あらゆるユースケースに対応するストリーミング・アーキテクチャが必要な時が来た!

今日のデータ主導の世界では、企業はかつてない規模のデータを効率的に取り込み、処理するという課題に直面している。 常に生成されるビジネスクリティカルなデータの量と多様性により、アーキテクチャの可能性は無限に近い。 良いニュースは? これはまた、スループット、レイテンシー、コスト、運用効率など、データアーキテクチャをさらに最適化できる可能性が常にあることを意味する。
多くのデータ専門家は、"データストリーミング" や"ストリーミングアーキテクチャ" といった用語を、ほとんどのワークロードにとって複雑でコストがかかり、実用的でないように見える超低レイテンシのデータパイプラインと関連付けている。 しかし、Databricks Lakehouse Platform上でストリーミングデータアーキテクチャを採用したチームは、 ほとんどの場合、スループットの向上、運用オーバーヘッドの削減、コストの大幅削減というメリ��ットを得ることができます。 これらのユーザーの中には、サブ秒単位のレイテンシーでリアルタイムにジョブを実行する者もいれば、1日に1回程度の頻度でジョブを実行する者もいる。 独自のSpark Structured Streamingパイプラインを構築するチームもあれば、Spark Structured Streaming上に構築された宣言的アプローチであるDLTパイプラインを使用するチームもあり、インフラや運用のオーバーヘッドはすべて自動的に管理される(多くのチームは両方を組み合わせて使用している)。
あなたのチームの要件やSLAがどのようなものであれ、集中型データ処理、データウェアハウス、AIのためのレイクハウス・ストリーミング・アーキテクチャが、他のアプローチよりも高い価値を提供することは間違いない。 このブログでは、一般的なアーキテクチャ上の課題、Spark Structured Streamingがそれらに対処するために特別に設計された方法、そしてDatabricks Lakehouse Platformが、今日のデータチームの時間とコストを節約するストリーミングアーキテクチャの運用に最適なコンテキストを提供する理由について説明します。
バッチからストリーミングへの移行
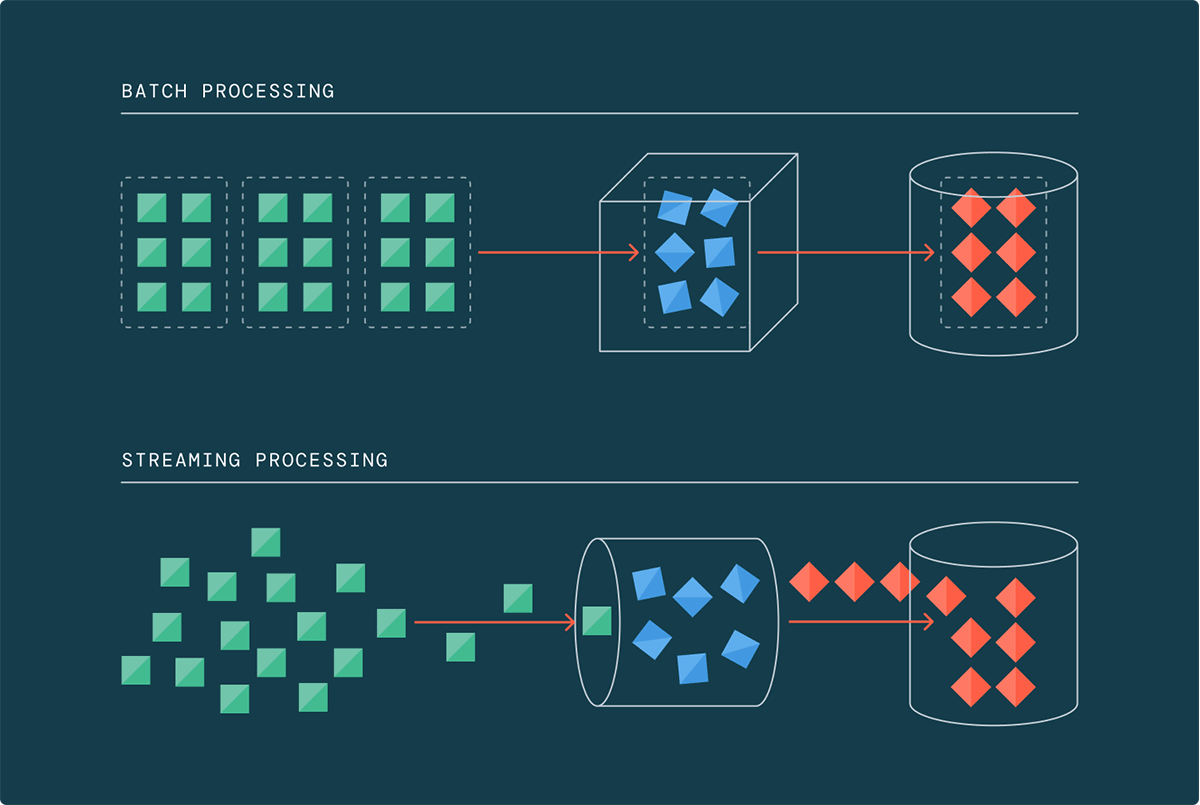
従来、データ処理はバッチで行われ、予定された間隔でデータが収集され、処理されていた。 しかし、データ量、速度、種類が指数関数的に増え続けるビッグデータの時代には、このアプローチはもはや適切ではない。 過去2年間だけで、世界のデータの90%が生成されたため、従来のバッチ処理フレームワークでは追いつくのに�苦労している。
そこで活躍するのがデータストリーミングだ。 ストリーミング・アーキテクチャーによって、データ・チームはデータが到着するたびに段階的にデータを処理できるようになり、大量のデータが蓄積されるのを待つ必要がなくなる。 テラバイトやペタバイトの規模で運用する場合、データを蓄積させることは現実的でなく、コストもかかる。 ストリーミングは何年にもわたってビジョンと約束を提供してきたが、今日ようやくそれを実現できるようになった。
一般的なユースケースの再考:ストリーミングは新常識
世界はますますリアルタイムのデータへの依存度を高めており、データの鮮度は大きな競争優位性となり得る。 しかし、データの鮮度が高ければ高いほど、一般的に高価になる。 "パイプラインを可能な限りリアルタイムで" 。しかし、具体的なユースケースを掘り下げてみると、パイプラインの稼働時間を6時間から15分以下に短縮できれば十分満足だということがわかる。 他の顧客は、秒単位やミリ秒単位でしか測定できないレイテンシーを本当に必要としている。

