Announcing Gated Public Preview of Unity Catalog on AWS and Azure
Unified Governance for Lakehouse

Update: Unity Catalog is now generally available on AWS and Azure.
At the Data and AI Summit 2021, we announced Unity Catalog, a unified governance solution for data and AI, natively built-into the Databricks Lakehouse Platform. Today, we are excited to announce the gated public preview of Unity Catalog for AWS and Azure.
Why Unity Catalog for data and AI governance?
Key challenges with data and AI governance
Diversity of data and AI assets
The increased use of data and the added complexity of the data landscape has left organizations with a difficult time managing and governing all types of data-related assets. Not just files or tables, modern data assets today take many forms, including dashboards, machine learning models, and unstructured data like video and images that legacy data governance solutions simply weren't built to govern and manage.
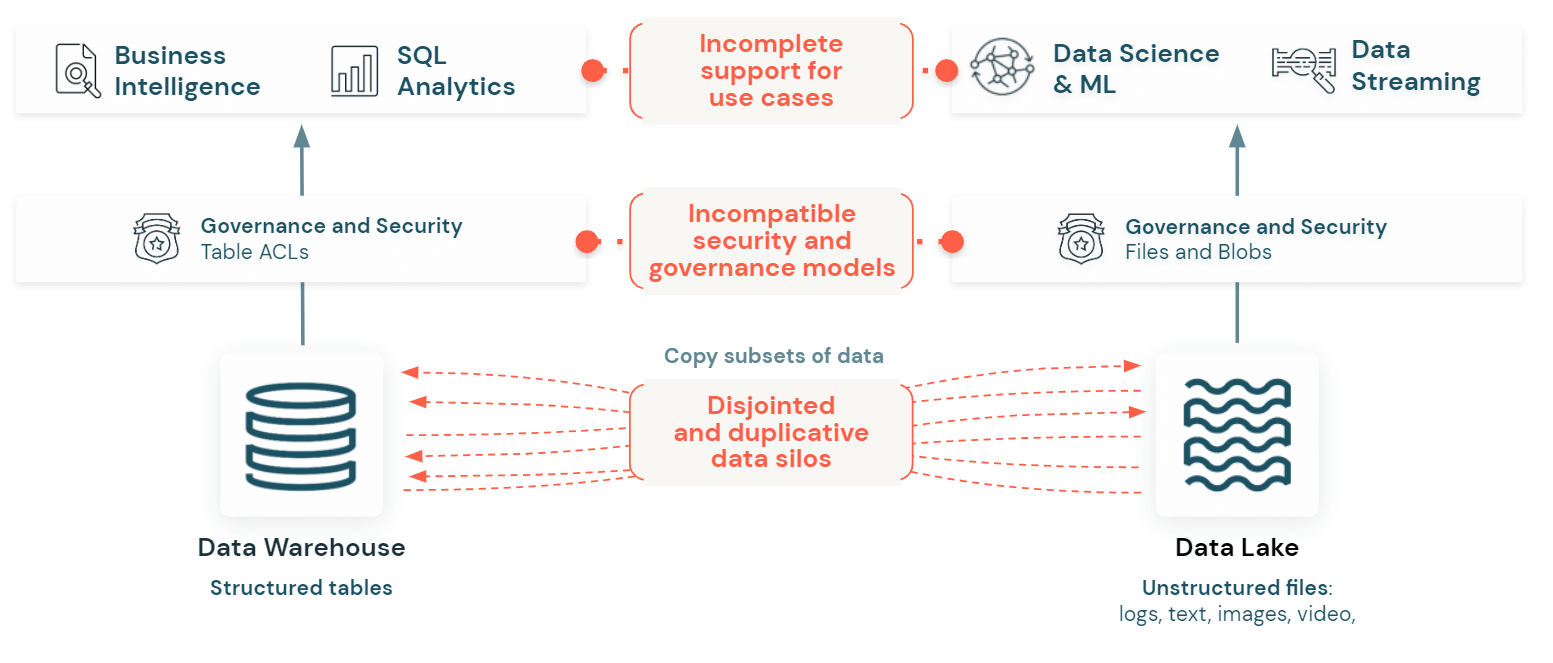
Two disparate and incompatible data platforms
Organizations today use two different platforms for their data analytics and AI efforts - data warehouses for BI and data lakes for big data and AI. This results in data replication across two platforms, presenting a major governance challenge as it becomes difficult to create a unified view of the data landscape to see where data is stored, who has access to what data, and consistently define and enforce data access policies across the two platforms with different governance models.
