The best data warehouse is a lakehouse
Unify your data and analytics on an open warehouse foundation that lowers costs at scale.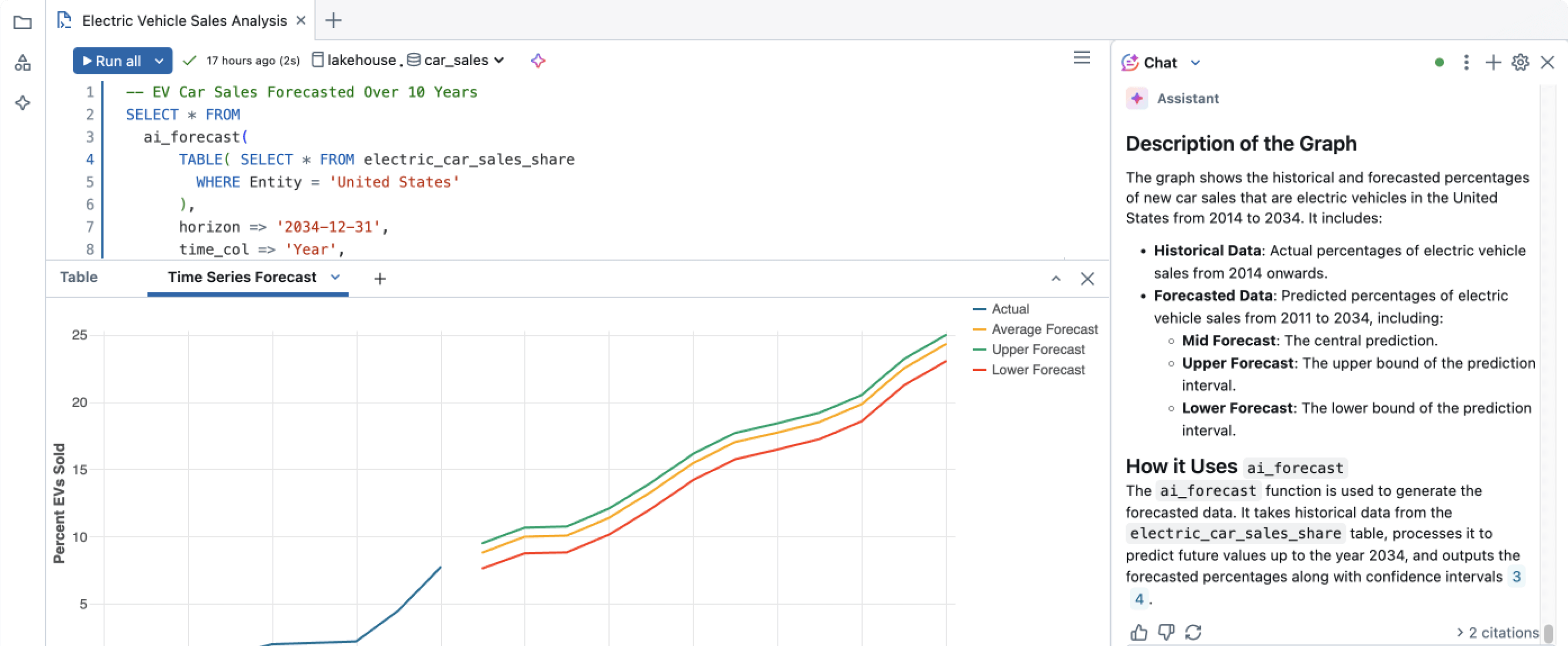
TOP TEAMS SUCCEED WITH LAKEHOUSEAI-powered performance and simplicity
Eliminate the cost and complexity of legacy data warehouses with an open, serverless lakehouse that unifies your data and natively integrates AI.Intelligent experiences
Let everyone in your organization self-serve data-driven answers using natural language queries, thanks to AI-powered experiences that understand the unique semantics of your data and your business. Data architects can also write SQL in the SQL editor, which uses AI to generate and fix SQL code.
Predictive optimizations
Deliver high performance, efficiency and resiliency automatically, so you can eliminate the overhead of manually tuning your data warehouse. Reduce operating costs with Lakehouse through time savings and more efficient provisioning.
World-class price/performance
Improve TCO for your BI and ETL workloads. Save on compute and storage costs with a lakehouse architecture powered by the Photon query engine. These capabilities help you easily predict growth requirements and maintain sustainable budget growth.
AI-powered lakehouse
Less tuning your data warehouses, more answers from your data. All with market-leading price/performance.Democratize analytics and insights across your organization. Accurately answer your data questions, because AI/BI understands your data and continuously improves.
