MemEx: A Programmable Scratchpad for LLM Agents
In 1945, Vannevar Bush imagined a desk-sized machine that would extend a scientist's memory by storing every document, annotation, and trail of thought for recall on demand. He called it the MemEx. Bush was solving a human problem: minds overwhelmed by information they couldn't keep at hand. Eight decades later, LLM agents are hitting a remarkably similar wall.
In the current Agentic Tool Calling paradigm, the context window is the only persistent substrate the model can operate over. It is a shared space carrying the system prompt, the user's query, the model's reasoning, tool calls, and raw tool outputs. Tool outputs are the worst offenders: a single SQL query might return millions of rows, and in today's harnesses those rows ride along in every subsequent turn even if only one cell ever mattered. The agent has no way to slice, summarize, or stash the result before it floods the window.
We hit this wall constantly at Databricks. Our production agents, from Genie to Agent Bricks, run into the same context limitations at some point. Genie provides a clean example: a single query searches a customer's entire workspace, calling many tools to pull data from tables, vector indices, and dashboards. To address this, we built a MemEx of our own, and validated it inside multiple production and internal agents.
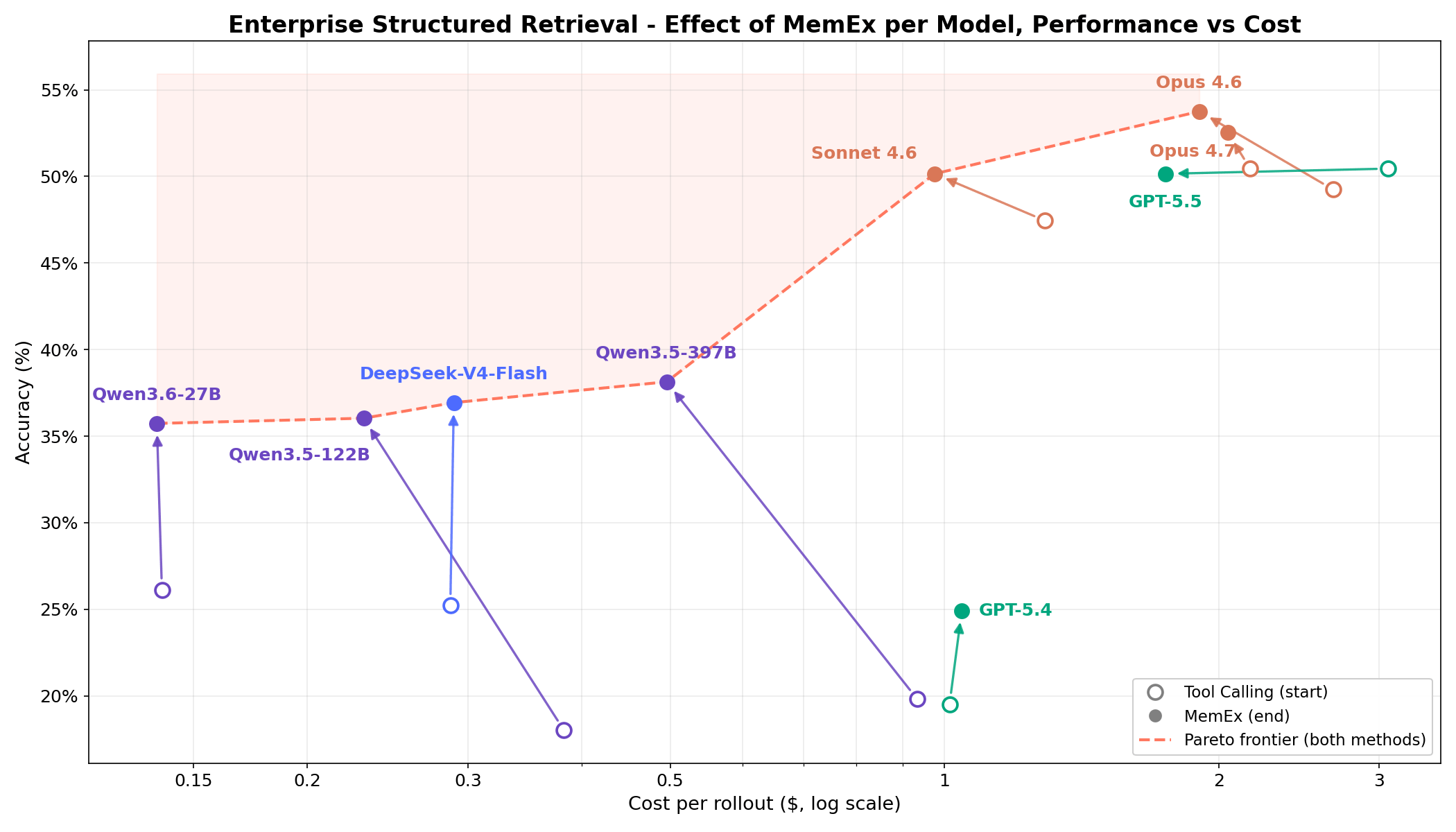
On hard enterprise structured retrieval tasks, Figure 1 shows that MemEx pushes the cost-vs-accuracy frontier for every model. Frontier models like Opus 4.6 and Sonnet 4.6 gain 2–5 percentage points at 25–30% less token cost. Open-weights models like Qwen3.5-122B (18% → 36%) and Qwen3.5-397B (20% → 38%) nearly double their accuracy at 40–50% less token cost. Because MemEx can operate over arbitrarily long inputs, it also unlocks two further applications: auditing agent trajectories, including MemEx's own, that wouldn’t normally fit in a single context window and parallel thinking across multiple trajectories.