Data warehouses offer fine-grained access controls on tables, rows, columns, and views on structured data; but they don't provide agility and flexibility required for ML/AI or data streaming use cases. In contrast, data lakes hold raw data in its native format, providing data teams the flexibility to perform ML/AI. However, existing data lake governance solutions don't offer fine-grained access controls, supporting only permissions for files and directories. Data lake governance also lacks the ability to discover and share data - making it difficult to discover data for analytics or machine-learning.
Rising multi-cloud adoption
More and more organizations are now leveraging a multi-cloud strategy for optimizing cost, avoiding vendor lock-in, and meeting compliance and privacy regulations. With nonstandard cloud-specific governance models, data governance across clouds is complex and requires familiarity with cloud-specific security and governance concepts such as Identity and Access Management (IAM).
Disjointed tools for data governance on the Lakehouse
Today, data teams have to manage a myriad of fragmented tools/services for their data governance requirements such as data discovery, cataloging, auditing, sharing, access controls etc. This inevitably leads to operational inefficiencies and poor performance due to multiple integration points and network latency between the services.
Our vision for a governed Lakehouse
Our vision behind Unity Catalog is to unify governance for all data and AI assets including dashboards, notebooks, and machine learning models in the lakehouse with a common governance model across clouds, providing much better native performance and security. With automated data lineage, Unity Catalog provides end-to-end visibility into how data flows in your organizations from source to consumption, enabling data teams to quickly identify and diagnose the impact of data changes across their data estate. Get detailed audit reports on how data is accessed and by whom for data compliance and security requirements. With rich data discovery,data teams can quickly discover and reference data for BI, analytics and ML workloads, accelerating time to value.
Unity Catalog also natively supports Delta Sharing, world's first open protocol for data sharing, enabling seamless data sharing across organizations, while preserving data security and privacy.
Finally, Unity Catalog also offers rich integrations across the modern data stack, providing the flexibility and interoperability to leverage tools of your choice for your data and AI governance needs.