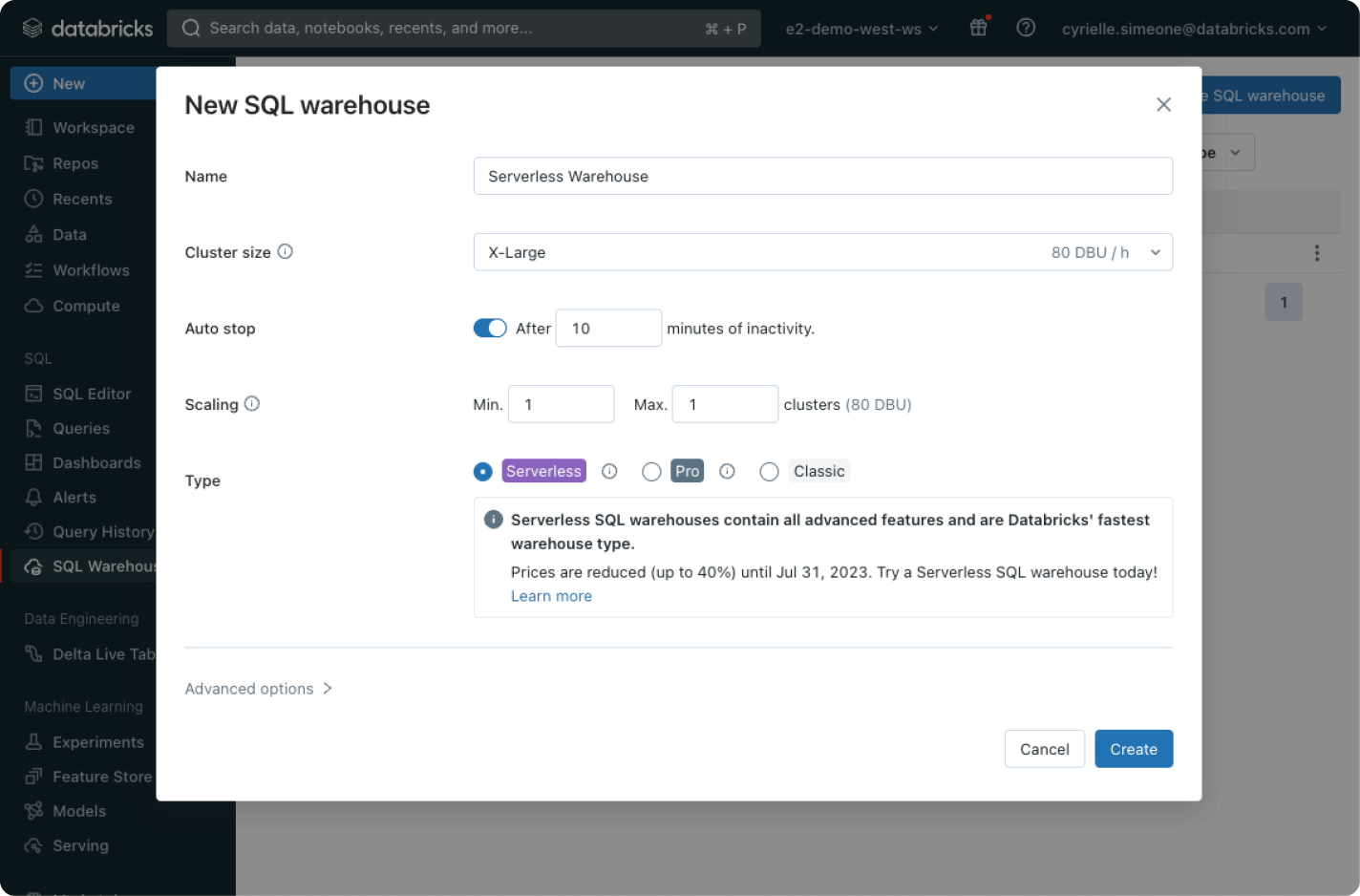
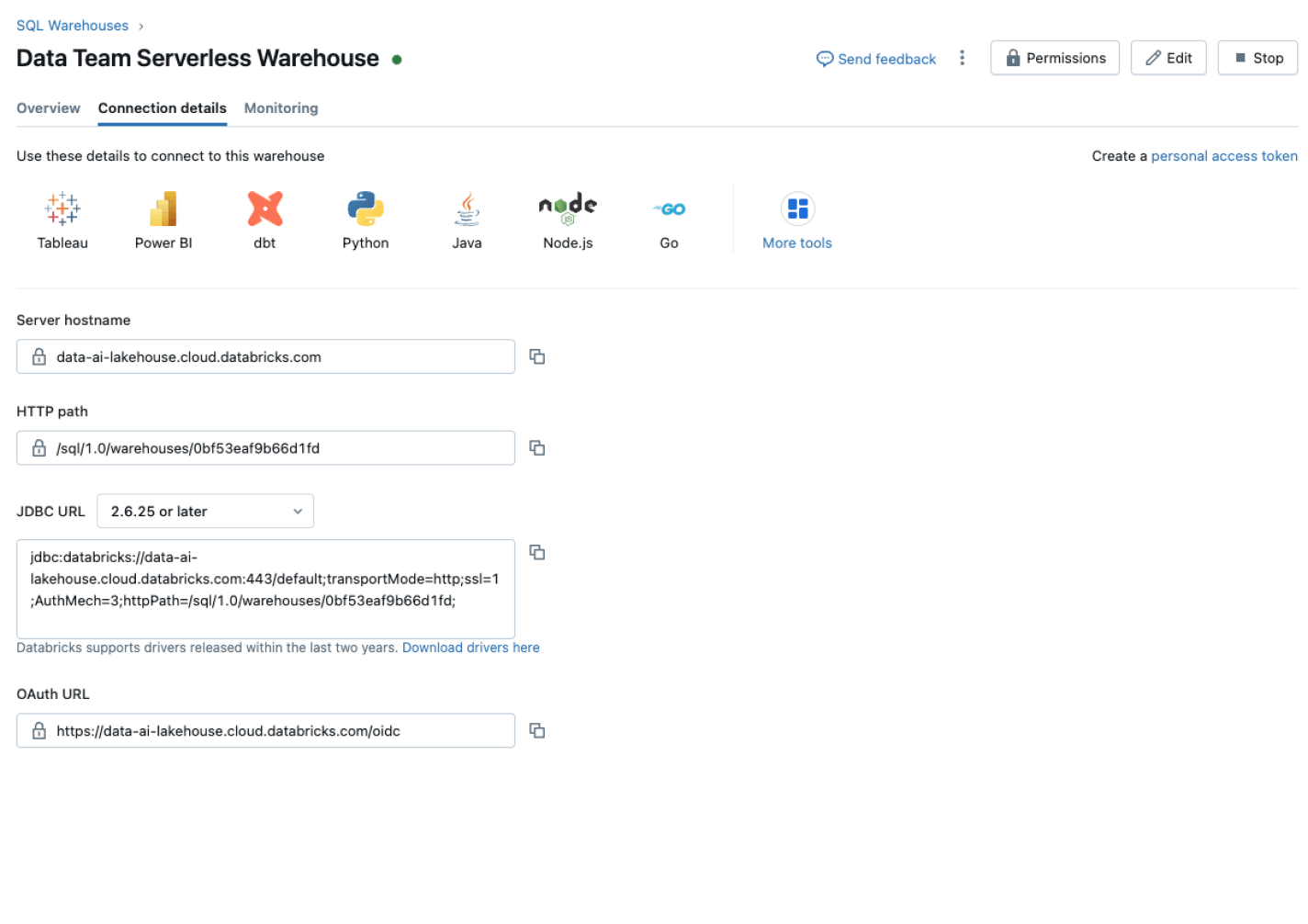
Get the best price/performance with instant and elastic compute, lower cost and completely managed infrastructure.