How MemEx works
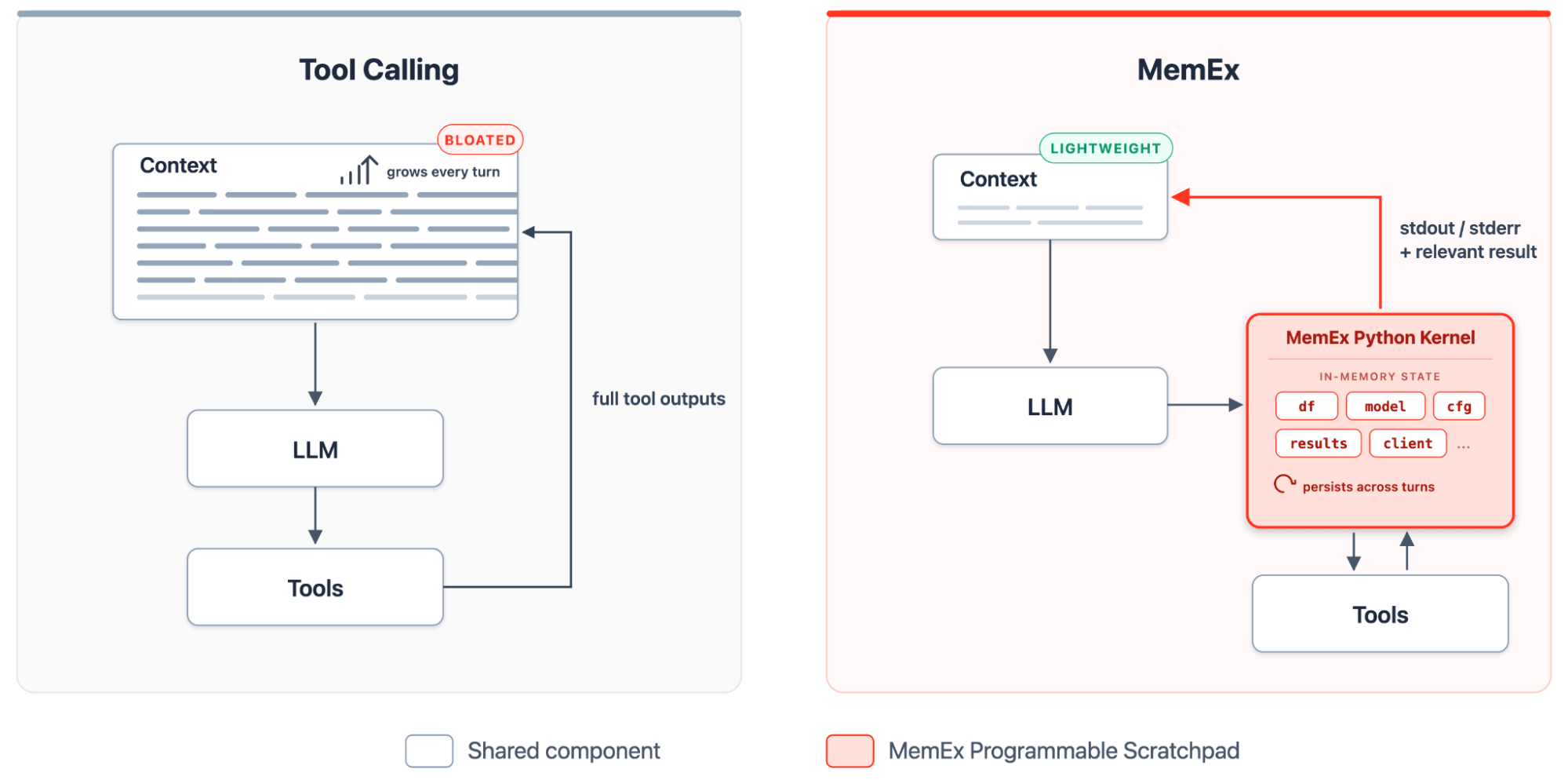
MemEx gives the LLM a programmable scratchpad: a typed Python kernel that holds tool outputs, transforms them with code, and materializes only the print statements as tokens in the context. Inside this environment, the rollout becomes a self-extending Python program. During each turn, the agent authors a new block, the kernel keeps state alive, and the next block builds on what came before. Tools are exposed as typed Python functions with typed parameters and typed return values. Tool outputs land as Python objects in MemEx's scope, where they persist across turns. The agent composes them with code, defines helper functions when a pattern repeats, and spawns sub-agents as asynchronous function calls over the same scope.