Key features of Unity Catalog available with this release
Centralized Metadata Management and User Management
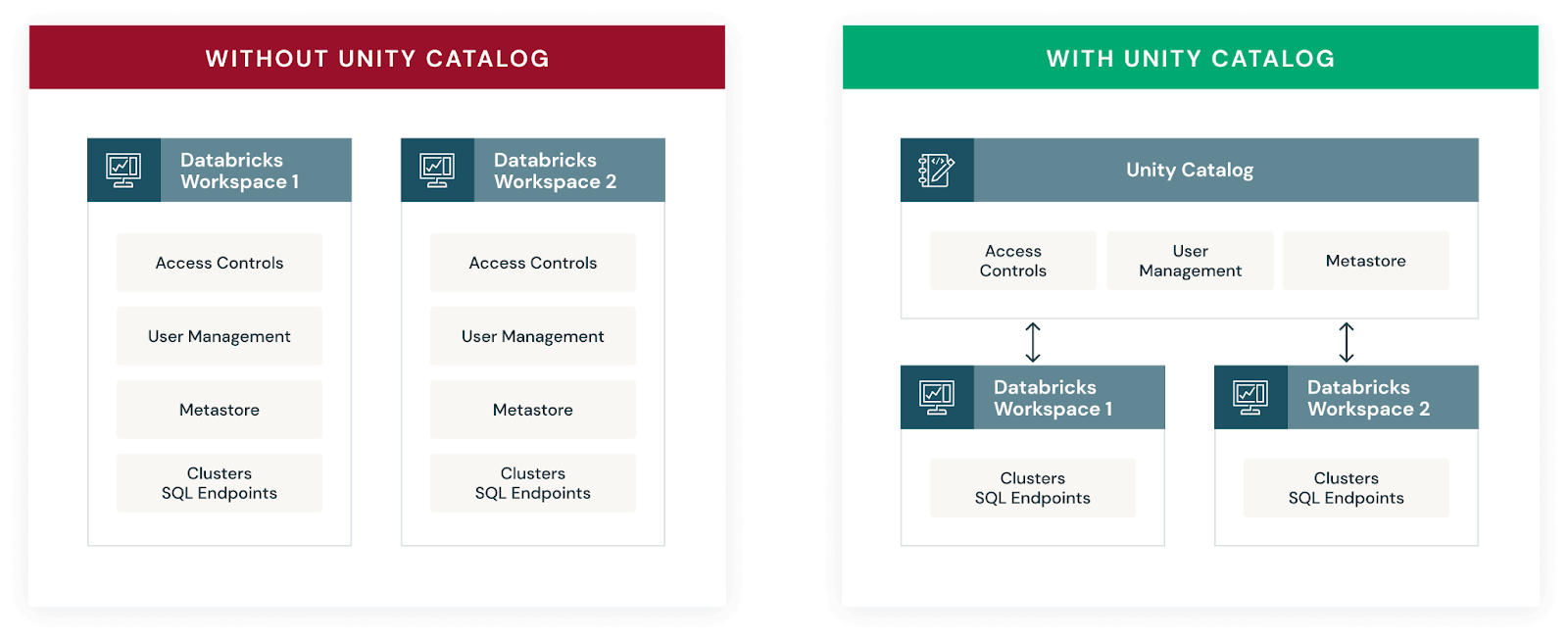
Without Unity Catalog, each Databricks workspace connects to a Hive metastore, and maintains a separate service for Table Access Controls (TACL). This requires metadata such as views, table definitions, and ACLs to be manually synchronized across workspaces, leading to issues with consistency on data and access controls.
Unity Catalog introduces a common layer for cross workspace metadata, stored at the account level in order to ease collaboration by allowing different workspaces to access Unity Catalog metadata through a common interface. Further, the data permissions in Unity Catalog are applied to account-level identities, rather than identities that are local to a workspace, enabling a consistent view of users and groups across all workspaces.
The Unity catalog also enables consistent data access and policy enforcement on workloads developed in any language - Python, SQL, R, and Scala.
Three-level namespace in SQL
Unity Catalog also introduces three-level namespaces to organize data in Databricks. You can define one or more catalogs, which contain schemas, which in turn contain tables and views. This gives data owners more flexibility to organize their data and lets them see their existing tables registered in Hive as one of the catalogs (hive_metastore), so they can use Unity Catalog alongside their existing data.
For example, you can still query your legacy Hive metastore directly:
You can also distinguish between production data at the catalog level and grant permissions accordingly:
Or
This gives you the flexibility to organize your data in the taxonomy you choose, across your entire enterprise and environment scopes. You can use a Catalog to be an environment scope, an organizational scope, or both.
Three-level namespaces are also now supported in the latest version of the Databricks JDBC Driver, which enables a wide range of BI and ETL tools to run on Databricks.
Unified Data Access on the Lakehouse
Unity Catalog offers a unified data access layer that provides Databricks users with a simple and streamlined way to define and connect to your data through managed tables, external tables or files, as well as to manage access controls over them. Using External locations and Storage Credentials, Unity Catalog can read and write data in your cloud tenant on behalf of your users.