ユースケースをバッチかストリーミングかに分類するのではなく、ストリーミング・アーキテクチャのレンズを通してあらゆるワークロードを見る時が来た。 スライダーは1つで、片方ではパフォーマンスを、もう片方ではコスト効率を最適化するように調整できると考えてほしい。 要するに、ストリーミングでは、超低遅延から数分、あるいは数時間まで、各作業負荷に最適な位置にスライダーを設定できる。
我らがディロン・ボストウィックが、私よりもうまく言ってくれた:"私たちは、ストリーミングを複雑な"リアルタイム" ユースケースのために予約するという考え方から抜け出さなければならない。その代わりに、"Right-time処理に使うべきだ。"
Spark Structured Streamingは、このスライダーを調整できる統合フレームワークを提供し、企業やデータエンジニアに大きな競争上の優位性��をもたらす。 データの鮮度は、インフラを大幅に変更することなく、ビジネス要件に対応することができる。
多くの一般的な定義に反して、データストリーミングは必ずしも連続的なデータ処理を意味しない。 ストリーミングは基本的にインクリメンタリゼーションだ。 インクリメンタル処理を許可するタイミングは、常にオンか、特定の間隔でトリガーするかを選択できる。 ストリーミングは超新鮮なデータには理にかなっているが、従来バッチと考えられてきたデータにも適用できる。
レイクハウスでのストリーミングで未来に備える
データアーキテクチャの将来性を考慮する。 ストリーミング・アーキテクチャは、レイテンシー、コスト、スループットの要件を進化に合わせて調整できる柔軟性を備えている。 ここでは、完全なストリーミングアーキテクチャの利点と、Databricks Lakehouse Platform上のSpark Structured Streamingがそのために設計されている理由を説明する:
スケーラビリティとスループット:ストリーミング・アーキテクチャは、インフラを大きく変更することなく、本質的にスケールし、さまざまなデータ量に対応します。 Spark Structured Streamingは、特にPhotonを活用したDatabricks上でスケーラビリティとパフォーマンスに優れている。
多くのユースケースでは、チームが許容可能なレイテンシSLAを達成している限り、高いスループットを処理する能力がより重要になる。 Spark Structured Streamingは、1秒あたり数百万のイベントで秒��以下のレイテンシーを達成することができます。これが、AT&TやAkamaiのようなペタバイトのデータを定期的に扱う企業が、ストリーミングワークロードにDatabricksを信頼している理由だ。"Databricksは、Comcastが毎日何十億ものトランザクションと何テラバイトもの[ストリーミング]データを処理する規模に拡大するのに役立っている。" - ヤン・ノイマン、コムキャスト、機械学習担当副社長
"Delta Live Tablesのおかげで、数兆レコード規模のデータ管理にかかる時間と労力を節約し、AIエンジニアリング能力を継続的に向上させることができました。" - シェル、データサイエンスGM、ダン・ジーボンズ
"DLTをスケールさせるために何もする必要はなかった。 システムに多くのデータを与えれば、それに対応する。 箱から出せば、どんな状況にも対応できるという自信を与えてくれた。" - ハネウェル、グローバル・ソリューション・アーキテクト、クリス・インクペン博士
