How Databricks and Privacera Combine to Secure Data for Cloud Analytics
by Hiral Jasani
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
In their quest to anticipate customer needs, forward looking organizations are looking to use cloud-based analytics and AI to innovate. But we often hear from customers how challenging it is to manipulate large data volumes in a secure and compliant way. Databricks and Privacera have partnered to help customers address several key use cases for cloud-based analytics with a fine-grained access control and data classification solution.
For customers using Apache Ranger, this is especially an easy transition. The Privacera platform is based on and developed by the original team behind Apache Ranger that provides centralized policy management and dynamic data masking.
The Databricks and Privacera Joint Solution Addresses the Following Data Security Key Use Cases.
1. Create a Sensitive Data Catalog to Comply with GDPR, CCPA
The Databricks and Privacera joint solution enables automatic scanning of incoming data into Databricks to identify and profile sensitive data. By tagging this data into a scalable metadata store, it builds a centralized data catalog of sensitive data including PII information.
Thus, enterprises can comply with regulations such as General Data Protection Regulation
(GDPR) and California Consumer Privacy Act (CCPA) while maintaining data privacy.
2. Ensure Centralized Data Governance for Analytics and AI/ML
The partnership enables organizations to create fine-grained access control policies on row, column and fine-level natively on Delta Lake tables. Role-based, fine-grained access allows centralized governance so that users that have access can use more data for analytics and ML instead of being denied entire table level access.
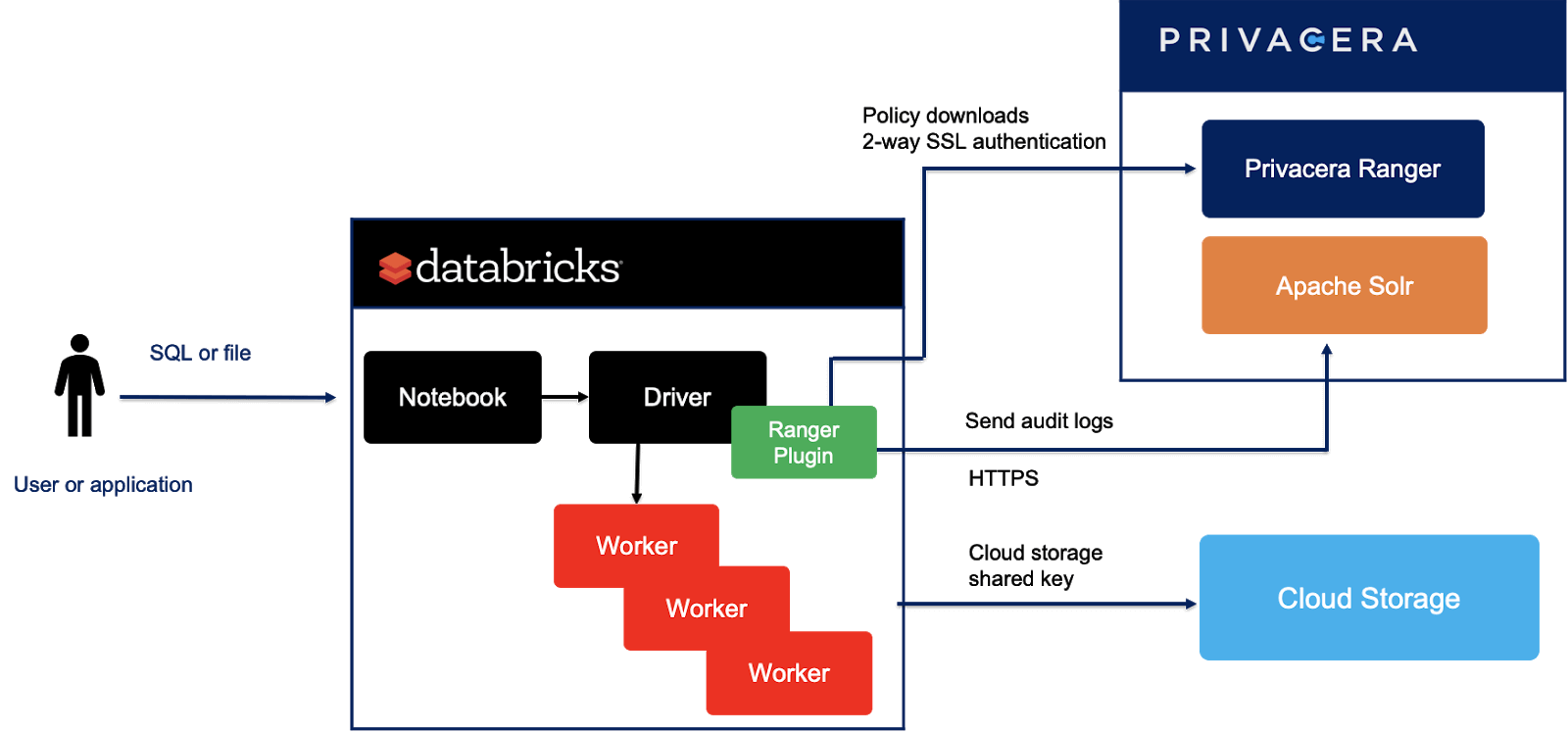
The integration also features a Privacera plugin natively inside Databricks to provide authorization for Spark SQL in Databricks. This ensures continuous flow of data for users with access permissions when they run queries in their Databricks environment.
3. Make More Data Available without Compromising Data Privacy
The joint solution also provides de-identification to anonymize sensitive data in Databricks so that data engineering teams can make sensitive data available to data scientists and analysts. This allows them to preserve data privacy while maintaining the data’s referential integrity and analytical value. Data scientists and analysts can anonymize or mask data in Databricks for analytics and ML/AI workloads while maintaining enterprise-wide control to analyze their complete data sets for analytics and AI/ML workloads.
Available Today
The integration is available today. To learn more, check out this detailed blog co-authored by Databricks and Privacera.
More Resources
https://www.databricks.com/product/databricks-enterprise-security-culture
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.