Building a Modern Clinical Health Data Lake with Delta Lake

The healthcare industry is one of the biggest producers of data. In fact, the average healthcare organization is sitting on nearly 9 petabytes of medical data. The rise of electronic health records (EHR), digital medical imagery, and wearables are contributing to this data explosion. For example, an EHR system at a large provider can catalogue millions of medical tests, clinical interactions, and prescribed treatments. And the potential to learn from this population scale data is massive. By building analytic dashboards and machine learning models on top of these datasets, healthcare organizations can improve the patient experience and drive better health outcomes. Here are few real-world examples:
|
Preventing Neonatal Sepsis
|
Early Detection of Chronic Disease
|
Tracking Diseases Across Populations
|
Preventing Claims Fraud and Abuse
|

Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Top 3 Big Data Challenges for Healthcare Organizations
Despite the opportunity to improve patient care with analytics and machine learning, healthcare organizations face the classical big data challenges:
- Variety - The delivery of care produces a lot of multidimensional data from a variety of data sources. Healthcare teams need to run queries across patients, treatments, facilities and time windows to build a holistic view of the patient experience. This is compute intensive for legacy analytics platforms. On top of that, 80% of healthcare data is unstructured (e.g. clinical notes, medical imaging, genomics, etc). Unfortunately, traditional data warehouses, which serve as the analytics backbone for most healthcare organizations, don’t support unstructured data.
- Volume - some organizations have started investing in health data lakes to bring their petabytes of structured and unstructured data together. Unfortunately, traditional query engines struggle with data volumes of this magnitude. A simple ad-hoc analysis can take hours or days. This is too long to wait when adjusting for patient needs in real-time.
- Velocity - patients are always coming into the clinic or hospital. With a constant flow of data, EHR records may need to be updated to fix coding errors. It’s critical that a transactional model exists to allow for updates.
As if this wasn’t challenging enough, the data store must also support data scientists who need to run ad-hoc transformations, like creating a longitudinal view of a patient, or build predictive insights with machine learning techniques.
Fortunately, Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads, along with Apache SparkTM can help solve these challenges by providing a transactional store that supports fast multidimensional queries on diverse data along with rich data science capabilities. With Delta Lake and Apache Spark, healthcare organizations can build a scalable clinical data lake for analytics and ML.