シンプルさ:増分更新を行うバッチジョブを実行する場合、一般的に、どのデータが新しく、何を処理すべきで、何を処理すべきでないかを考えなければならない。 構造化ストリーミングは、ブックキーピング、フォールトトレランス、ステートフルなオペレーションを処理し、手作業で監視することなく、"exactly once" 保証を提供する。 特にデルタ・ライブ・テーブルを使ったストリーミング・ジョブの設定と実行は、驚くほど簡単だ。
"Databricks Lakehouse Platformでは、実際のストリーミングの仕組みが抽象化されている。これにより、ストリーミングの増強が非常にシンプルになった。" - パブロ・ベルトラン、Statsigソフトウェア・エンジニア
"デルタ・ライブテーブルを気に入っているのは、オートローダーの機能を超えて、ファイルの読み込みをさらに簡単にしてくれるからです。 45分でストリーミング・パイプラインをセットアップできたときには、顎が外れました。データのバケツにソリューションを向けるだけで、すぐに稼働できたのです。" - ラベルボックス、シニア・データ・エンジニア、カーヴェ・サラムート
"DLTは、消費データセットを作成する最も簡単な方法である。 私たちは少人数のチームなので��、DLTはとても時間を節約してくれる。" - イヴォ・ヴァン・デ・グリフト、エトス(Ahold-Delhaizeブランド)データチーム技術リーダー
リアルタイムのユースケースのためのデータ鮮度:ストリーミング・アーキテクチャは、リアルタイムの意思決定や異常検知にとって重要な利点である、最新のデータを保証します。 低レイテンシーが鍵となるユースケースでは、Spark Structured Streaming(そしてその延長線上にあるDLTパイプライン)は、固有のサブセカンドレイテンシーをスケールで実現できる。
超低遅延を必要としないユースケースでも、遅延のばらつきを減らすことで恩恵を受けることができる。 ストリーミング・アーキテクチャは、より一貫した処理時間を提供し、サービスレベル・アグリーメントを満たし、予測可能なパフォーマンスを確保することを容易にする。 Databricks上のSpark Structured Streamingでは、ユースケースに適したレイテンシー/スループット/コストのトレードオフを正確に設定できる。"私たちのビジネス要件では、データの鮮度を高めることが求められており、ストリーミング・アーキテクチャでなければ実現できませんでした。" - パルヴィーン・ジンダル、ヴィジオ、ソフトウェア・エンジニアリング・ディレクター
"私たちはDatabricksを高速で動くデータのために使用しています。 店舗でもオンラインでも、患者さんのニーズに応えるスピードを変えるのに本当に役立っています。" - ウォルグリーンズ、プロダクト・エンジニアリング・ディレクター、サシ・ヴェンカテサン氏
"分析に利用できるデータのスピードが大幅に向上した。 以前は6時間かかっていた仕事が、今ではわずか6秒で済むようになった。" - アレッシオ・バッソ、HSBCチーフアーキテクト
コスト効率:Spark Structured StreamingまたはDLT on Databricksを使用してストリーミングアーキテクチャに移行したほぼすべてのお客様が、即座に大幅なコスト削減を実現している。 ストリーミング・アーキテクチャを採用することで、特に変動ワークロードの場合、大幅なコスト削減につながる。 Spark Structured Streamingでは、データ処理時にのみリソースを消費するため、バッチ処理用の専用クラスタが不要になる。
