Upgrade Production Workloads to Be Safer, Easier, and Faster With Databricks Runtime 7.3 LTS
by Jason Pohl
What a difference a year makes. One year ago, Databricks Runtime version (DBR) 6.4 was released -- followed by 8 more DBR releases. But now it’s time to plan for an upgrade to 7.3 for Long-Term Support (LTS) and compatibility, as support for DBR 6.4 will end on April 1, 2021. (Note that a new DBR 6.4 (Extended Support) release was published on March 5 and will be supported until the end of the year). Upgrading now allows you to take advantage of all the improvements from 6.4 to 7.3 LTS, which has long-term support until Sept 2022. This blog highlights the major benefits of doing so.
DBR 6.4 is the last supported release of the Apache Spark 2.x code line. Spark 3.0 was released in June of 2020 with it a whole bevy of improvements. The Databricks 7.3 Runtime built on the Apache Spark 3.x code line includes many new features for Delta Lake and the Databricks platform as a whole, resulting in these improvements:

Easier to use
DBR 7.3 LTS makes it easier to develop and run your Spark applications thanks to the Apache Spark 3.0 improvements. The goal of Project Zen within Spark 3.0 is to adhere PySpark more closely to Python principles and conventions. Perhaps the most noticeable improvement is the new interface for Pandas UDFs, which leverages Python type hints. This standardizes on a preferred way to write Pandas UDFs and leverages type hints to have a better developer experience within your IDE.
If you haven’t yet converted your Apache Parquet data lake into a Delta Lake, you are missing out on many benefits, such as:
- Preventing data corruption
- Faster queries
- Increased data freshness
- Easy reproducibility of machine learning models
- Easy implementation of data compliance
These Top 5 Reasons to Convert Your Cloud Data Lake to Delta Lake should provide an opportunity to upgrade your Data Lake along with your Databricks Runtime.
Data ingestion from cloud storage has been simplified with Delta Auto Loader, which was released for general availability in DBR 7.2. This enables a standard API across cloud providers to stream data from blob storage into your Delta Lake. Likewise, the COPY INTO (AWS | Azure) command was introduced to provide an easy way to import data into a Delta table using SQL.
Refactoring changes to your data pipeline became easier with the introduction of Delta Table Cloning. This allows you to quickly clone a production table in a safe way so that you can experiment on it with the next version of your data pipeline code without the risk of corrupting your production data. Another common scenario is the need to move a table to a new bucket or storage system for performance or governance reasons. You can easily do this with the CLONE command to copy massive tables in a more scalable and robust way. Additionally, you can specify your own meta-data (AWS | Azure) to the transaction log when committing to delta.
When long-running queries need to be troubleshooted, it is common to generate an explain plan of the query or dataframe. The formatting of large explain plans can be unwieldy to navigate. Explain plans have become much more consumable with the reformatting introduced in Spark 3.0.
Here is an example of an explain plan pre Spark 3.0:
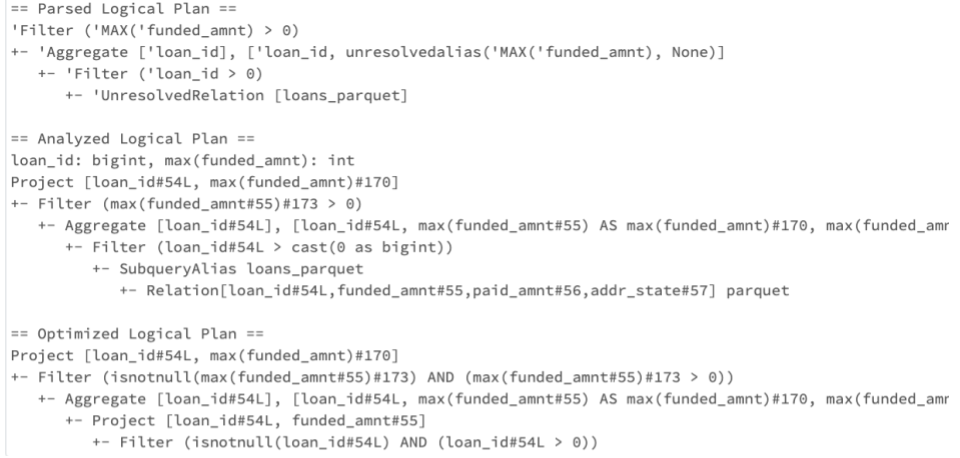
Here is the newly formatted explain plan. It is separated into a Header to show the basic operating tree for the execution plan, and a footer, where each operator is listed with additional attributes.