MemEx is in the code-as-action family introduced by CodeAct (Wang et al., 2024), with production variants in Anthropic's Programmatic Tool Calling and Cloudflare Code Mode. MemEx sets itself apart by dropping into an existing ReAct (Yao et al., 2022)-style agentic framework, with persistent scope, sub-agent primitives, and typed returns wired in. Together, these unlock capabilities the JSON/XML tool calling paradigm lacks:
- Handling arbitrarily large inputs: Documents, datasets, and other large objects can be kept in Python scope as variables.
- Returning typed objects: Tool outputs are typed Python objects kept in memory, not strings the model has to materialize or re-parse on every turn.
- Composing tool calls: One call's output flows directly into the next call's arguments within a single line of code. Intermediate outputs do not need to be materialized in the agent’s context.
- Slicing tool outputs: Outputs can be preprocessed, filtered, or summarized in code before the model sees them.
- Spawning asynchronous sub-agents: Agents can programmatically spawn sub-agents that run alongside the parent, and aggregate their results without round-tripping through the main model.
Example of LLM Agent with MemEx
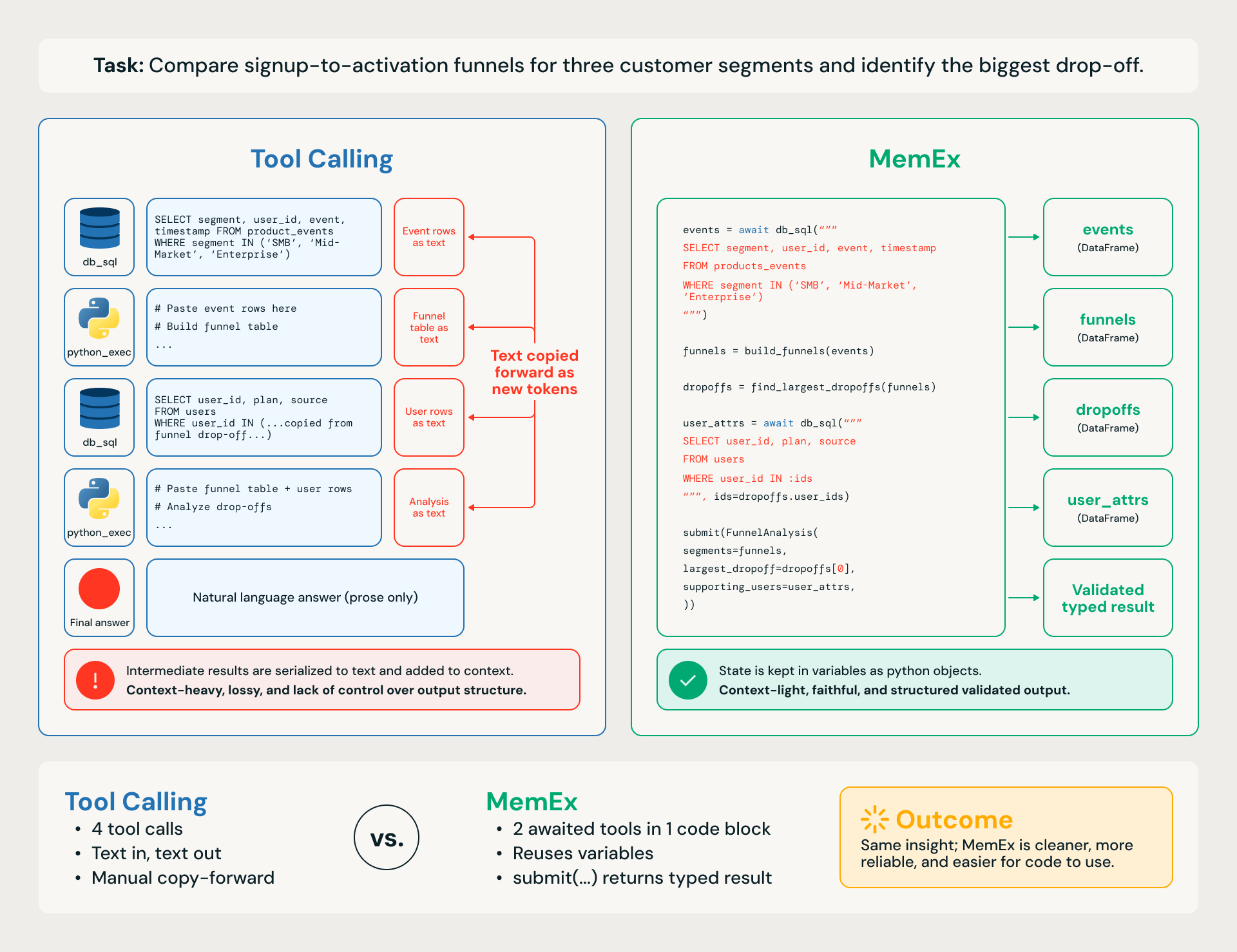
Take a concrete enterprise task such as comparing signup-to-activation funnels for three customer segments and identifying the biggest drop-off (Figure 1). The workflow has four steps:
- retrieve signup and activation events from the data warehouse
- join them per user
- compute per-segment conversion rates at each stage
- rank the drop-offs across segments.