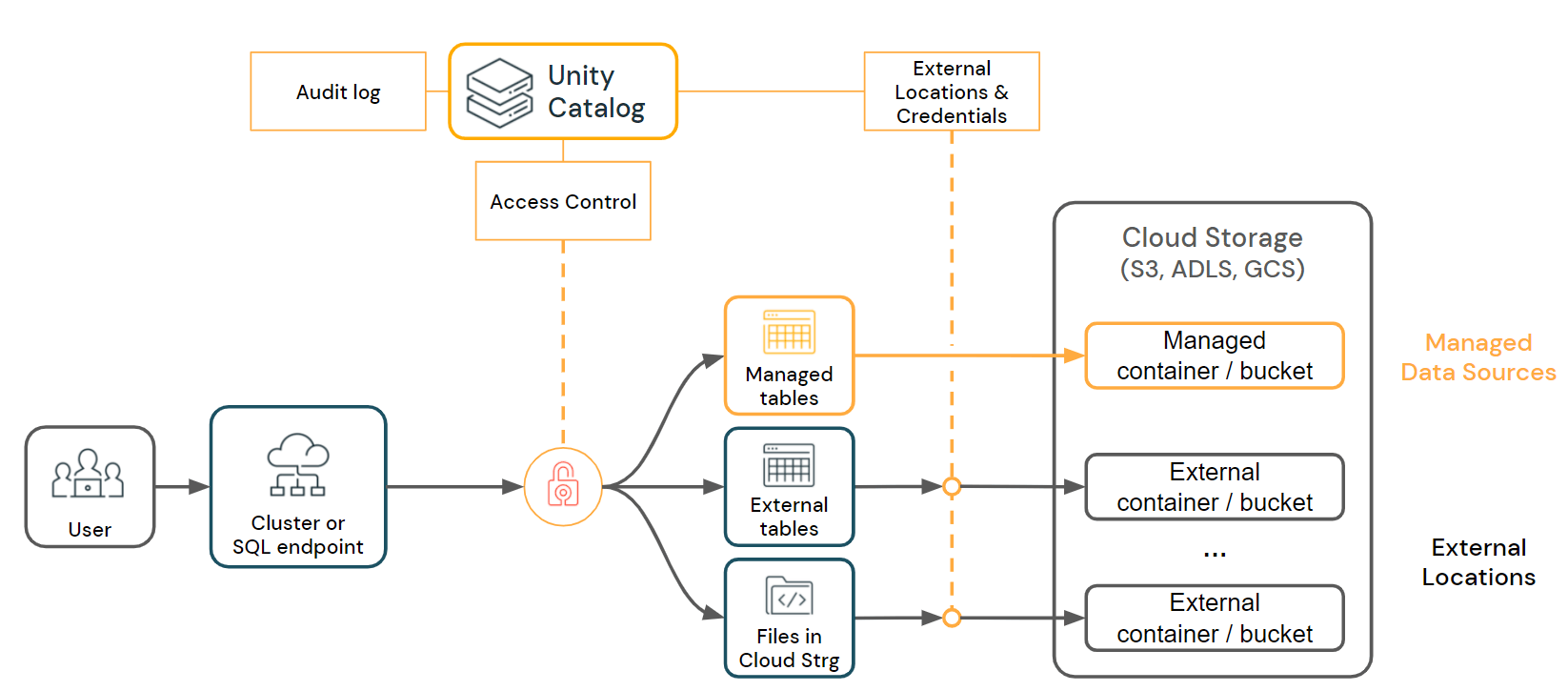 Unity Catalog enables fine-grained access control for managed tables, external tables, and files
Unity Catalog enables fine-grained access control for managed tables, external tables, and filesCentralized Access Controls
Unity Catalog centralizes access controls for files, tables, and views. It leverages dynamic views for fine grained access controls so that you can restrict access to rows and columns to the users and groups who are authorized to query them.
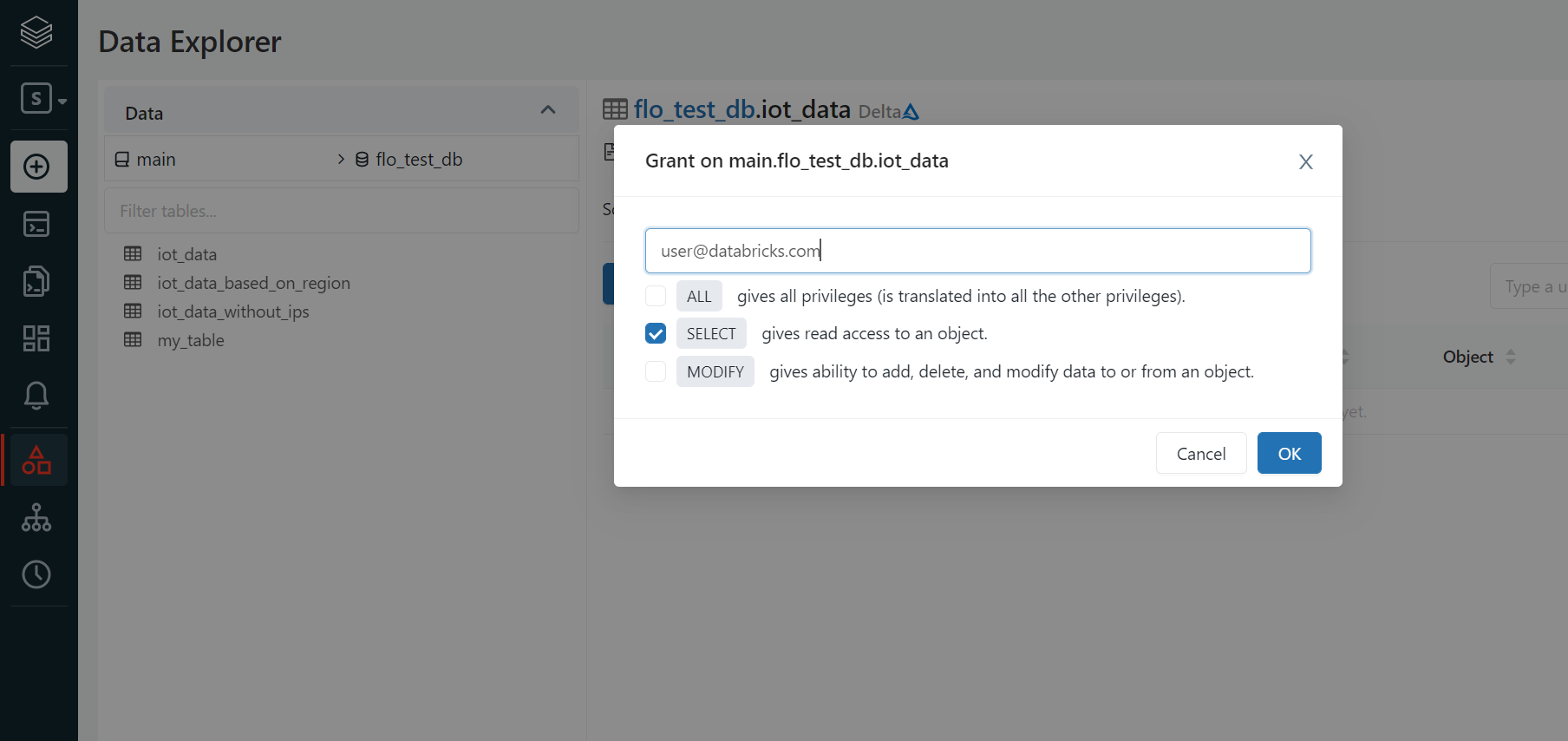
Access Control on Tables and Views
Unity Catalog's current support for fine grained access control includes Column, Row Filter, and Data masking through the use of Dynamic Views.
A Dynamic View is a view that allows you to make conditional statements for display depending on the user or the user's group membership.
For example the following view only allows the '[email protected]' user to view the email column.
Access Control on Files
External Locations control access to files which are not governed by an External Table. For example, in the examples above, we created an External Location at s3://depts/finance and an External Table at s3://depts/finance/forecast.
This means we can still provide access control on files within s3://depts/finance, excluding the forecast directory.
For example consider the following:
Open, simple, and secure data sharing with Delta Sharing
During the Data + AI Summit 2021, we announced Delta Sharing, the world's first open protocol for secure data sharing. Delta Sharing is natively integrated with Unity Catalog, which enables customers to add fine-grained governance, and data security controls, making it easy and safe to share data internally or externally, across platforms or across clouds.
Delta Sharing allows customers to securely share live data across organizations independent of the platform on which data resides or consumed. Organizations can simply share existing large-scale datasets based on the Apache Parquet and Delta Lake formats without replicating data to another system. Delta Sharing also empowers data teams with the flexibility to query, visualize, and enrich shared data with their tools of choice.
