How Retina Uses Databricks Container Services to Improve Efficiency and Reduce Costs
by Brad Ito and Vini Jaiswal
This is a guest community post authored by Brad Ito, CTO Retina.ai, with contributions by Databricks Customer Success Engineer Vini Jaiswal
Retina is the customer intelligence partner that empowers businesses to maximize customer-level profitability. We help our clients boost revenue with the most accurate lifetime value metrics. Our forward-looking, proprietary models predict customer lifetime value at or before the first transaction.
To build and deliver these models, Retina data scientists and engineers use Databricks. We recently started to use Databricks Container Services to reduce costs and increase efficiency. Docker containers give us 3x faster cluster spin-ups and unify our dependency management. In this post, we'll share our process and some public docker images we've made so that you can do this too.
Context: Docker
We use Docker to manage our local data science environments and control dependencies at the binary level, for truly reproducible data science. At Retina, we use both R and Python, along with an ever-evolving mix of public and proprietary packages. While we use several tools to lock down our dependencies, including MRAN snapshots for R, conda for Python packages with clean dependencies, and pip-tools for Python packages with less-clean dependencies, we find that everything works most reliably when packaged in Docker containers.
Speaking of Docker containers, most tutorials lead users down the wrong path. Those tutorials usually start from a public official image, then add in dependencies and install the application to be executed all in a single image. Instead, if you are trying to develop and deploy code (for interpreted languages), like Retina models, you need at least 3 images:
- Base image: We use a base image to lock down system and package dependencies and leverage whatever tools are available to try to make that reproducible.
- Development image: We use a development image that adds development tools and use that when writing new code by running that image linked to local source code.
- Optimized deployment image: And finally, when we want to run our code in other environments, we create an optimized deployment image that combines our code with the base image to create a fully executable container.
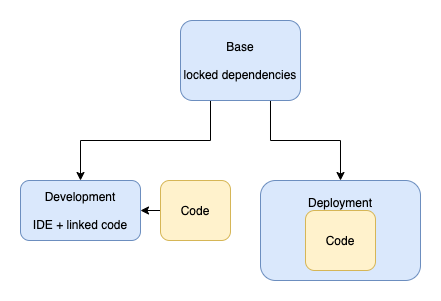
For Retina's specific use case, our base image starts with Ubuntu and adds in R and Python dependencies, including some of our own packages. We then have two development images. The first leverages code from the rocker project to install RStudio for doing data science in R. The second leverages code from Jupyter Docker Stacks to install Jupyter Lab for Python. When we run the development images, we use a bash script that injects any needed environment variables and mounts the local source code in a way that is accessible from the install IDE.
Context: Databricks
Retina has been using Databricks for several years to manage the client data for Machine Learning models. It allows R and Python to get the best of both worlds, while leveraging Spark for its big data capabilities. However, Retina requires several custom packages that require time-consuming compilation upon installation, meaning new clusters become slow to spin up.
This slow cluster spin-up has had a cascading effect on costs. For interactive clusters, Retina had to over-provision instances to avoid long delays while the cluster auto-scales. For non-interactive jobs, we've had to custom-tune dependencies and pay for the EC2 instances to repeatedly compile the same C code whenever we run jobs frequently.
While we were still able to run the various workloads we needed to run, we knew that we were being inefficient in compute costs and maintenance hours.
Context: Databricks Container Services
Databricks allows every Data persona to be on one Unified platform and build their applications on it. With this mission in mind, data engineers and developers can build complex applications using their own custom golden images. Databricks Container Services allows users to specify bespoke libraries or custom images that can be used in conjunction with Databricks Runtime to leverage the distributed processing of Apache Spark while leveraging the optimizations of Databricks Runtime. With this solution, data engineers and developers can build highly customized execution environments, tightly secure applications, and prepackage an environment that is repeatable and immediately available when a cluster is created.
The golden image addresses these use cases:
- Organizations can install required software agents on the VMs that are used by their spark applications.
- A deterministic environment in a container that a cluster is built from for production workloads.
- Data Scientists can use custom Machine Learning libraries provisioned by DCS enabled clusters for their model experiments or exploratory analysis.