In this blog series, we’ll start by walking through a simple example showing how Delta Lake can be used for ad hoc analytics on health and clinical data. In future blogs, we will look at how Delta Lake and Spark can be coupled together to process streaming HL7/FHIR datasets. Finally, we will look at a number of data science use cases that can run on top of a health data lake built with Delta Lake.
Using Delta Lake to Build a Comorbidity Dashboard
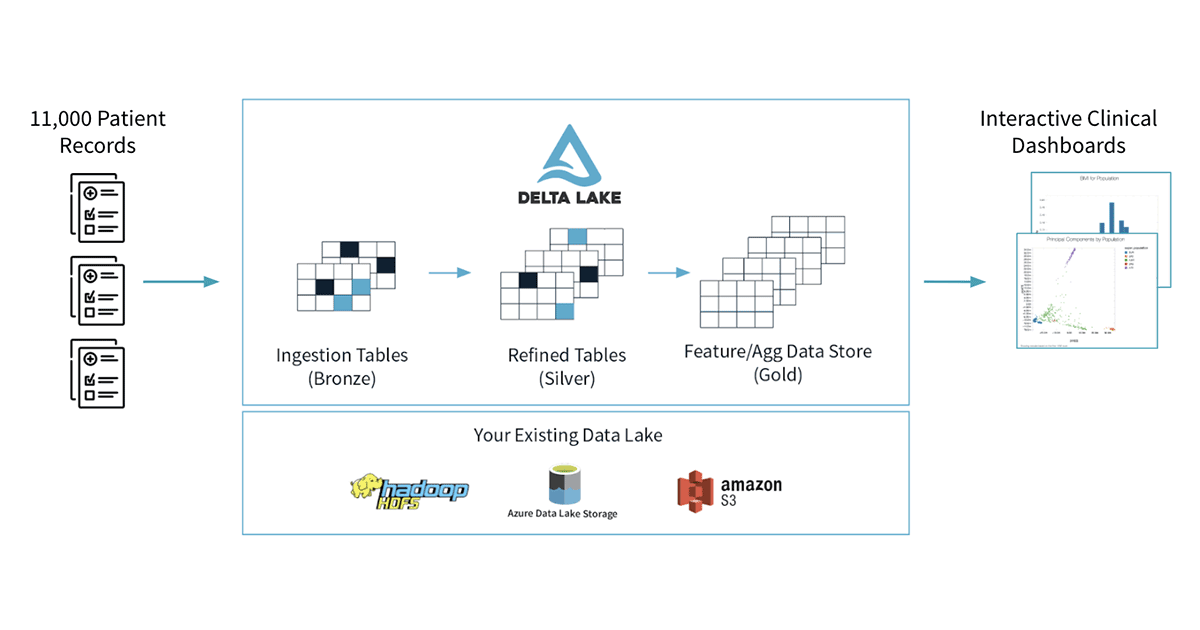
To demonstrate how Delta Lake makes it easier to work with large clinical datasets, we will start off with a simple but powerful use case. We will build a dashboard that allows us to identify comorbid conditions (one or more diseases or conditions that occur along with another condition in the same person at the same time) across a population of patients. To do this, we will use a simulated EHR dataset, generated by the Synthea simulator, made available through Databricks Datasets (AWS | Azure). This dataset represents a cohort of approximately 11,000 patients from Massachusetts, and is stored in 12 CSV files. We will load the CSV files in, before masking protected health information (PHI) and joining the tables together to get the data representation we need for our downstream query. Once the data has been refined, we will use SparkR to build a dashboard that allows us to interactively explore and compute common health statistics on our dataset.
This use case is a very common starting point. In a clinical setting, we may look at comorbidities as a way to understand the risk of a patient’s disease increasing in severity. From a medical coding and financial perspective, looking at comorbid diseases may allow us to identify common medical coding issues that impact reimbursement. In pharmaceutical research, looking at comorbid diseases with shared genetic evidence may give us a deeper understanding of the function of a gene.
However, when we think about the underlying analytics architecture, we are also at a starting point. Instead of loading data in one large batch, we might seek to load streaming EHR data to allow for real-time analytics. Instead of using a dashboard that gives us simple insights, we may advance to machine learning use cases, such as training a machine learning model that uses data from recent patient encounters to predict the progression of a disease. This can be powerful in an ER setting where streaming data and ML can be used to predict the likelihood of a patient improving or declining in real-time.
In the rest of this blog, we will walk through the implementation of our dashboard. We will first start by using Apache Spark and Delta Lake to ETL our simulated EHR dataset. Once the data has been prepared for analysis, we will then create a notebook that identifies comorbid conditions in our dataset. By using built-in capabilities in Databricks (AWS | Azure), we can then directly transform the notebook into a dashboard.