A Tool Calling agent equipped with python_exec works one step at a time. Each SQL query and each programmatic computation is a separate tool call, with intermediate DataFrames serialized to text and re-pasted into subsequent turns. The trace is token-heavy, which makes it lossy, slow, expensive, and prone to small cascading errors in the downstream task.
A MemEx agent writes the same workflow as a single code block: queries return native DataFrames in scope, helper functions compose them, and the final answer comes back as a typed validated object via submit(). Same thought, different action space.
For tasks that decompose into sub-problems, the agent can spawn sub-agents from inside a block. When spawning sub-agents, the parent agent can pass shared access to any object. Sub-agents run eagerly in parallel with the parent and can return results to the main agent upon completion. For example:
Recursive decomposition becomes another expression in the same Python program.
MemEx is developed on top of aroll, Databricks' agentic rollouts framework. Aroll already powers production systems like Genie, Agent Bricks' Supervisor Agent, and research efforts like KARL. MemEx plugs into the same agent loop and tools that aroll already uses for Tool Calling.
How does MemEx perform in enterprise agentic tasks?
We ran head-to-head evals across 9 frontier models where we compared parallel structured tool calls (Tool Calling) vs. Python code blocks (MemEx). No prompt tuning, no per-task adaptation. We compare across two shapes of enterprise agentic work: grounded reading over a large text corpus (OfficeQA), and structured retrieval over a large workspace of diverse relational data (Enterprise Structured Retrieval).
On both tasks, MemEx Agent is better and cheaper than Tool Calling Agent!
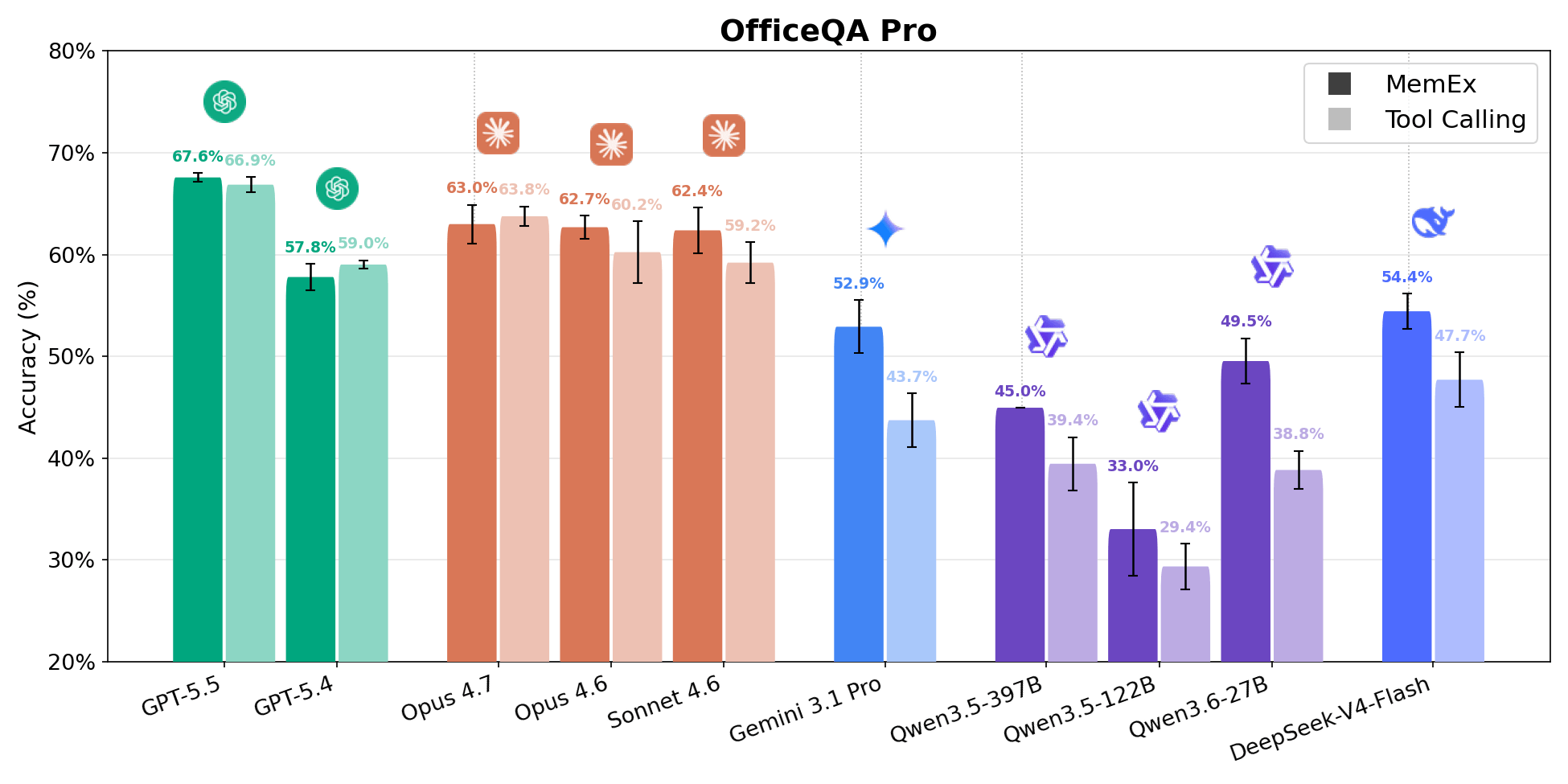
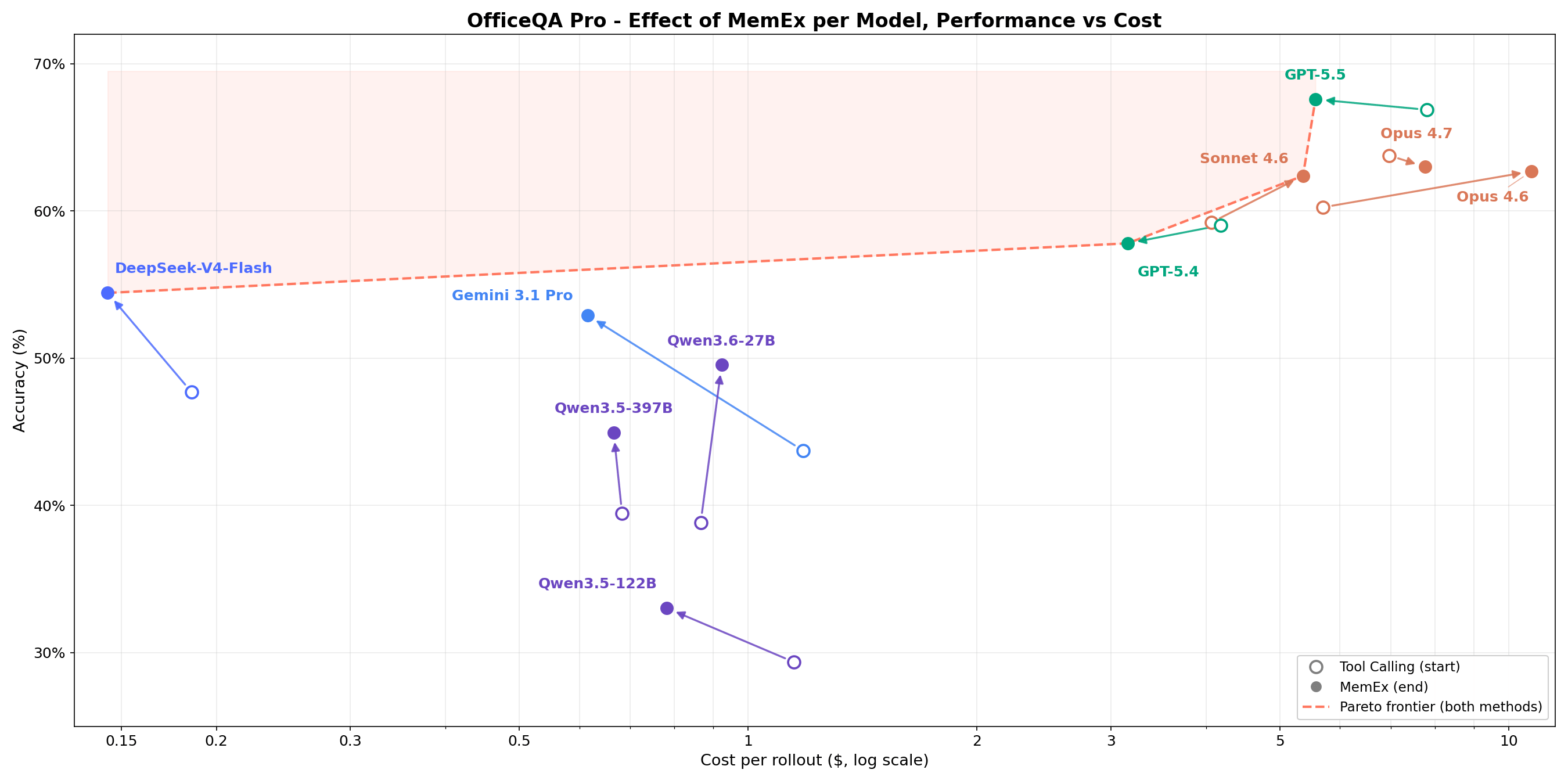
OfficeQA Pro asks the agent to answer grounded reasoning questions over the U.S. Treasury Bulletins corpus, roughly 89,000 pages spanning 1939 to present. A typical question requires locating evidence across multiple documents, navigating tables with nested hierarchies and merged cells, and running calculations on the retrieved data. Answers are graded by strict match. Four of the five points on the cost-vs-accuracy pareto frontier are MemEx configurations. Gemini 3.1 Pro MemEx is the cheapest frontier point at $0.62 per rollout (52.9% accuracy), and Sonnet 4.6 MemEx approaches GPT-5.5 Tool Calling accuracy at roughly 70% of the cost. Across nine models, MemEx ties or wins on every model. The middle of the pack moves the most, with Qwen 3.6 27B and Gemini 3.1 Pro gaining around 10 percentage points.
