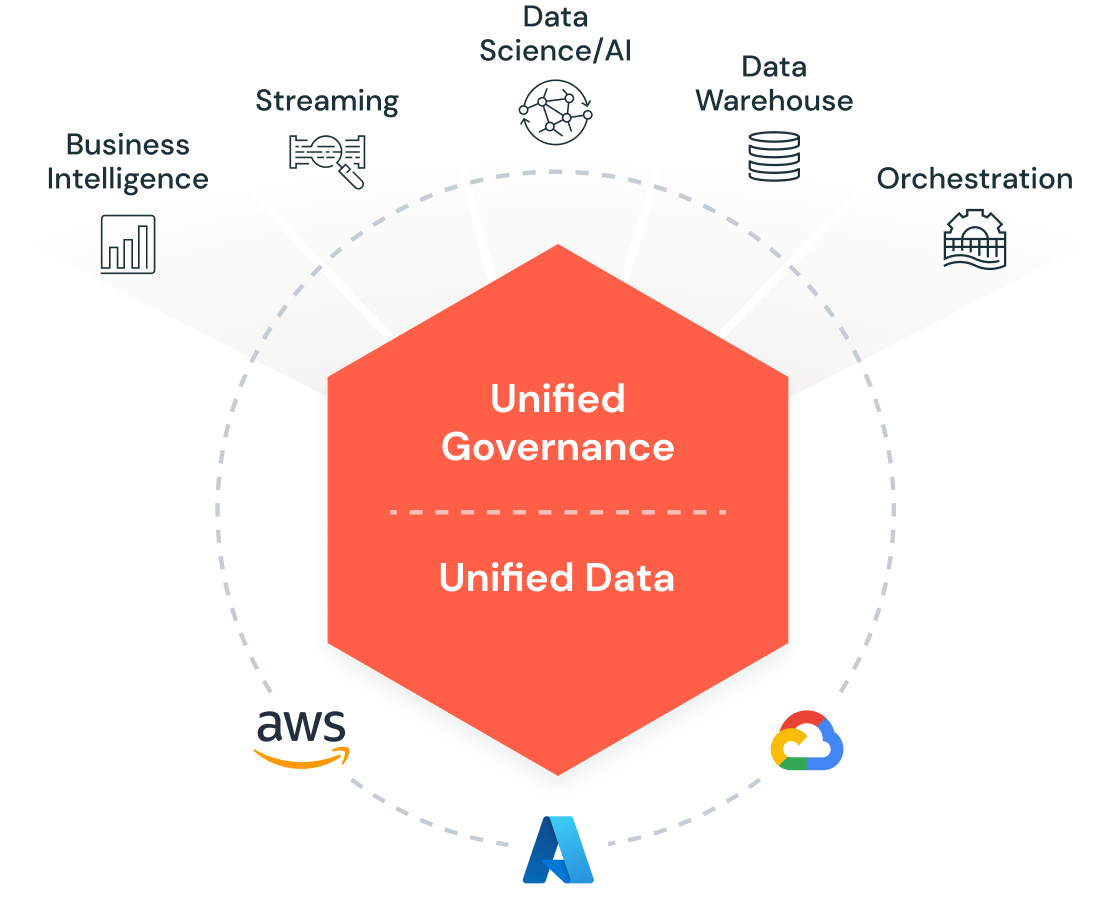
Unified. Open. Scalable.
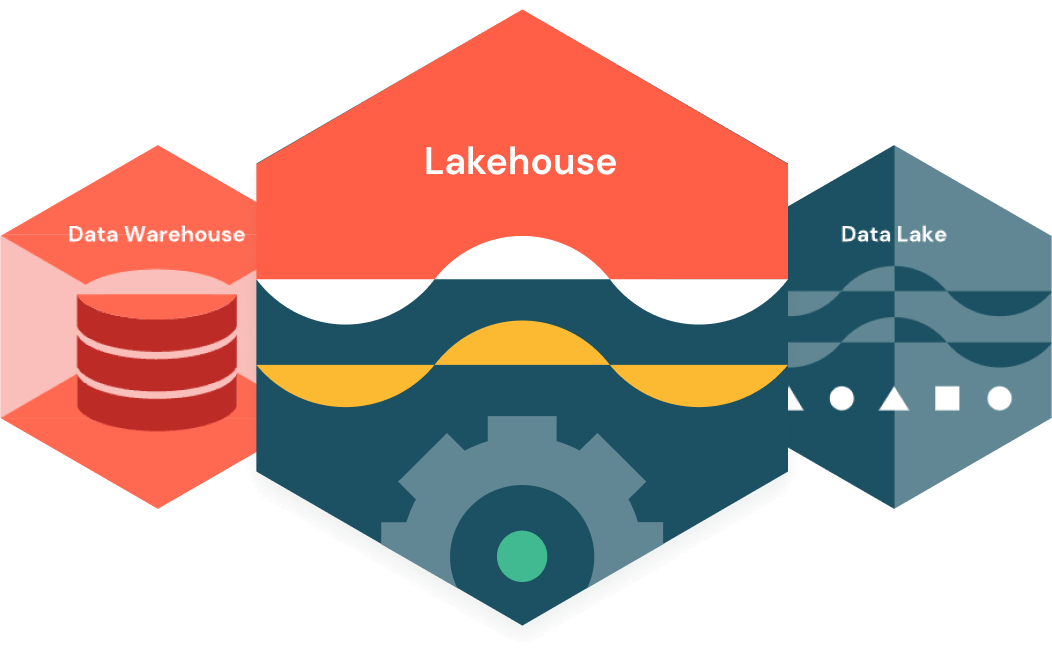
The Databricks Data Intelligence Platform is built on lakehouse architecture, which combines the best elements of data lakes and data warehouses to help you reduce costs and deliver on your data and AI initiatives faster.