Unify your analytics data with open table formats so your data stays portable, with no vendor lock-in.

Easily connect BI tools (Power BI, Tableau and more) to Lakehouse for fast performance on fresh data.
Unified governance and security to centrally manage your assets and access with integrated Unity Catalog.

Discover, query and govern all your data in one place. Use federation to expose, query and govern siloed data systems as an extension of your lakehouse.
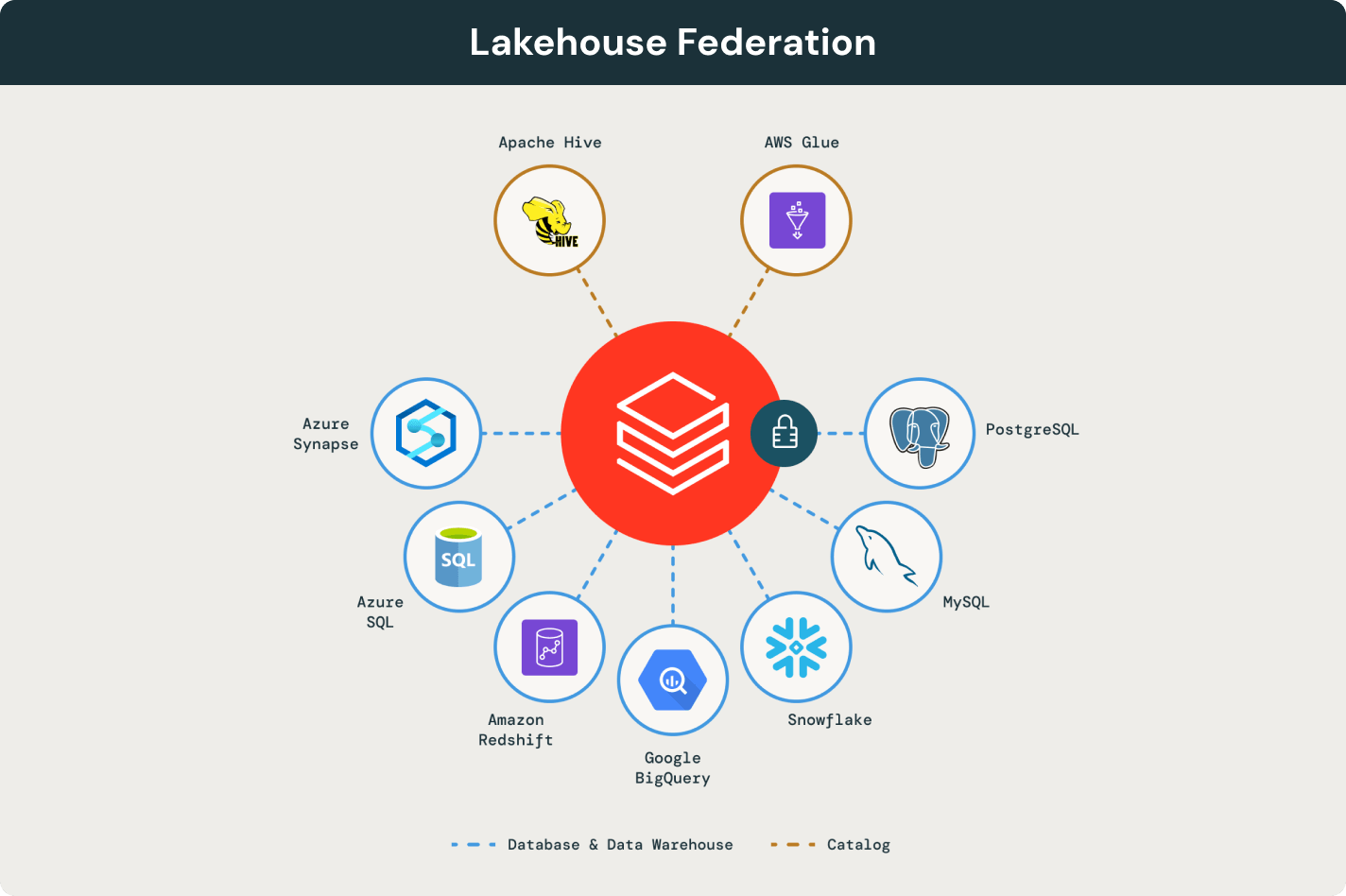
More features
An open, unified approach to your data, BI and AI workloads