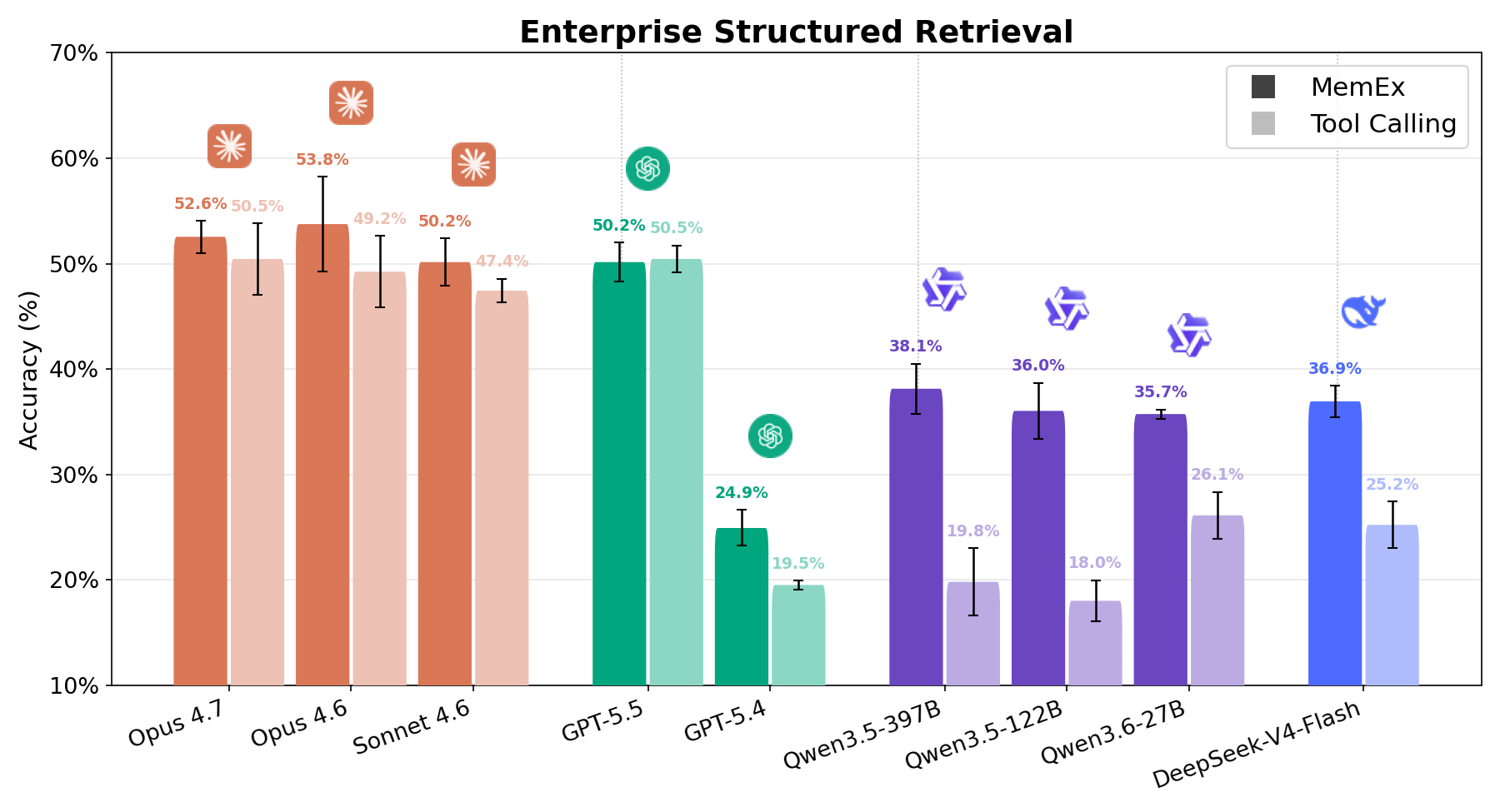
Enterprise Structured Retrieval asks the agent to answer natural-language questions over enterprise relational data. The agent is provided with tools related to schema-discovery and SQL-query-execution, and must use these to perform the data analysis task requested by the user, usually with little information about where in the diverse workspace to find the relevant information. The agent’s answers are graded against ground truth responses using both deterministic data validation and LLM-as-a-judge. As seen in Figures 1 and 6, every model shows strong gain under MemEx, excluding GPT 5.5 which shows parity performance. Cost-wise, the story is just as strong. Qwen 122B drops from 56 to 28 tool calls per rollout while doubling its score; Sonnet from 28 to 17; Opus from 33 to 21.1 This results in roughly halving the cost across most models. The pattern echoes OfficeQA Pro: the harder the task, the more native objects and persistent state earn their keep.