DLTパイプラインを使用する顧客は、開発速度の向上と、デプロイメント・インフラストラクチャ、依存関係のマッピング、バージョン管理、チェックポイントと再試行、バックフィル処理、ガバナンスなどのような運用の細々とした管理に費やす時間の大幅な削減によって、さらなるコスト削減を実現している。"より多くのリアルタイムかつ大容量のデータフィードが[Databricks上で]利用できるようになるにつれて、ETL/ELTコストは、レガシーなマルチクラウドデータウェアハウスのETL/ELTコストと比較して、比例して直線的に増加しました。" - ジェットブルー、データサイエンス担当シニアマネージャー、サイ・ラブル& アナリティクス
"何より素晴らしいのは、これらすべてをよりコスト効率よく行えることだ。 以前のマルチクラウド・データウェアハウスと同じコストで、より速く、より協力的に、より柔軟に、より多くのデータソースで、より大規模に作業することができます。" - アレクサンダー・ブース(テキサス・レンジャーズ、R&D部門アシスタント・ディレクター
"Databricksによって、価格とパフォーマンスを最適化することができました。インフラコストは以前より34%削減され、ETLパイプラインの実行コストも24%削減されました。 さらに重要なのは、実験率が飛躍的に向上したことだ。" - モヒト・サクセナ、インモビ共同創業者兼グループCTO
リアルタイムデータとヒストリカルデータの統合ガバナンス:Databricks Lakehouse Platform上で一元化されたストリーミングアーキテクチャは、リアルタイムデータとヒストリカルデータにまたがる統一されたガバナンスを容易に確保する唯一の方法だ。 DatabricksだけがUnity Catalogを搭載しており、これは湖上におけるデータとAIのための業界初の統合ガバナンス・ソリューションである。 Unity Catalogによるガバナンスは、データおよびAIイニシアチブを加速させるとともに、簡素化された方法で規制コンプライアンスを確保し、ストリーミング・パイプラインおよびリアルタイム・アプリケーションが、単一のガバメントされたデータ・プラットフォームのより広いコンテキストに収まるようする。
"ETLやエンジニアリングからアナリティクスやMLまで、すべてを同じ傘下で行うことで、障壁が取り除かれ、誰もがデータと互いに取り組みやすくなる。" - セルゲイ・ブランケット、Grammarlyビジネスインテリジェンス部長
"Unityカタログをサポートする前は、S3ストレージにデータをストリーミングするために別のプロセスとパイプラインを使用し、そこからデータテーブルを作成するために別のプロセスを使用する必要がありました。 Unityカタログの統合により、DLTパイプラインから直接テーブルを合理化、作成、管理できる。" - ユエ・チャン、ブロック・スタッフ・ソフトウェア・エンジニア
"Databricksのおかげで、コロンビアのEIMチームはETLとデータ準備を加速させることが��でき、ETLパイプラインの作成時間を70%削減するとともに、ETLワークロードの処理時間を4時間からわずか5分に短縮することができました......より多くのビジネス部門が、以前は不可能だったセルフサービス方式で企業全体で利用しています。 Databricksがコロンビアに与えたポジティブな影響については、言葉では言い尽くせません。" - コロンビア・スポーツウェア、シニア・エンタープライズ・データ・マネージャー、ララ・マイナー氏
