Extending Delta Sharing for Azure
Delta Sharing 0.3.0 includes Azure support, token expiration time, query limit parameters, and improve APIs
by Will Girten, Shixiong Zhu and Denny Lee
We are excited for the release of Delta Sharing 0.3.0, which introduces several key improvements and bug fixes, including the following features:
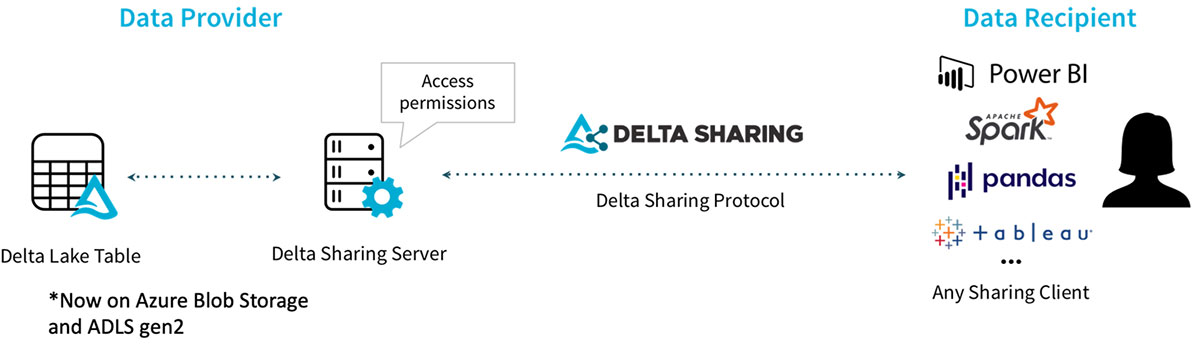
- Delta Sharing is now available for Azure Blob Storage and Azure Data Lake Gen2: You can now share Delta Tables on Azure Blob Storage and Azure Data Lake Gen2 (#56, #59).
- Token expiration time: An optional expirationTime field has been added to the Delta Sharing profile to specify a token expiration time (#77).
- Query limit parameters: The Python Connector now accepts an optional limit parameter to allow fetching a subset of rows when using the load_as_pandas function (#76). Similarly, users can also send a limitHint parameter when submitting a sharing query using the Apache Spark™ Connector (#55).
- Improved API to list all tables in a share: A new API has been added for listing all tables in a share that supports pagination (#63, #66, #67, #88).
- Automatic Refresh of Pre-signed URLs: A new cache has been added to the Apache Spark driver that automatically refreshes pre-signed file URLs for long-running queries (#69).
In this blog post, we will go through some of the great improvements in this release.
Delta Sharing on Azure Blob Storage and Azure Data Lake Gen2
Azure Blob Storage has proven to be a cost-effective solution for storing Delta Tables in the Azure cloud. New to this release, you can now share Delta Tables stored on Azure Blob Storage and Azure Data Lake Gen2 in the reference implementation of Delta Sharing Server.
Delta Sharing on Azure Blob Storage example
Sharing Delta Tables on Azure Blob Storage is easier than ever! For example, to share a Delta Table called classics in an Azure Blob container called movie_recommendations, you can simply update the Delta Sharing profile with the location of the Delta table on Azure Blob Storage:
delta-sharing-profile.yaml
Delta Sharing on Azure Data Lake Storage Gen2 example
For those who would prefer to leverage the built-in hierarchical directory structure and fine-grained access controls, you can share Delta Tables on Azure Data Lake Storage Gen2 as well. Simply update the Delta Sharing profile with the location on Azure Data Lake Storage Gen2 of your Delta Table, and the Delta Sharing server will automatically process the data for a Delta Sharing query:
delta-sharing-profile.yaml
Query limit parameters
Sometimes it might be helpful to explore just a few records in a shared dataset. Rather than loading the entire dataset into memory from blob storage, you can now add a limit hint in your Delta Sharing queries. The query limit will be pushed down and sent to the Delta Sharing server as a limit hint.
For example, to load a shared Delta Table as a Pandas DataFrame and limit the number of rows to 100, you can now add the limit as a parameter to the load_as_pandas() function call:
Similarly, if the Apache Spark Connector finds a LIMIT clause in your Spark SQL query, it will try to push down the limit to the server to request less data:
Improved API for listing all tables
Included in this release is a new and improved API for listing all the tables under all schemas in a share. The new API supports pagination similar to other APIs.
For example, to list all the tables in the Delta share my_share, you can simply send a GET request to the /shares/{share_name}/all-tables endpoint on the sharing server.
Automatic refresh of pre-signed URLs
When reading a Delta Sharing table, the Delta Sharing server automatically generates the pre-signed file URLs for a Delta Table. However, for long-running queries, the pre-signed file URLs may expire before the sharing client has a chance to read the files. This release adds a pre-signed URL cache in the Spark driver, which automatically refreshes pre-signed file URLs inside of a background thread. Tasks running in Spark executors communicate to the Spark driver to fetch the latest pre-signed file URLs.
What’s next
We are already gearing up for our next release of Delta Sharing. One of the major features we are currently working on is Google Cloud Storage support. You can track all the upcoming releases and planned features in github milestones.
Credits
We’d like to extend a special thanks for the contributions to this release to Denny Lee, Felix Cheung, Lin Zhou, Matei Zaharia, Shixiong Zhu, Will Girten, Xiaotong Sun, Yuhong Chen, kohei-tosshy, and William Chau.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.