Databricks on AWS
The simple, unified data platform seamlessly integrated with AWS
Available in AWS Marketplace

Databricks on AWS allows you to store and manage all your data on a simple, open lakehouse platform that combines the best of data warehouses and data lakes to unify all your analytics and AI workloads.
Why Databricks on AWS?
Simple
Databricks enables a single, unified data architecture on S3 for SQL analytics, data science and machine learning
12x better price/performance
Get data warehouse performance at data lake economics through SQL-optimized compute clusters
Proven
Thousands of customers have implemented Databricks on AWS to provide a game-changing analytics platform that addresses all analytics and AI use cases

Featured integrations
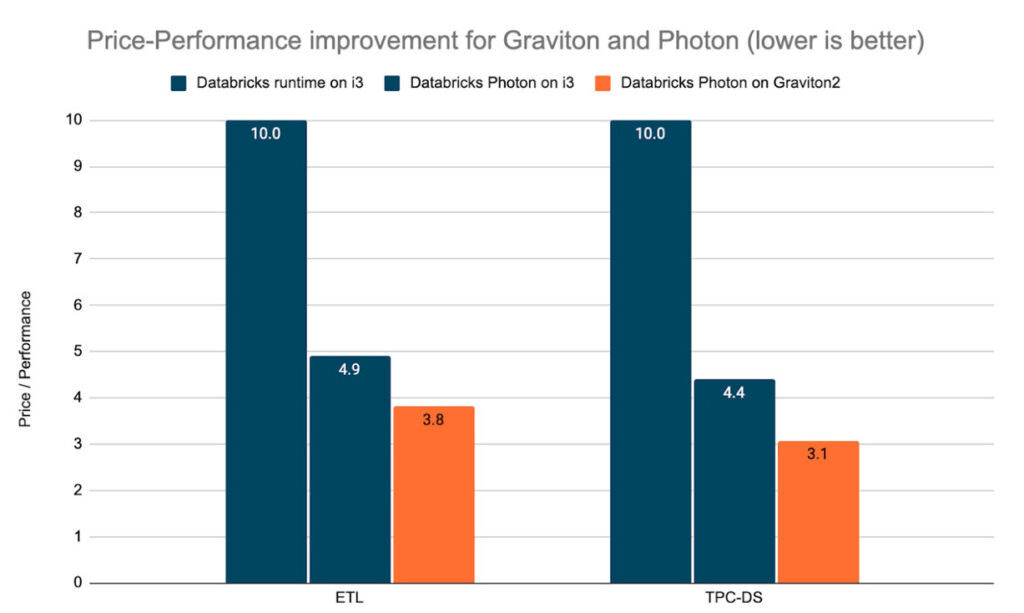
AWS Graviton
Databricks clusters support AWS Graviton instances. These instances use AWS-designed Graviton processors that are built on top of the Arm64 instruction set architecture. AWS claims that instance types with these processors have the best price/performance ratio of any instance type on Amazon EC2. Read more
Use Cases
Awards and Recognitions


Resources
Whitepapers
Webinars
Industries
Ready to get started?