A Hands-On Guide to Apps on Databricks

ETLing Clinical Data into Delta Lake
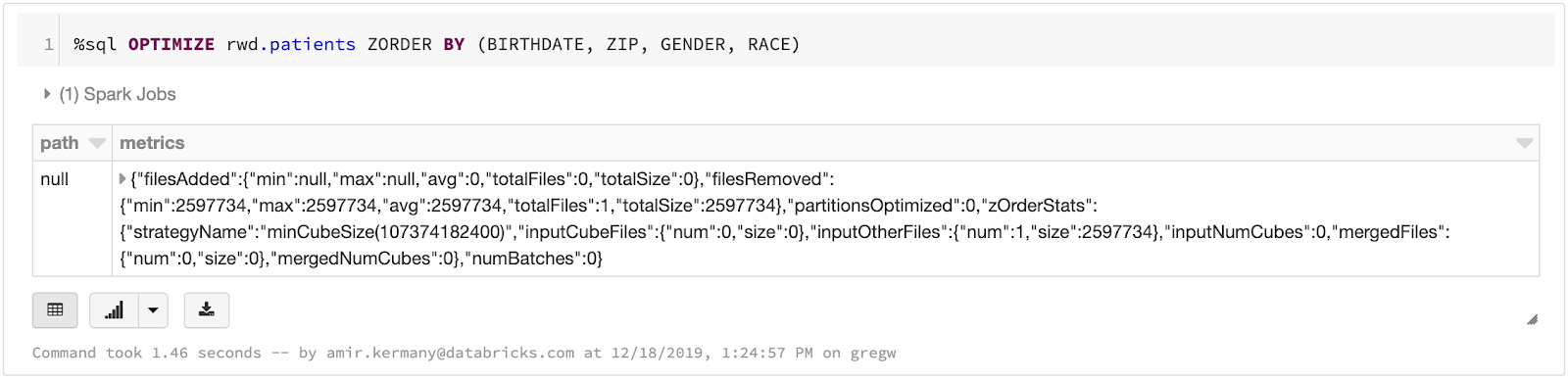
To start off, we need to load our CSV data dump into a consistent representation that we can use for our analytical workloads. By using Delta Lake, we can accelerate a number of the downstream queries that we will run. Delta Lake supports Z-ordering, which allows us to efficiently query data across multiple dimensions. This is critical for working with EHR data, as we may want to slice and dice our data by patient, by date, by care facility, or by condition, amongst other things. Additionally, the managed Delta Lake offering in Databricks provides additional optimizations, which accelerate exploratory queries into our dataset. Delta Lake also future-proofs our work: while we aren’t currently working with streaming data, we may work with live streams from an EHR system in the future, and Delta Lake’s ACID semantics (AWS | Azure) make working with streams simple and reliable.
Our workflow follows a few steps that we show in the figure below. We will start by loading the raw/bronze data from our eight different CSV files, we will mask any PHI that is present in the tables, and we will write out a set of silver tables. We will then join our silver tables together to get an easier representation to work with for downstream queries.