Empower anyone to extract insights with SQL queries
Empower data analysts and business users to answer questions independently while freeing up data professionals for more complex tasks
- AI-powered dashboards
- Conversational interfaces to chat with your data
- An evolving system that gets smarter every time you use it
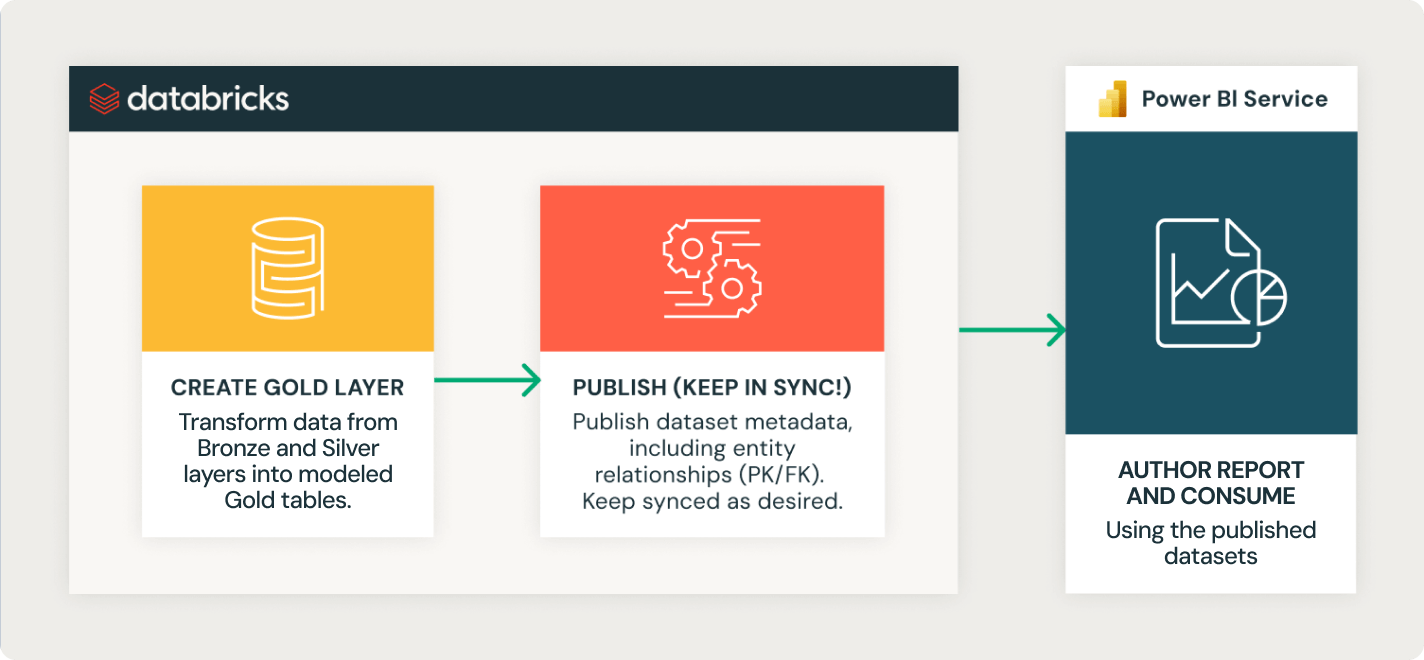
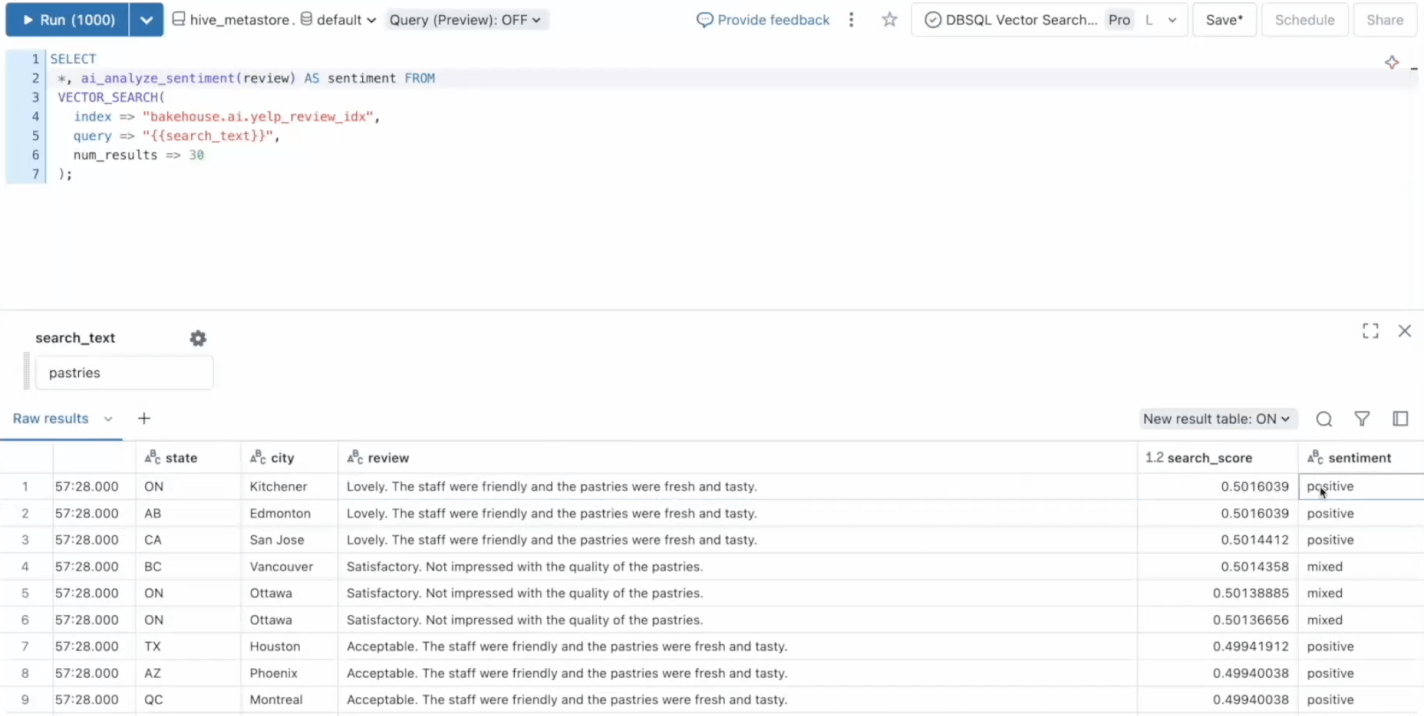
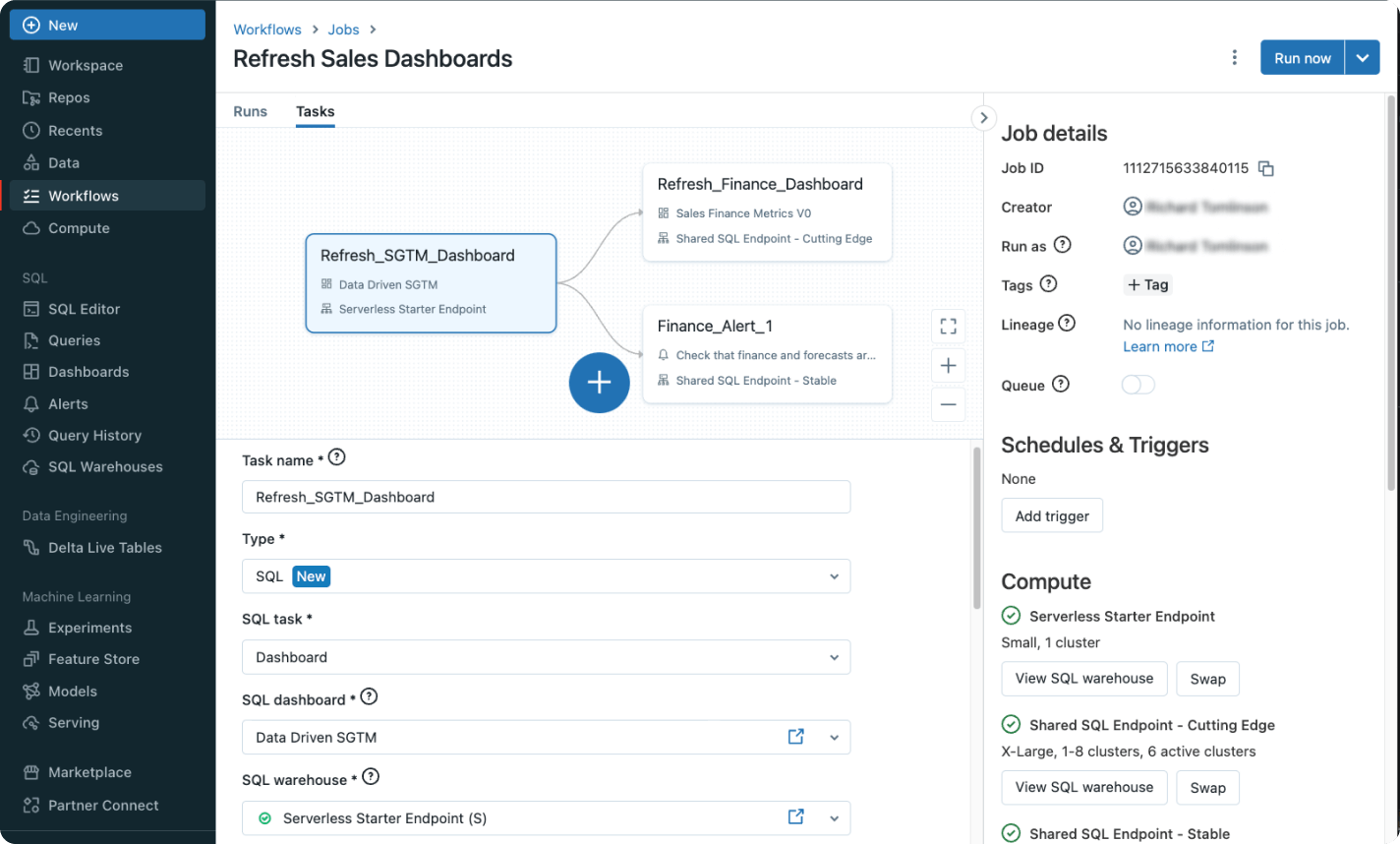
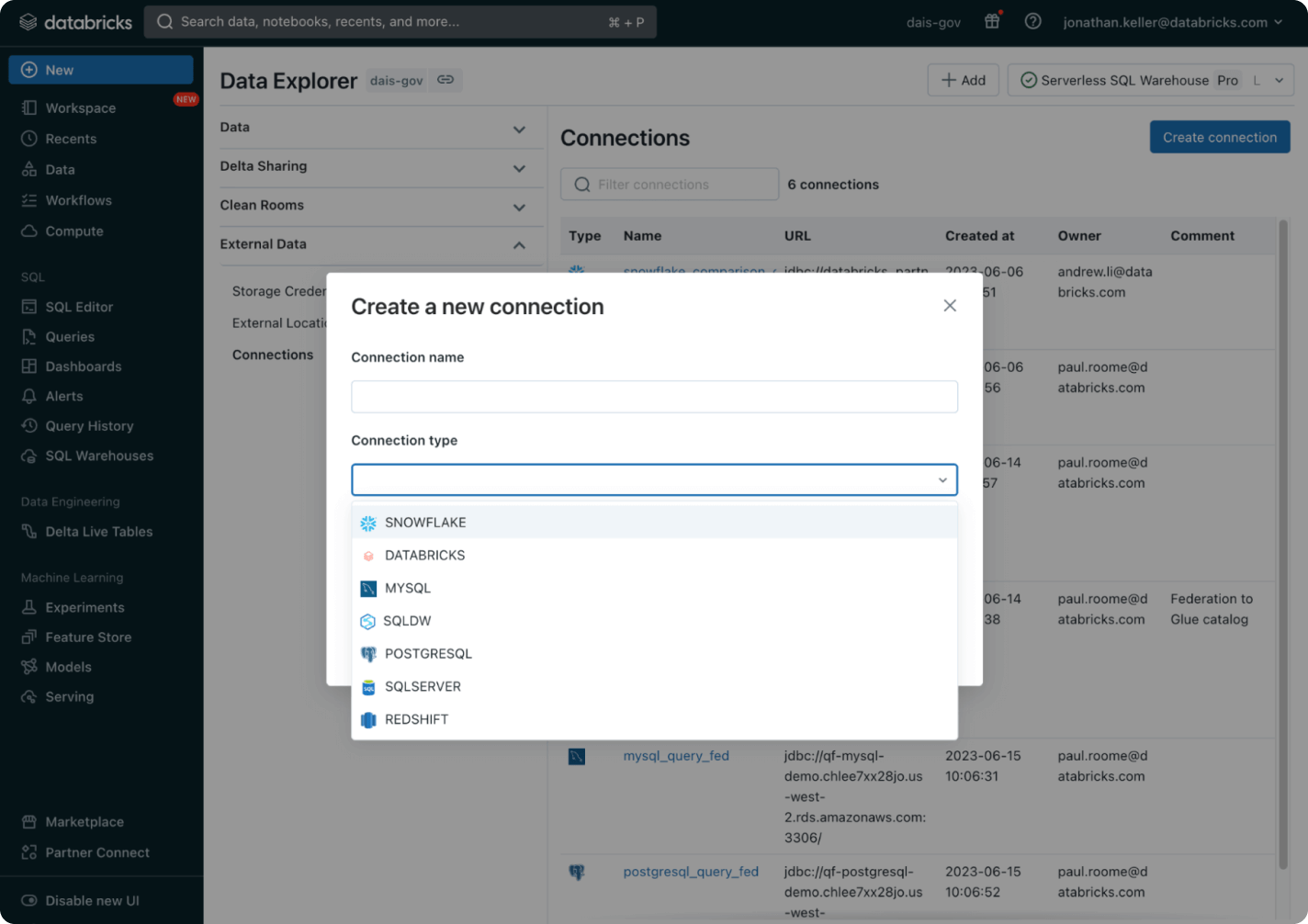

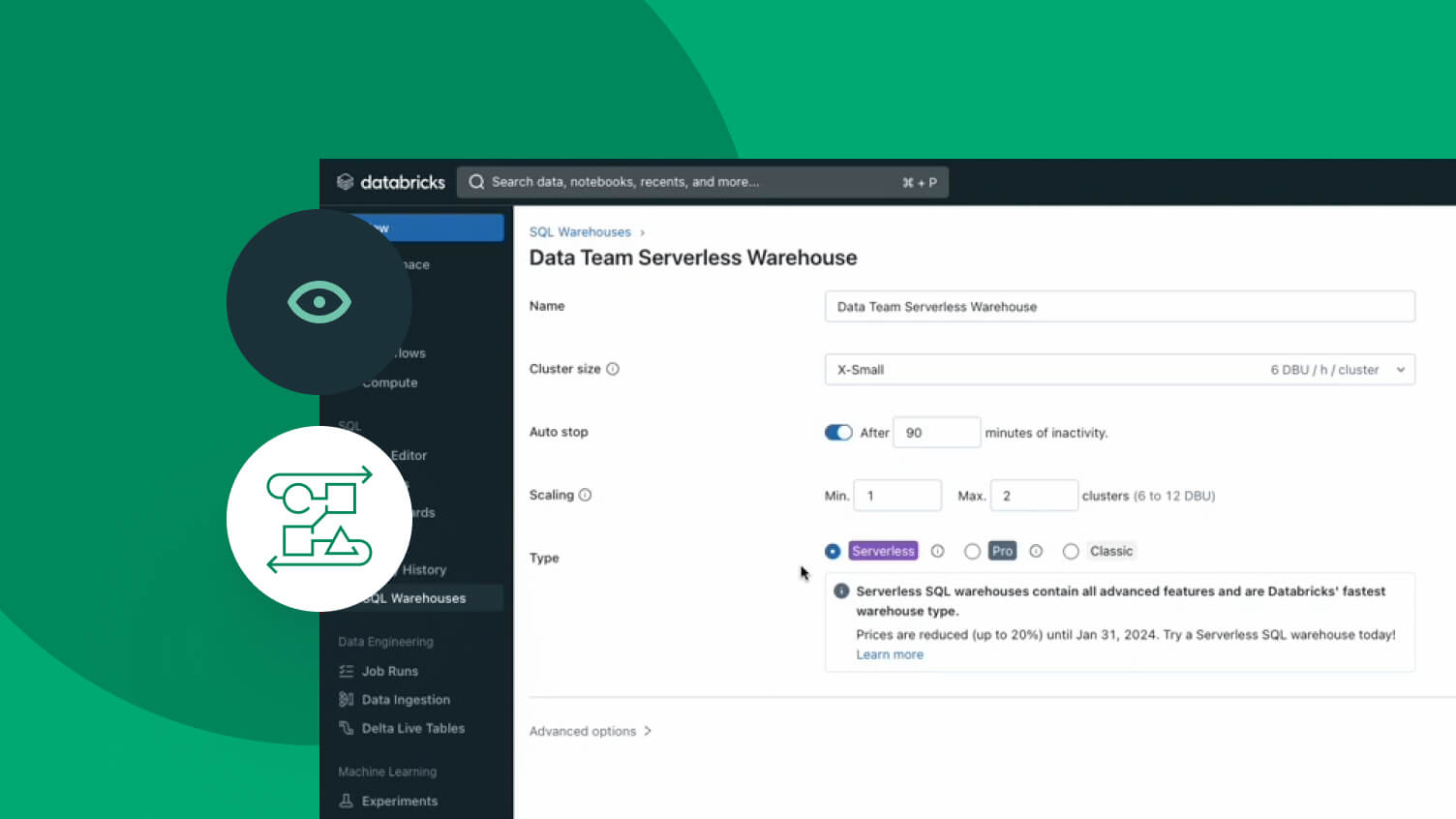
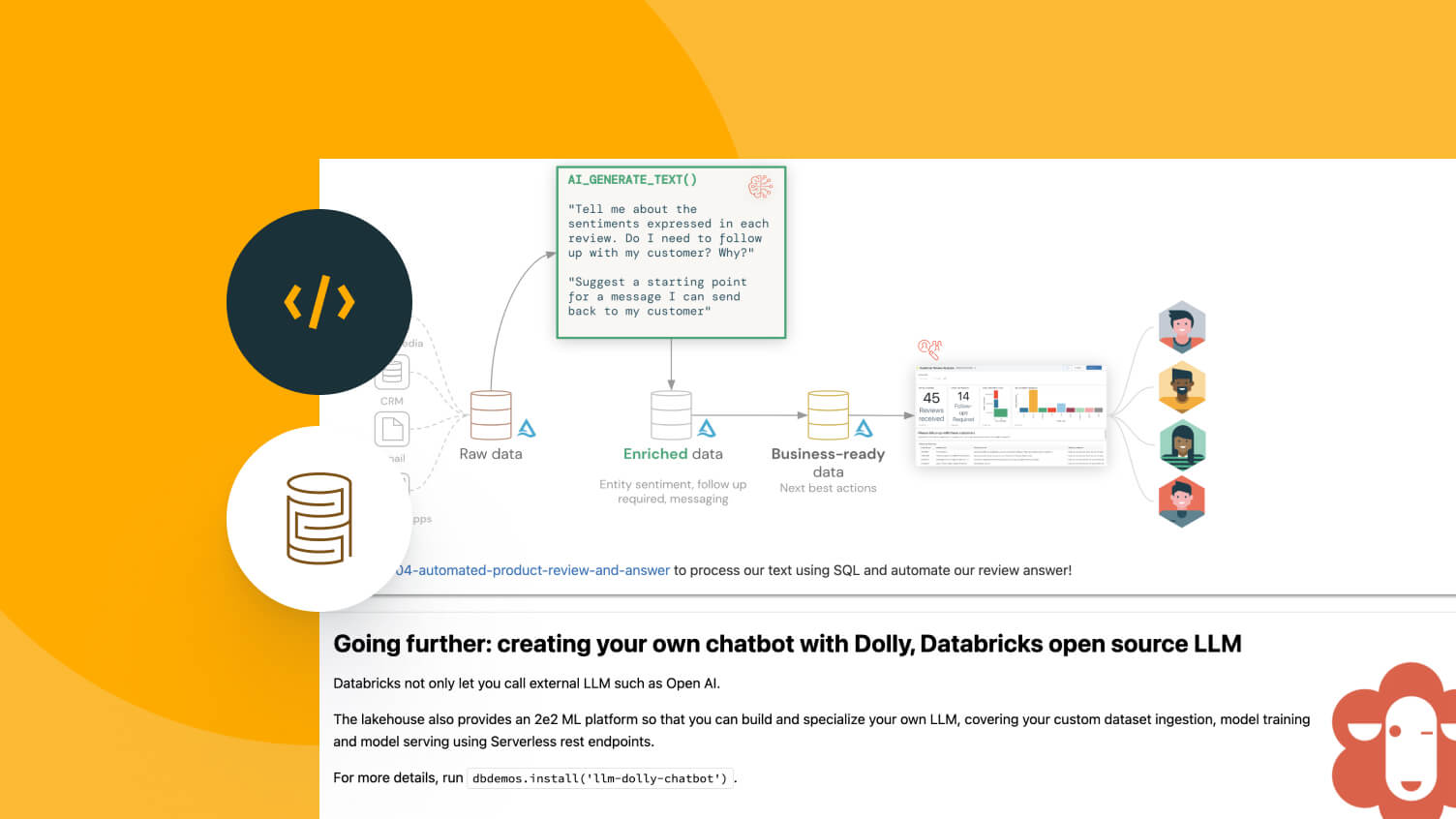
