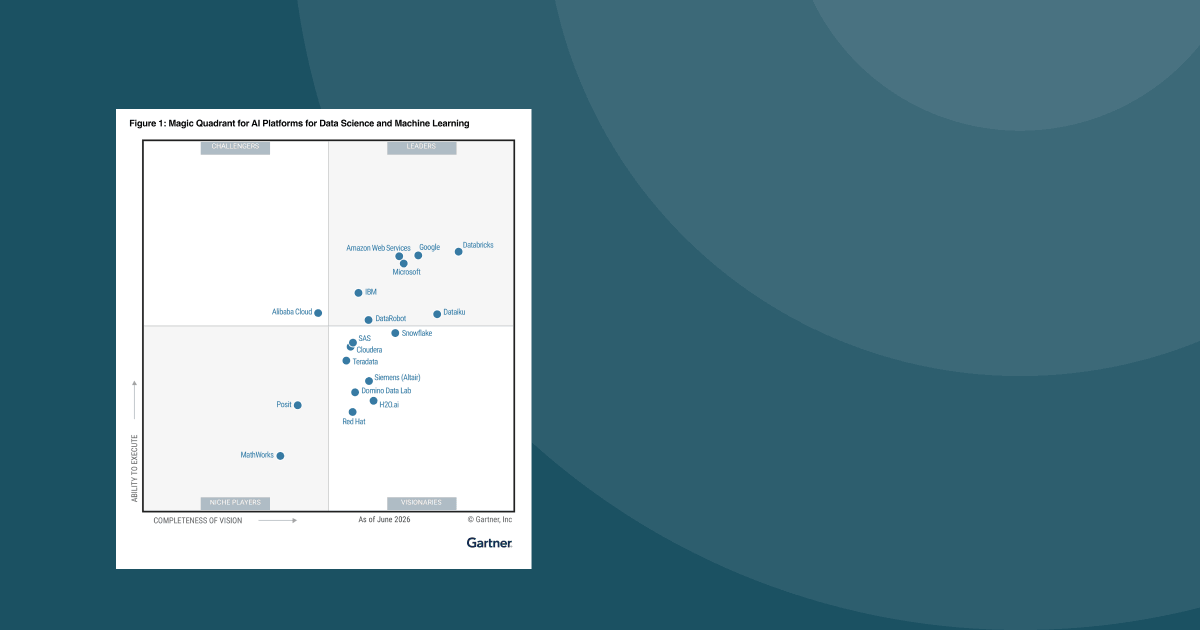
5x Leader in Gartner® Magic Quadrant™ Reports






Start your data + AI journey