Databricks Connect: Bringing the capabilities of hosted Apache Spark™ to applications and microservices
by Eric Liang
In this blog post we introduce Databricks Connect, a new library that allows you to leverage native Apache Spark APIs from any Notebook, IDE, or custom application.
Overview
Over the last several years, many custom application connectors have been written for Apache Spark. This includes tools like spark-submit, REST job servers, notebook gateways, and so on. These tools are subject to many limitations, including:
- They're not one-size-fits-all: many only work with specific IDEs or notebooks.
- They may require your application to run hosted inside the Spark cluster.
- You have to integrate with another set of programming interfaces on top of Spark.
- Library dependencies cannot be changed without restarting the cluster.
Compare this to how you would connect to a SQL database service, which just involves importing a library and connecting to a server:
The equivalent for Spark's structured data APIs would be the following:
However, prior to Databricks Connect, this above snippet would only work with single-machine Spark clusters -- preventing you from easily scaling to multiple machines or to the cloud without extra tools such as spark-submit.
Databricks Connect Client
Databricks Connect completes the Spark connector story by providing a universal Spark client library. This enables you to run Spark jobs from notebook apps (e.g., Jupyter, Zeppelin, CoLab), IDEs (e.g., Eclipse, PyCharm, Intellij, RStudio), and custom Python / Java applications.
What this means is that anywhere you can "import pyspark" or "import org.apache.spark", you can now seamlessly run large-scale jobs against Databricks clusters. As an example, we show a CoLab notebook executing Spark jobs remotely using Databricks Connect. It is important to notice that there is no application-specific integration here---we just installed the databricks-connect library and imported it. We're also reading an S3 dataset from GCP, which is possible since the Spark cluster itself is hosted in an AWS region:
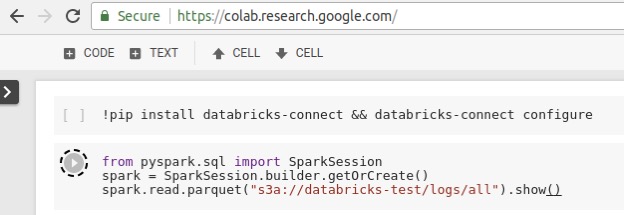
Jobs launched from Databricks Connect run remotely on Databricks clusters to leverage their distributed compute, and can be monitored using the Databricks Spark UI:

Customer Use Cases
More than one hundred customers are actively using Databricks Connect today. Some of the notable use cases include:
Development & CI/CD:
- Debugging code using local IDEs while interacting with Databricks hosted clusters
- Testing Spark applications in CI/CD pipelines against production environments
Interactive analytics:
- Many users use Databricks Connect so they can use their preferred shell (e.g., Jupyter, bash) or studio environment (e.g., RStudio) for issuing interactive queries against Databricks clusters
Application development:
- A large customer in the health-care field has used Databricks Connect to deploy a Python-based microservice that serves interactive user queries. The query service uses the Databricks Connect library to run Spark jobs remotely against several Databricks clusters, serving thousands of queries a day.
How Databricks Connect works
To build a universal client library, we had to satisfy the following requirements:
- From the application point of view, the client library should behave exactly like full Spark (i.e., you can use SQL, DataFrames, and so on).
- Heavyweight operations such as physical planning and execution must run on the servers in the cloud. Otherwise, the client could incur a lot of overhead reading data over the wide area network if it isn't running co-located with the cluster.
To meet these requirements, when the application uses Spark APIs, the Databricks Connect library runs the planning of the job all the way up to the analysis phase. This enables the Databricks Connect library to behave identically to Spark (requirement 1). When the job is ready to be executed, Databricks Connect sends the logical query plan over to the server, where actual physical execution and IO occurs (requirement 2):
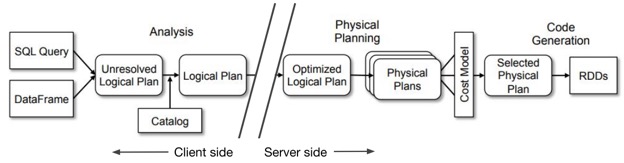
Figure 1. Databricks Connect divides the lifetime of Spark jobs into a client phase, which includes up to logical analysis, and server phase, which performs execution on the remote cluster.
The Databricks Connect client is designed to work well across a variety of use cases. It communicates to the server over REST, making authentication and authorization straightforward through platform API tokens. Sessions are isolated between multiple users for secure, high concurrency sharing of clusters. Results are streamed back in an efficient binary format to enable high-performance. The protocol used is stateless, which means that you can easily build fault-tolerant applications and won't lose work even if the clusters are restarted.
Availability
Databricks Connect enters general availability starting with the DBR 5.4 release, and has support for Python, Scala, Java, and R workloads. You can get it from PyPI for all languages with "pip install databricks-connect", and documentation is available here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.