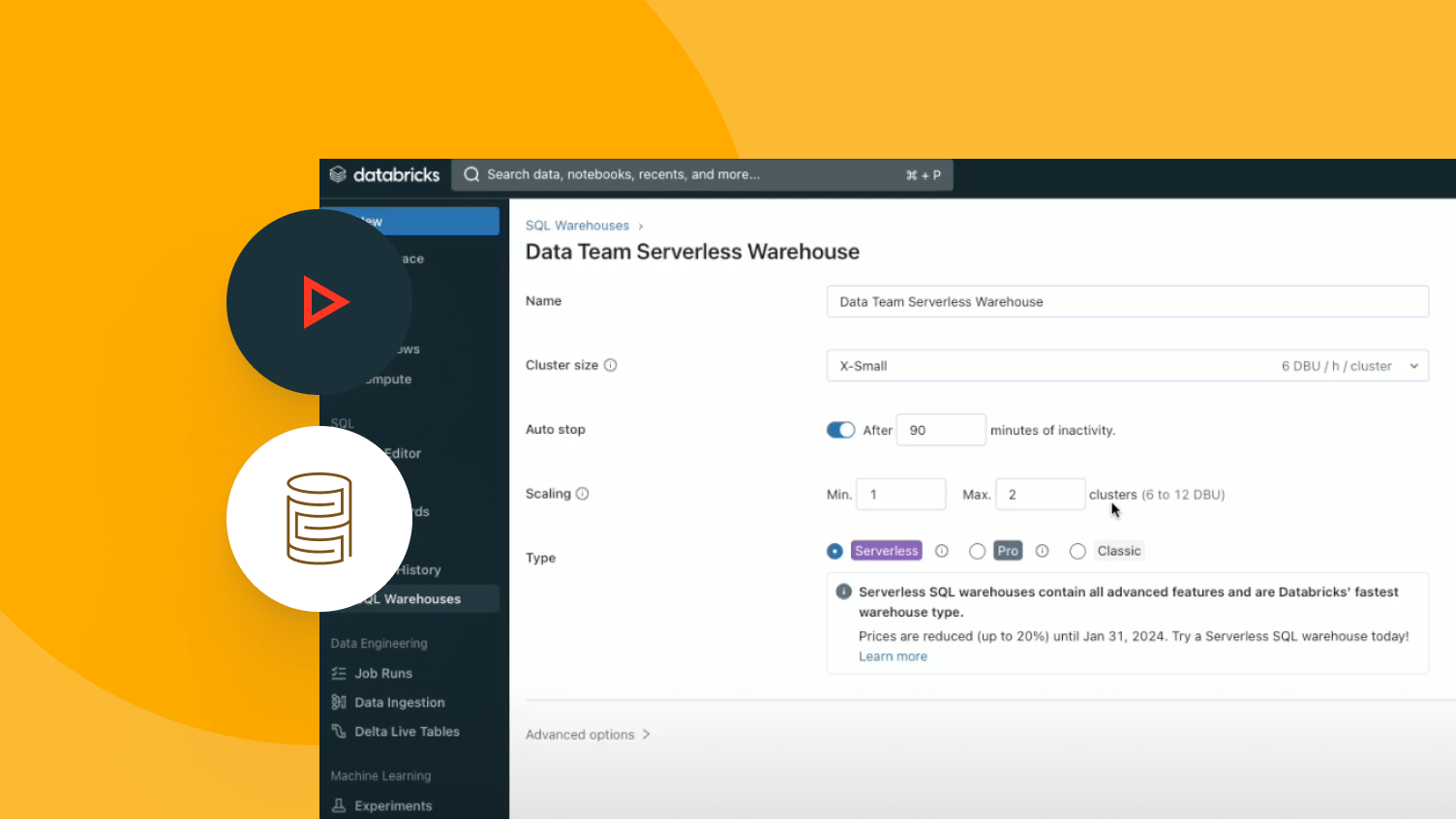


AI-optimized performance
Lakehouse uses AI systems throughout the Databricks Platform that analyze your workloads and automatically improve efficiency and performance. Customer queries are already 5x faster than three years ago.