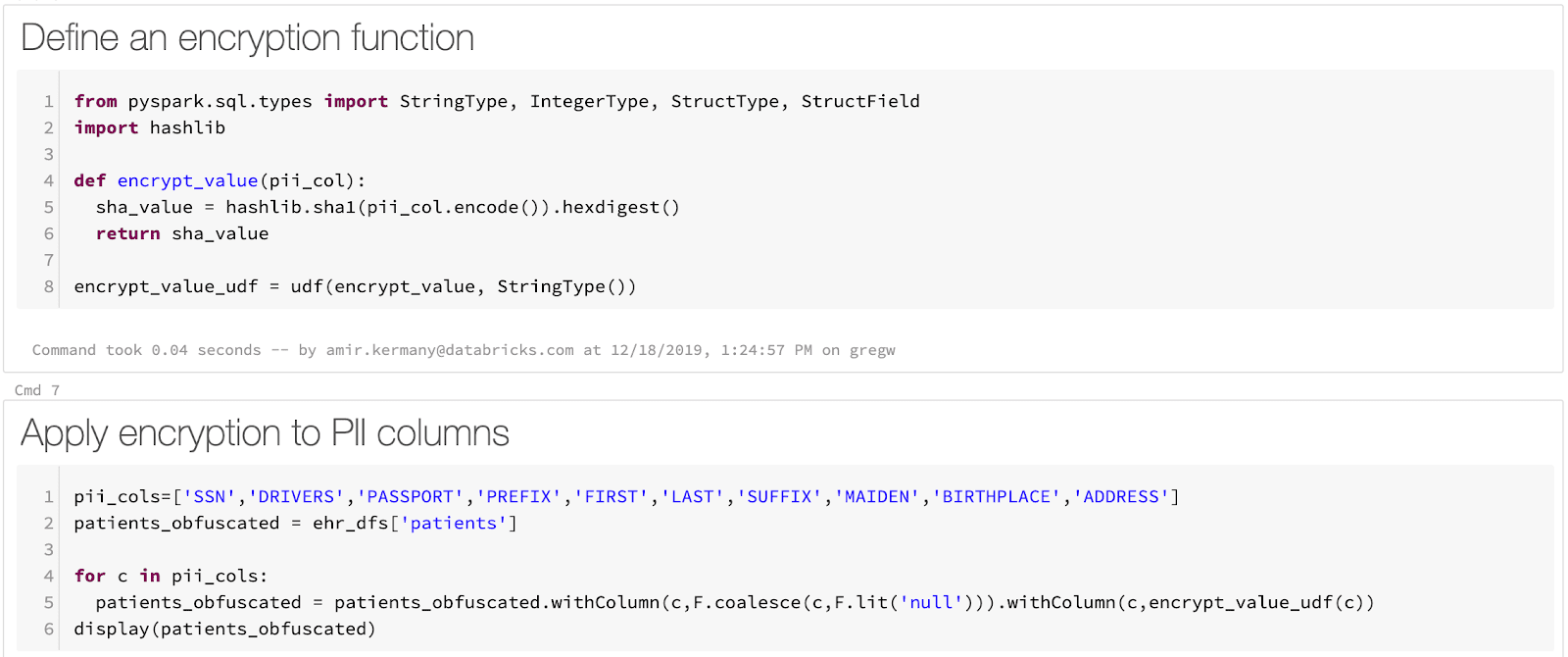
Loading our raw CSV files into Delta Lake tables is a straightforward process. Apache Spark has native support for loading CSV, and we are able to load our files with a single line of code per file. While Spark does not have in-built support for masking PHI, we can use Spark’s rich support for user defined functions (UDFs, AWS | Azure) to define an arbitrary function that deterministically masks fields with PHI or PII. In our example notebook, we use a Python function to compute a SHA1 hash. Finally, saving the data into Delta Lake is a single line of code.
Once data has been loaded into Delta, we can optimize the tables by running a simple SQL command. In our example comorbid condition prediction engine, we will want to rapidly query across both the patient ID and the condition they were evaluated for. By using Delta Lake’s Z-ordering command, we can optimize the table so it can be rapidly queried down either dimension. We have done this on one of our final gold tables, which has joined several of our silver tables together to achieve the data representation we will need for our dashboard.