Finally, any subqueries will be listed separated:

Fewer failures
Perhaps no feature has been more hotly anticipated than the ability for Spark to automatically calculate the optimum number of shuffle partitions. Gone are the days of manually adjusting spark.shuffle.partitions. This is made possible by the new Adaptive Query Execution (AQE) added in Spark 3.0 and was a major step-change to the execution engine for Spark.
Spark now has an adaptive planning component to its optimizer so that as a query is executing, statistics can automatically be collected and fed back into the optimizer to replan subsequent sections of the query.
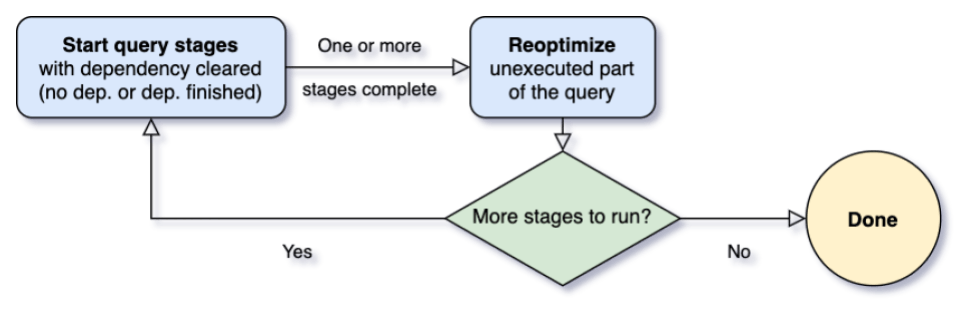
Another benefit of AQE is the ability for Spark to automatically replan queries when it detects data skew. When joining large datasets, it’s not uncommon to have a few keys with a disproportionate amount of data. This can result in a few tasks taking an excessive amount of time to complete, or in some cases, fail the entire job. The AQE can re-plan such a query as it executes to evenly spread the work across multiple tasks.
Sometimes failures can occur on a shared cluster because of the actions of another user, such as when two users are experimenting with different versions of the same library. The latest runtime includes a feature for Notebook-scoped Python Libraries (AWS | Azure). This ensures that you can easily install Python libraries with pip, but their scope is limited to the current notebook and any associated jobs. Other notebooks attached to the same Databricks cluster are not affected.
Improved performance
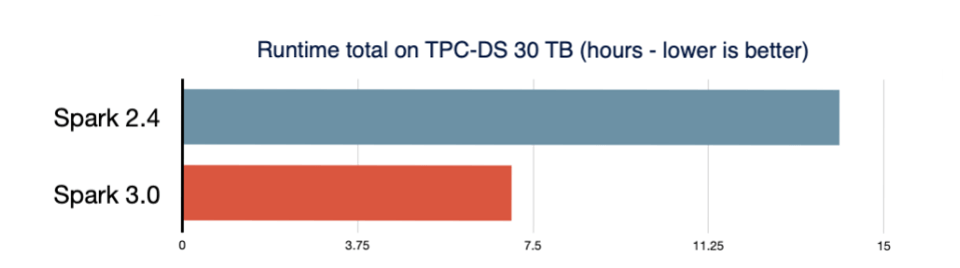
In the cloud, time is money. The longer it takes to run a job, the more you pay for the underlying infrastructure. Significant performance speedups were introduced in Spark 3.0. Much of this is due to the AQE, dynamic partition pruning, automatically selecting the best join strategy, automatically optimizing shuffle partitions and other optimizations. Spark 3.0 was benchmarked as being 2x faster than Spark 2.4 on the TPC-DS 30TB dataset.
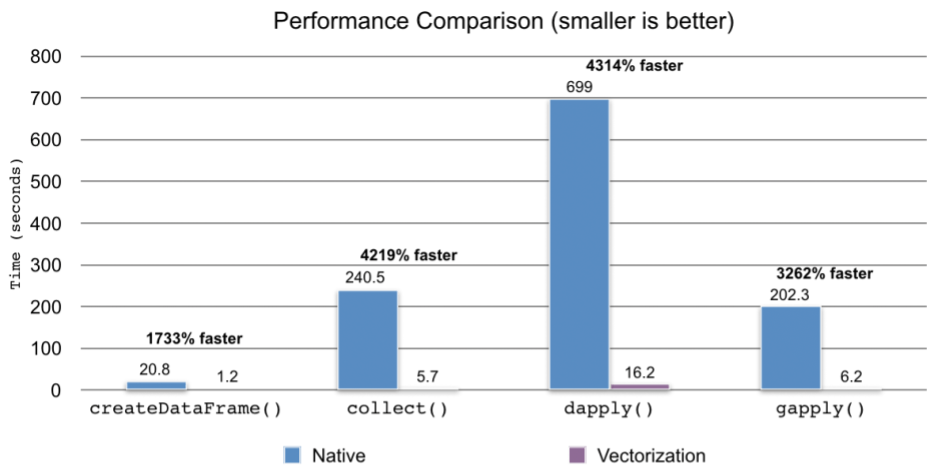
UDFs created with R now execute with a 40x improvement by vectorizing the processing and leveraging Apache Arrow.
Finally, our Delta Engine was enhanced to provide even faster performance when reading and writing to your Delta Lake. This includes the collection of optimizations that reduce the overhead of Delta Lake operations from seconds to tens of milliseconds. We introduced a number of optimizations so that the MERGE statement performs much faster.
Getting started
The past year has seen a major leap in usability, stability, and performance. If you are still running DBR 6.x, you are missing out on all of these improvements. If you have not upgraded yet, then you should plan to do so before extended support ends at the close of 2021. Doing so will also prepare you for future improvements that are to be released for Delta Engine later this year--all dependent on Spark 3.0 APIs.
You can jumpstart your planning by visiting our documentation on DBR 7.x Migration - Technical Considerations (AWS | Azure), and by reaching out to your Account Team.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.