Each comparison ran with no prompt tuning, no per-task adaptation, and no model-specific tweaks. The agent loop, system prompts, and tools are identical across both harnesses. The only difference is the action space, JSON/XML structured tool calls versus MemEx’s Python code blocks.
MemEx Operating on Agentic Traces
Agentic trajectories are themselves bulky objects. In the Tool Calling paradigm, analyzing trajectories generally requires flattening them into text which is lossy and context-heavy, and analyzing several at once is often infeasible. Trajectories may even span multiple context windows, with compression in between; how can an LLM analyze a trace that, by definition, doesn’t fit in its context? But a trajectory is just another Python object, so MemEx can load it directly into scope and reason over it. We show two applications: first, a MemEx-based audit agent that analyzes Qwen 3.6-27B trajectories on OfficeQA-Pro to explain why MemEx outperforms Tool Calling; second, test-time scaling on OfficeQA-Pro, with a MemEx agent that beats an equivalent Tool Calling agent.
MemEx audits MemEx: Agentic Trace Analysis
To analyze why switching to MemEx resulted in a performance boost for open-source models, such as Qwen 3.6-27B, we turn to MemEx to explain. In particular, we instantiate an audit agent that takes an OfficeQA question, its ground-truth answer, and six solver trajectories (3 from a MemEx agent and 3 from a Tool Calling agent) directly into its Python scope, and asks a MemEx-based Sonnet 4.6 agent to classify every wrong trajectory along a four-axis taxonomy of failure modes.
| Failure Axis | Definition | MemEx errors | Tool Calling errors |
|---|---|---|---|
Source Selection | The model targets the incorrect document or table | 32 | 45 |
Interpretation | The model retrieves the correct data but extracts the wrong meaning | 28 | 38 |
Search Strategy | The model stops too early or wanders past the answer | 6 | 15 |
Execution | Bugs in intermediate compute or the final output formatting | 3 | 6 |
Total | - | 69 | 104 |
Our analysis focuses on 66 OfficeQA Pro questions where not all six attempts were correct or incorrect, yielding 173 trajectories. The four axes split into two broad groups:
- Grounding errors (~83%): Cases where the model retrieves a preliminary value instead of a revised figure, misinterprets ambiguous terminology (e.g., sample vs. population variance, or rounding precision for "hundredths"), or extracts the incorrect column from a valid table.
- Search Strategy and Execution errors: Error in planning the retrieval sequence or failure to correctly integrate retrieved data into final computations.
For Search Strategy and Execution errors, MemEx finds that the MemEx agent had a 2x reduction in error compared to Tool Calling. This is because, for MemEx, retrieval can land directly in Python variables, so the model can avoid copying values from one tool's output into the next tool call, and multiple tool calls can batch in a single turn. Tool Calling has no such shortcut and must always transcribe values between calls, which sometimes slips. For example, in one trajectory, a value of 3,501 from a retrieved document was retyped into the next call as 3531.
Agentic Parallel Thinking with MemEx
A common approach to scaling test-time computation is parallel thinking, where multiple independent rollouts of a task are aggregated into a final answer. In agentic parallel thinking, such as the approach used in KARL, summaries of the independent attempts are passed to an aggregator agent. This summarization step is lossy but unavoidable in the standard setup, since fitting multiple full trajectories into a model's context window is impractical. With MemEx, we can instead load these trajectories as scope variables, sidestepping the lossy representation entirely.