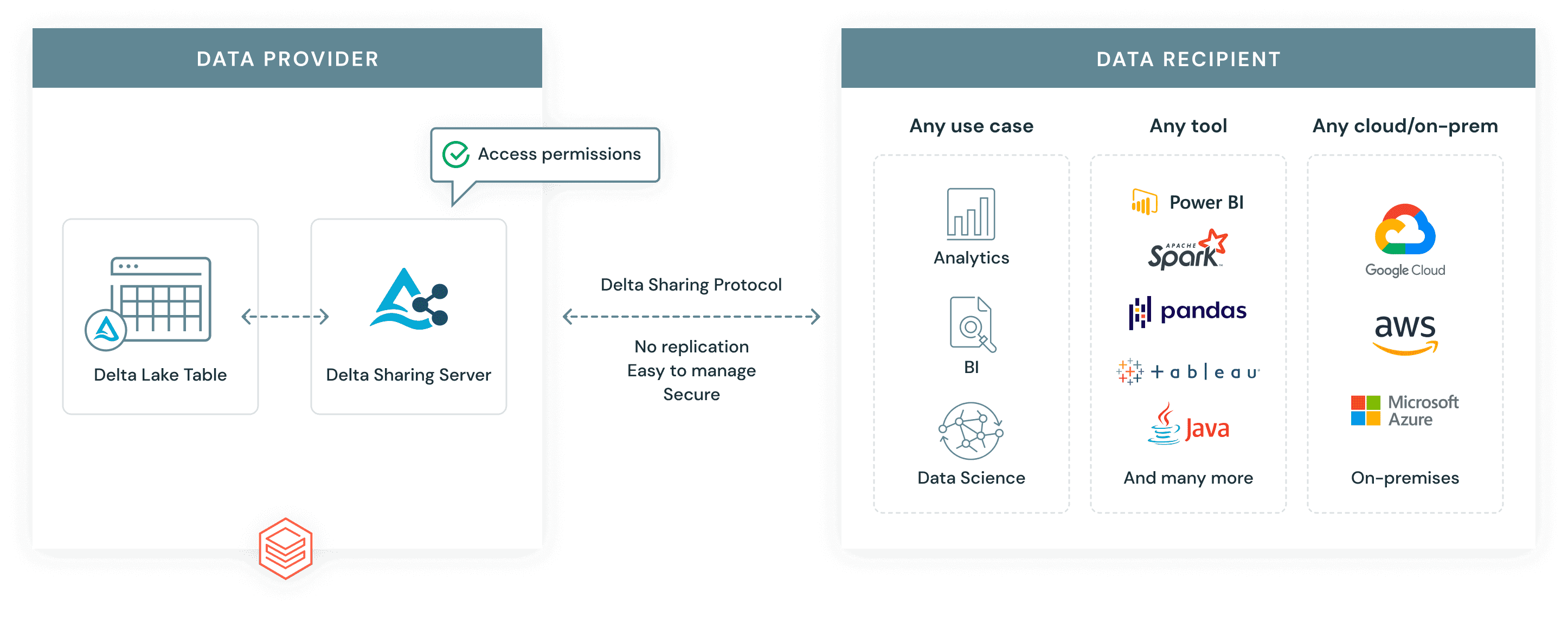
One of the new features available with this release is partition filtering, allowing data providers to share a subset of an organization's data with different data recipients by adding a partition specification when adding a table to a share. We have also improved the Delta Sharing management and introduced recipient token management options for metastore Admins. Today, metastore Admin can create recipients using the CREATE RECIPIENT command and an activation link will be automatically generated for a data recipient to download a credential file including a bearer token for accessing the shared data. With the token management feature, now metastore admins can set expiration date on the recipient bearer token and rotate the token if there is any security risk of the token being exposed.
To learn more about Delta Sharing on Databricks, please visit the Delta Sharing documentation [AWS and Azure].
Centralized Data Access Auditing
Unity Catalog also provides centralized fine-grained auditing by capturing an audit log of actions performed against the data. This enables fine-grained details about who accessed a given dataset, and helps you meet your compliance and business requirements .