ストリーミング・アーキテクチャは、データ生成が加速し続ける中、進化するニーズに対応するデータ・インフラストラクチャを準備する。 リアルタイムのデータ処理に今から備えることで、増大するデータ量と進化するビジネス・ニーズに対応できるようになる。 言い換えれば、レイテンシSLAが進化しても、再設計する必要はなく、スライダーを簡単に調整することができる。
ストリーミング・アーキテクチャのためのDatabricks入門
2,000社以上のお客様がDatabricks Lakehouse Platform上で毎週1,000万以上のストリーミングジョブを実行しているのには、いくつかの理由がある。 ストリーミング・アーキテクチャの構築においてDatabricksが信頼されている理由は以下の通りである:
- マルチクラウドのデータウェアハウスとは異なり、Databricksでは実際にストリーミングを行うことができる。
- Flinkと違って、(1)非常にシンプルで、(2)好きなときに好きなようにコスト/レイテンシーのスライダーを設定できる。
- ネイティブのパブリッククラウドソリュー��ションとは異なり、複数のサービスをつなぎ合わせる必要のない、シンプルな統一プラットフォームである。
- 他のプラットフォームとは異なり、チームが自分に合った導入方法を選択できる。 独自のSpark Structured Streamingパイプラインを構築したり、Delta Live Tablesで運用の複雑さをすべて抽象化することができます。 実際、多くの顧客は、異なるパイプラインで両方をミックスしている。
ここでは、Databricksでストリーミングアーキテクチャの探求を始める方法をいくつか紹介する:
- ストリーミングと デルタ・ライブ・テーブルの製品ページを見る
- その他のカスタマーストーリーはこちら
- 10億レコードのETLを1ドルで実行した方法を読む
- ストリーミングとDLTデモのカタログはこちらからご覧ください。 DLT製品ツアー、CDCパイプライン・デモ、アドバンスド・ストリーミング・デモなどから始めるといいだろう。
- DatabricksとDelta Live Tables でストリーミングを開始するためのドキュメントを確認する。
まとめ
ストリーミング・アーキテクチャには、従来のバッチ処理と比較していくつかの利点があり、その必要性はますます高まっている。 Spark Structured Streamingでは、将来性のあるストリーミングアーキテクチャを今すぐ実装し、コスト対効果のチューニングを簡単に行うことができます。 レイテンシー。 DatabricksはSparkワークロードを実行するのに最適な場所だ。
もしあなたのビジネスが24時間365日のストリームとリアルタイムの分析、ML、または運用アプリケーションを必要とするなら、Structured Streamingの連続モードでクラスタを24時間365日稼働させましょう。 そうでない場合は、Trigger = AvailableNowでStructured Streamingのインクリメンタルバッチ処理を使う。 (特に、常時オンとトリガーストリーミングのバランスをとることによるコストの最適化については、当社のドキュメントを参照してください)。 いずれにせよ、DLTパイプラインは運用のオーバーヘッドの大部分を自動化するものだと考えてほしい。
要するに、大量のデータを処理するのであれば、ストリーミング・アーキテクチャを実装する必要があるということだ。 1日1回から1秒に1回以下まで、Databricksは簡単でコストを削減します。



{kind=link}
{kind=link}