Building a Comorbidity Dashboard
Now that we have prepared our dataset, we will build our dashboard allowing us to explore comorbid conditions, or more simply put, conditions that commonly co-occur in a single patient. Some of the time, these can be precursors/risk factors, for example, high blood pressure is a well known risk factor for stroke and other cardiovascular diseases. By discovering and monitoring comorbid conditions, and other health statistics, we can improve care by identifying risks and advising patients on preventative steps they can take. Ultimately, identifying comorbidities is a counting exercise! We need to identify the distinct set of patients who had both condition A and condition B, which means it can be done all fully in SQL using Spark SQL. In our dashboard, we will follow a simple three step process:
-
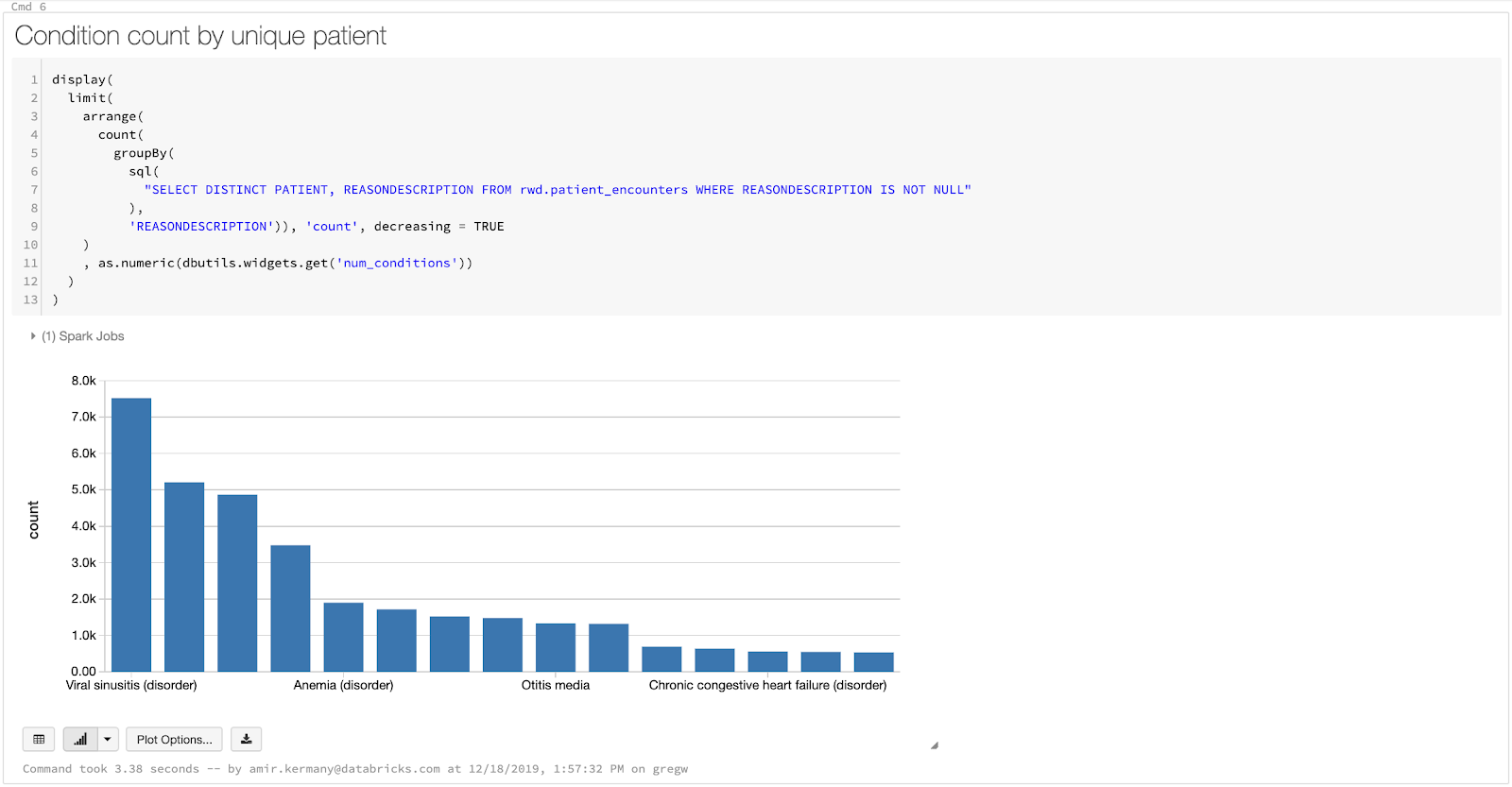
- First, we create a data frame that has conditions, ranked by the number of patients they occurred in. This allows the user to visualize the relative frequency of the most common conditions in their dataset.