- 9x better ETL price/performance
- The Photon query engine for extremely fast query performance at low cost
- Process large numbers of queries quickly and cost-effectively with intelligent workload management
- Automatically rewrite data files to improve data layout
- Maintain both high performance and high BI query concurrency
- 4x improvement on throughput using ai_query()
Usage-based pricing keeps
spending in check
Only pay for the products you use at per-second granularity.Discover more
Learn more about the integrated features of Lakehouse.
Unity Catalog
Unified governance and security to centrally manage assets and access with integrated Unity Catalog.
AI/BI
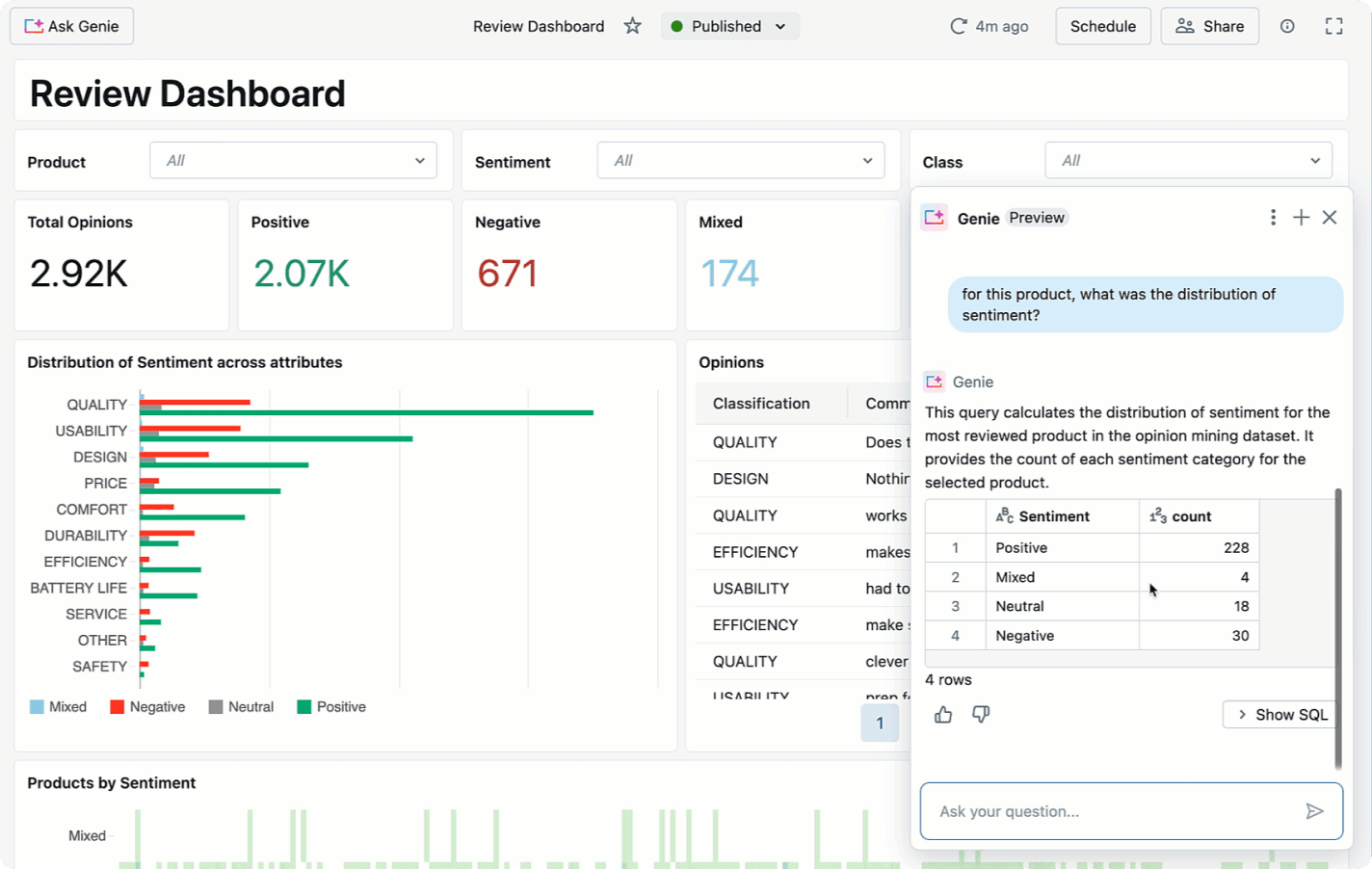
Dashboards provide a low-code experience for analysts. Genie helps business users ask questions of their data and self-serve their own analytics.
Lakehouse//RT
A real-time lakehouse that provides millisecond performance at massive scale, directly on your lake, for operational analytics and BI serving.
Lakeflow Jobs
Define, manage and monitor multitask workflows with Lakeflow Jobs, a managed orchestration service that’s fully integrated into Lakehouse.
Delta Sharing
The open source approach of Delta Sharing lets you share live data across platforms, clouds and regions without sacrificing strong security and governance.
The Databricks Platform
Explore the full range of tools available on the Databricks Platform to seamlessly integrate data and AI across your organization.
Take the next step
Explore Databricks Lakehouse and SQL documentation
Everything you need to get started using Lakehouse on AWS, Microsoft Azure or Google Cloud Platform.
Migrate your data warehouse to Databricks
Scale as your business requires and control costs with analytics and AI workloads on a single unified data platform.



Ready to become a data + AI company?
Take the first steps in your data transformation