Built on open source and open standards, a lakehouse simplifies your data estate by eliminating the silos that historically complicate data and AI.
Unified
One architecture for integration, storage, processing, governance, sharing, analytics and AI. One approach to how you work with structured and unstructured data. One end-to-end view of data lineage and provenance. One toolset for Python and SQL, notebooks and IDEs, batch and streaming, and all major cloud providers.
Open
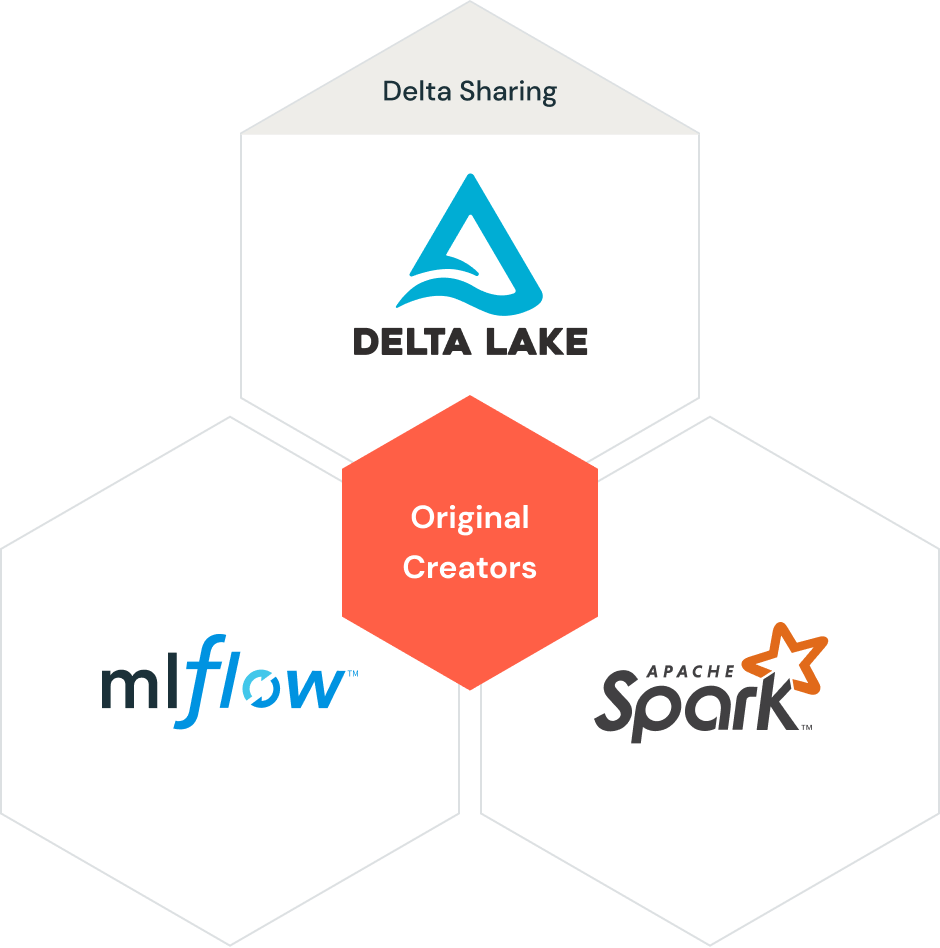
With Databricks, your data is always under your control, free from proprietary formats and closed ecosystems.
Lakehouse is underpinned by widely adopted open source projects Apache Spark™, Delta Lake and MLflow, and is globally supported by the Databricks Partner Network. And Delta Sharing provides an open solution to securely share live data from your lakehouse to any computing platform without replication and complicated ETL.

Scalable
Automatic optimization for performance and storage ensures the lowest TCO of any data platform together with world-record-setting performance for both data warehousing and AI use cases — including generative techniques like large language models (LLMs).
Whether you’re a startup or global enterprise, Databricks is built to meet the demands of your business at any scale.
Unlock the potential of your data — and your data teams
Learn more about how the Databricks Data Intelligence Platform enables your data and AI workloads