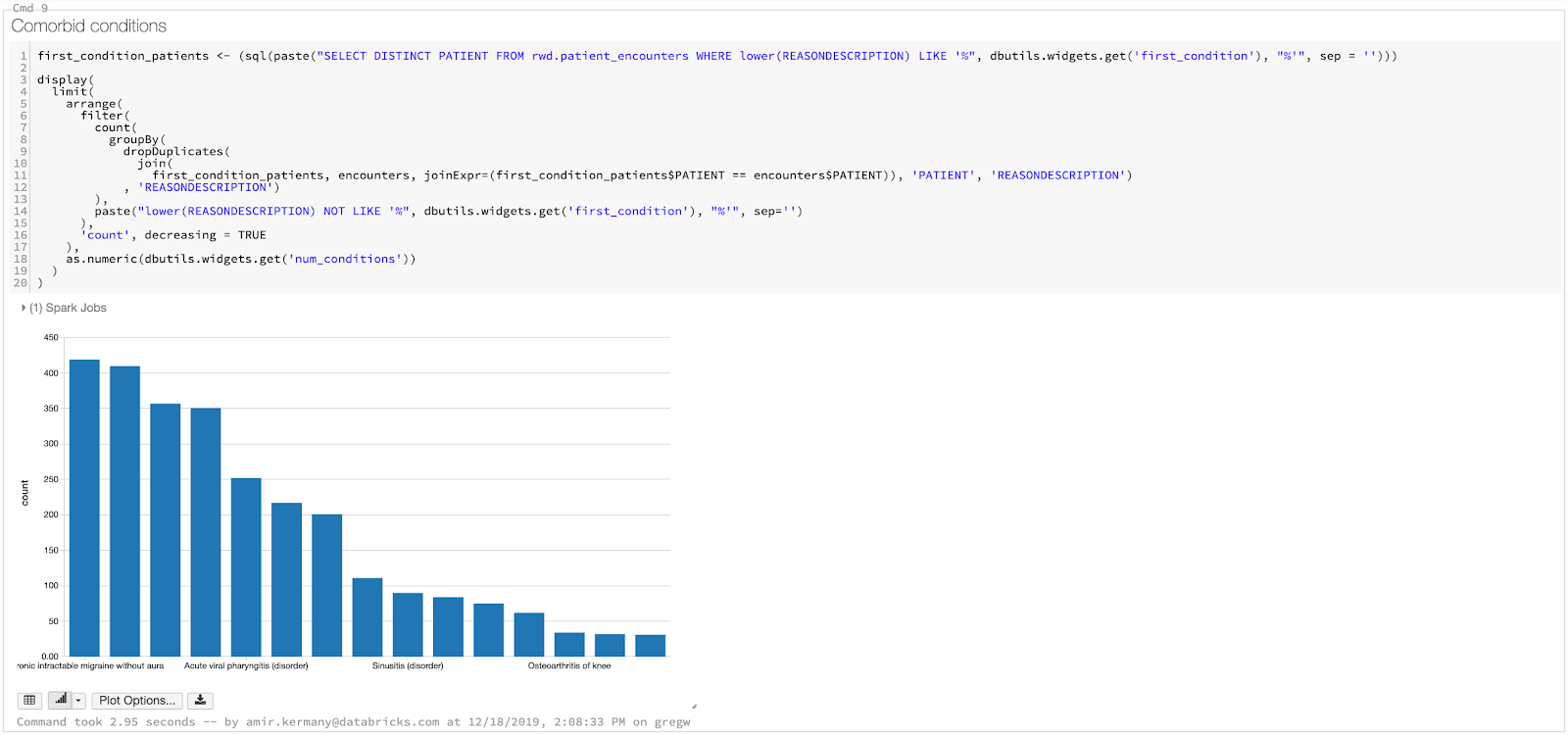
- Since we do this in Spark SQL using SparkR, we can easily collect the count of patients at the end and use a χ2 test to compute significance. We print whether or not the association between the two conditions is statistically significant.
While a data scientist who is rapidly iterating to understand what trends lie in their dataset may be happy working in a notebook, we will encounter a number of users (clinicians, public health officials and researchers, operations analysts, billing analysts) who are less interested in seeing the code underlying the analysis. By using the built-in dashboarding function, we can hide the code and focus on the visualizations we’ve generated. Since we added widgets into our notebook, our users can still provide input to the notebook and change which diseases to compare.