Your compact guide to modern analytics

What's coming next
This is just the beginning, and there is an exciting slate of new features coming soon as we work towards realizing our vision for unified governance on the lakehouse. Below you can find a quick summary of what we are working next:
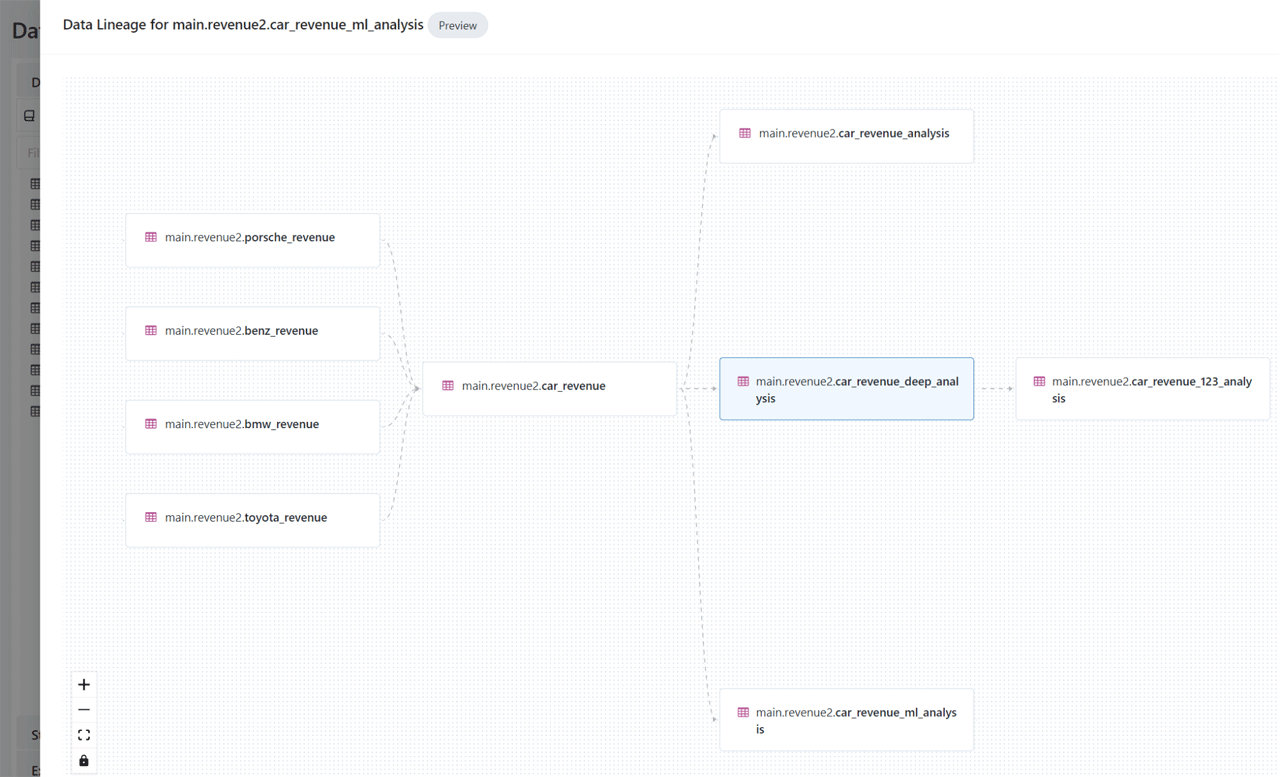
End-to-end Data lineage
Unity Catalog will automatically capture runtime data lineage, down to column and row level, providing data teams an end-to-end view of how data flows in the lakehouse, for data compliance requirements and quick impact analysis of data changes.
Deeper Integrations with enterprise data catalogs and governance solutions
We are working with our data catalog and governance partners to empower our customers to use Unity Catalog in conjunction with their existing catalogs and governance solutions.
Data discovery and search
With built-in data search and discovery, data teams can quickly search and reference relevant data sets, boosting productivity and accelerating time to insights.
Governance and sharing of machine learning models/dashboards
We are also expanding governance to other data assets such as machine learning models, dashboards, providing data teams a single pane of glass for managing, governing, and sharing different data assets types.
Fine-grained governance with Attribute Based Access Controls (ABACs)
We are also adding a powerful tagging feature that lets you control access to multiple data items at once based on user and data attributes , further simplifying governance at scale. For example, you will be able to tag multiple columns as PII and manage access to all columns tagged as PII in a single rule.
Unity Catalog on Google Cloud Platform (GCP)
Unity Catalog support for GCP is also coming soon.
Getting Started with Unity Catalog on AWS and Azure
Visit the Unity Catalog documentation [AWS, Azure] to learn more.