Apache Spark 1.1: MLlib Performance Improvements
by Burak Yavuz
With an ever-growing community, Apache Spark has had it’s 1.1 release. MLlib has had its fair share of contributions and now supports many new features. We are excited to share some of the performance improvements observed in MLlib since the 1.0 release, and discuss two key contributing factors: torrent broadcast and tree aggregation.
Torrent broadcast
The beauty of Spark as a unified framework is that any improvements made on the core engine come for free in its standard components like MLlib, Spark SQL, Streaming, and GraphX. In Apache Spark 1.1, we changed the default broadcast implementation of Spark from the traditional HttpBroadcast to TorrentBroadcast, a BitTorrent like protocol that evens out the load among the driver and the executors. When an object is broadcasted, the driver divides the serialized object into multiple chunks, and broadcasts the chunks to different executors. Subsequently, executors can fetch chunks individually from other executors that have fetched the chunks previously.
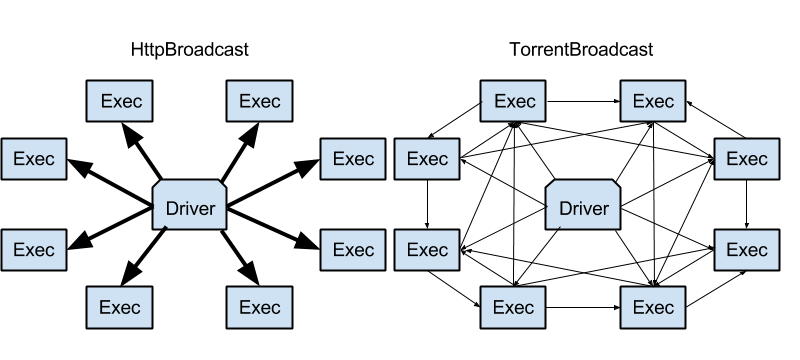
How does this change in Spark Core affect MLlib’s performance?
A common communication pattern in machine learning algorithms is the one-to-all broadcast of intermediate models at the beginning of each iteration of training. In large-scale machine learning, models are usually huge and broadcasting them via http can make the driver a severe bottleneck because all executors (workers) are fetching the models from the driver. With the new torrent broadcast, this load is shared among executors as well. It leads to significant speedup, and MLlib takes it for free.
Tree aggregation
Similar to broadcasting models at the beginning of each iteration, the driver builds new models at the end of each iteration by aggregating partial updates collected from executors. This is the basis of the MapReduce paradigm. One performance issue with the reduce or aggregate functions in Spark (and the original MapReduce) is that the aggregation time scales linearly with respect to the number of partitions of data (due to the CPU cost in merging partial results and the network bandwidth limit).
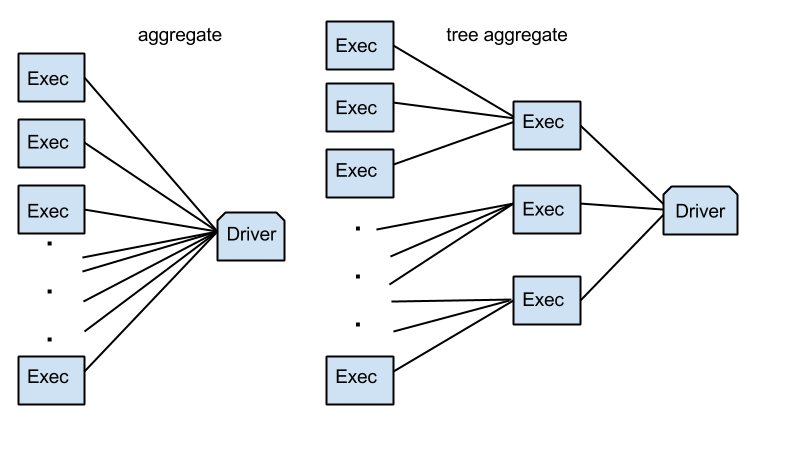
In MLlib 1.1, we introduced a new aggregation communication pattern based on multi-level aggregation trees. In this setup, model updates are combined partially on a small set of executors before they are sent to the driver, which dramatically reduces the load the driver has to deal with. Tests showed that these functions reduce the aggregation time by an order of magnitude, especially on datasets with a large number of partitions.
Performance improvements
Changing the way models are broadcasted and aggregated has a huge impact on performance. Below, we present empirical results comparing the performance on some of the common machine learning algorithms in MLlib. The x-axis can be thought of the speedup the 1.1 release has over the 1.0 release. Speedups between 1.5-5x can be observed across all algorithms. The tests were performed on an EC2 cluster with 16 slaves, using m3.2xlarge instances. The scripts to run the tests are a part of the “spark-perf” test suite which can be found on https://github.com/databricks/spark-perf.
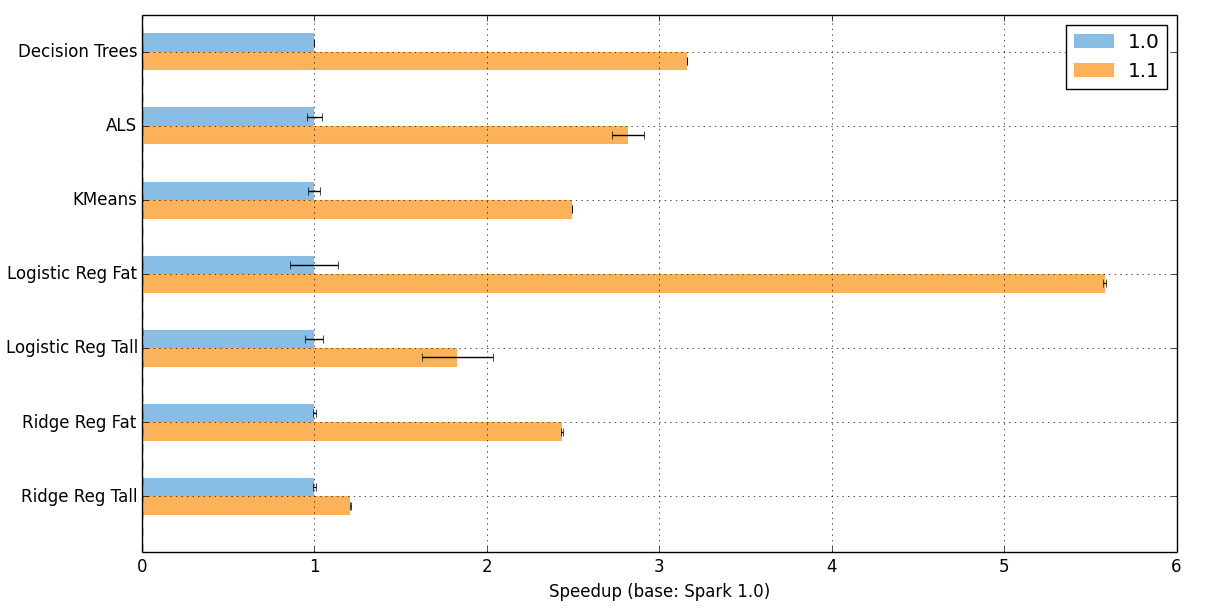
For ridge regression and logistic regression, the Tall identifier corresponds to a tall-skinny matrix (1,000,000 x 10,000) and Fat corresponds to a short-fat matrix (10,000 x 1,000,000).
Performance improvements in distributed machine learning typically come from a combination of communication pattern improvements and algorithmic improvements. We focus on the former in this post, and algorithmic improvements will be discussed later. So download Spark 1.1 now, enjoy the performance improvements, and stay tuned for future posts.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.