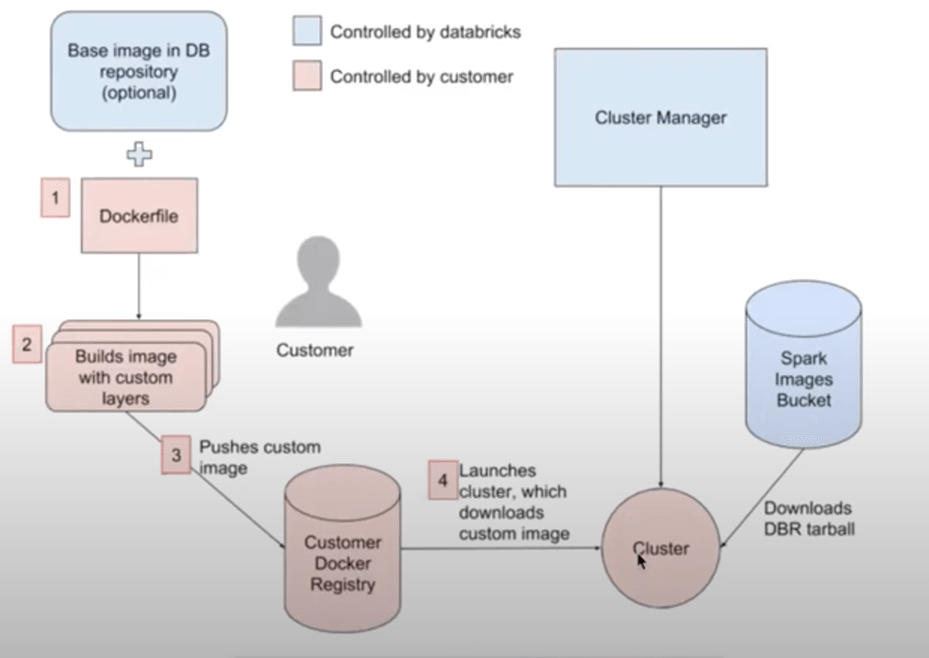
Figure. How does Docker Container Services work with Databricks
Solution to address Retina’s pain points
The Databricks Container Services feature lets you build custom Docker containers to create new clusters. Retina built a hierarchy of custom containers in-house to address many of the pain points above.
We do pre-compilation of packages in the container. Instead of recompiling the same code over and over, we just load a container and have our packages already pre-installed. The result is a 3x speedup in the startup times for new clusters.
We also install most of the packages we need in "standard" docker containers that run both R and Python and have most of the dependencies we use frequently. These are the same packages installed in our local development containers, so we get a common reproducible environment for running code. For special cases, we have the ability to create new containers that are optimized for those additional containers.
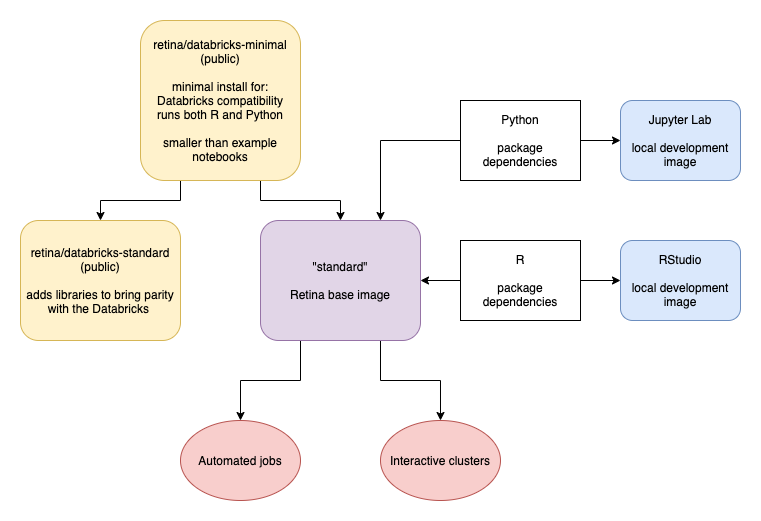
The above diagram shows our container hierarchy.
We made our own minimal image retina/databricks-minimal that builds in the base requirements to run the Databricks Runtime 6.x, along with Scala, Python and R support in notebooks. It also incorporates some Docker optimizations to reduce the number of layers and the overall image size.
From there, we make our own "standard" image which adds in various packages, both public and private, which we use in both our automated databricks jobs and interactive clusters. To show how some of this works, we made a public retina/databricks-standard image which has the same package dependencies as the 6.x Databricks runtime.
Wrapping Up
By leveraging containers, and the Databricks integration, Retina achieved significant savings in both cost and time. For Retina, this means faster spin-up times for more efficient usage of cloud resources, and better leveraging of the auto-scaling. It also means a seamless experience for our data scientists as they can focus on building models and not on troubleshooting dependencies.
You can build your Docker base from scratch. Your Docker image must meet these requirements:
- JDK 8u191 as Java on the system PATH
- bash
- iproute2 (ubuntu iproute)
- coreutils (ubuntu coreutils, alpine coreutils)
- procps (ubuntu procps, alpine procps)
- sudo (ubuntu sudo, alpine sudo)
- Ubuntu or Alpine Linux
Or, you can use the minimal image built by Databricks at https://github.com/databricks/containers
A step by step guide is available for you to get started with Databricks container services.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.