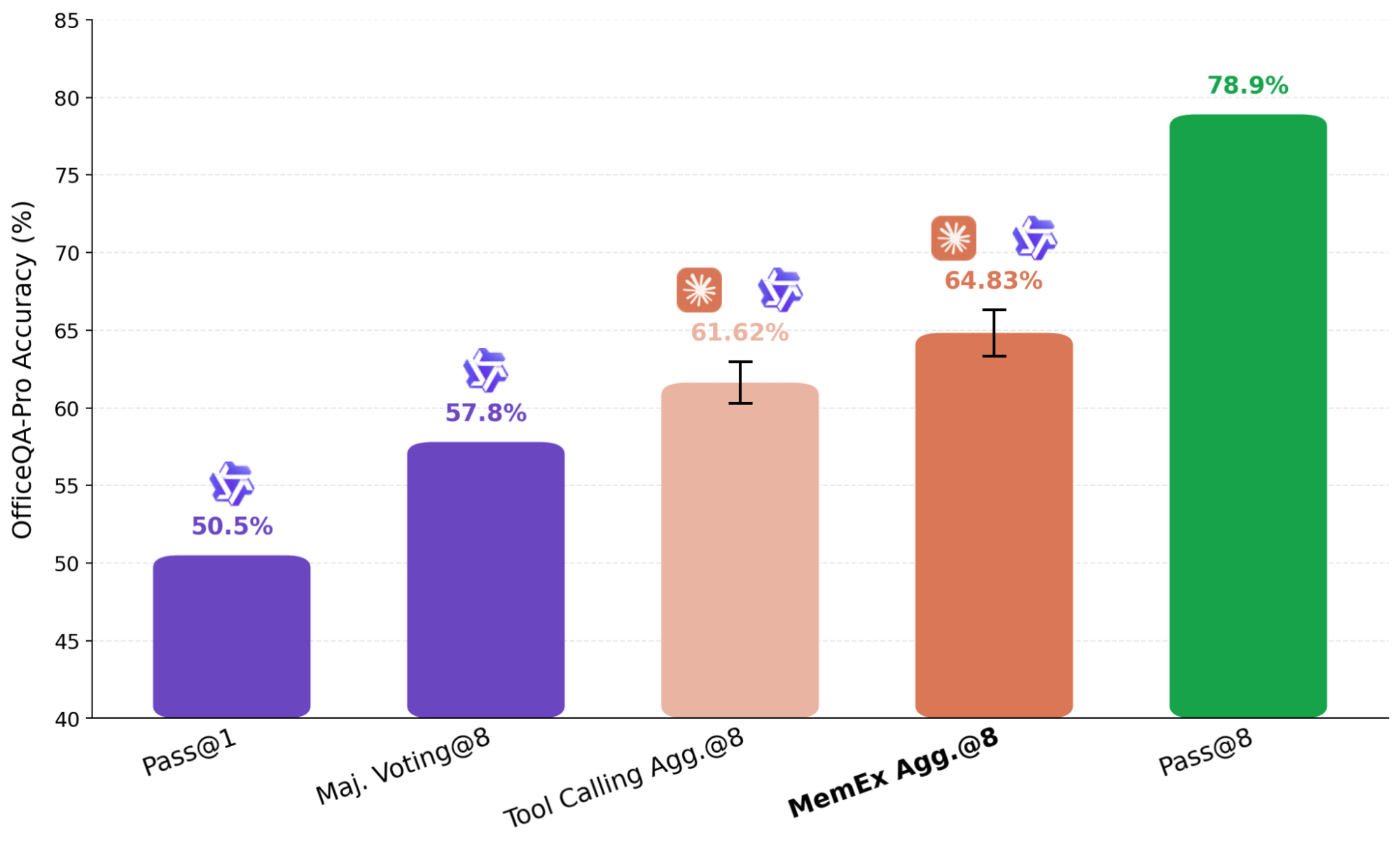
In the result shown in Figure 7, we use Claude Sonnet 4.6 as an aggregator over eight independently generated Qwen-3.6-27B trajectories. To ensure the aggregator isn't simply re-solving the problem on its own, we strip out its file search tools, restricting it to verification and selection. The MemEx-based agent, which receives the full trajectories as input, outperforms the equivalent Tool Calling agent that receives only their summaries. In one case, the trajectory aggregator caught a duplication error in an earlier bulletin by reading raw tool outputs from input trajectories; the Tool Calling aggregator couldn't verify the duplicate-data claim due to its input being limited to the summaries, and fell back on majority vote on the corrupted source.
MemEx Architecture
Tool Calling agents emit one or more structured tool calls per turn (JSON or XML), each conforming to a predefined tool schema, in the action-observation loop introduced by ReAct (Yao et al., 2022). CodeAct (Wang et al., 2024) replaced that format with a persistent Python kernel: the agent emits arbitrary Python code, and variables and function definitions carry across turns. Production variants of the same paradigm include Anthropic's Programmatic Tool Calling (PTC) and Cloudflare Code Mode; PTC also keeps state across requests by reusing the same container, while Code Mode does not. MemEx extends this paradigm with four additions on top:
- Drop-in tool integration with parameter schemas preserved.
- Live Python scope at rollout start.
- Typed
submit()for structured returns. - Non-blocking
spawn_agent()for parallel sub-agents, generalizing Recursive Language Models (Zhang et al., 2025).
The implementation rests on three design choices:
Code as action, in a persistent REPL
The agent's action is an arbitrary Python code block, executed in a namespace that persists across turns. Tools, scope objects, and prior results all live in that namespace. The agent reads observations (stdout, return values, errors), then writes more code. The same observe-act loop that runs Tool Calling runs MemEx; only the action space changes.
Drop-in for Tool Calling
Existing Tool Calling tools are auto-injected as Python functions, including parameter schemas and return-type metadata. Switching an existing agent from Tool Calling to MemEx is a single configuration change.
Backend-agnostic execution
The same agent code runs in three backends, picked at config time:
- In-process for fast iteration during research.
- Subprocess for isolation during evaluation.
- Pool for high-throughput batch generation (training data, large-scale rollouts).
For production deployments, the kernel can be swapped for a hosted sandbox like Anthropic's Managed Agents. Same agent code, with filesystem isolation, network egress controls, and resource caps handled by the host.
What's next?
MemEx is moving into your agent’s hands. We're rolling it out across Databricks' first-party agents and Agent Bricks: if you build on Databricks agents today, you'll soon be able to use MemEx.
We're post-training our models for the MemEx action space. MemEx itself is the substrate: it generates synthetic data, runs agentic verifiers, and feeds the training loop.
Authors: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 In MemEx, tool calls are python code blocks which can have data analysis or other tools called as async functions.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.