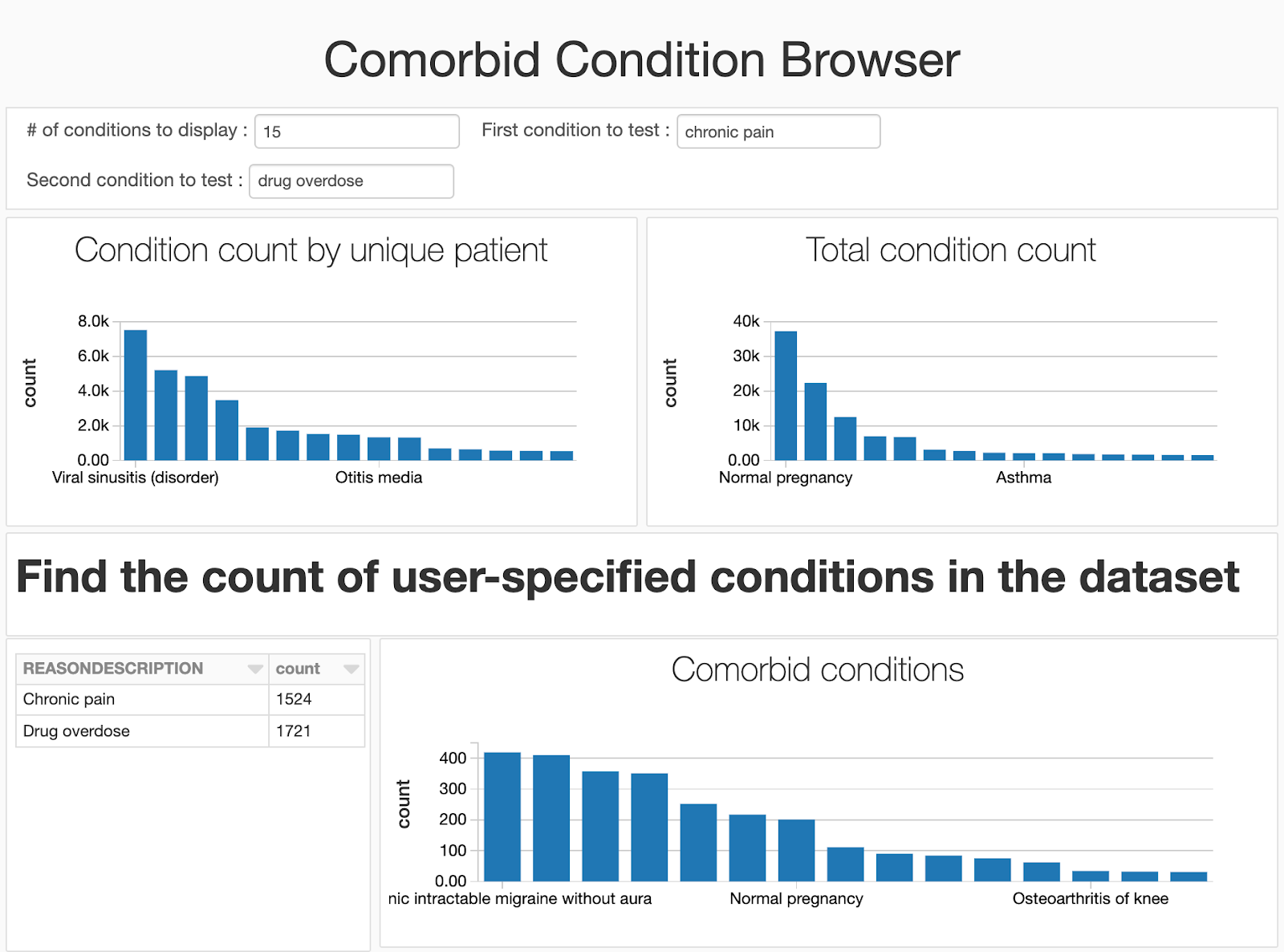
Get Started Building Your Clinical Data Lake
In this blog, we laid down the fundamentals for building a scalable health data lake with Delta Lake and a simple comorbidity dashboard. To learn more about using Delta Lake to store and process health and clinical datasets:
- Download our eBook on working with real world clinical datasets.
- Sign-up for a free Databricks trial and start experimenting with our ETL and dashboarding notebooks highlighted in this blog.
Solution Accelerators
April 21, 2020/8 min read