Pearson uses Apache Spark Streaming for next generation adaptive learning platform
Introduction of Pearson
Pearson is a British multinational publishing and education company headquartered in London. It is the largest education company and the largest book publisher in the world. Recently, Pearson announced a new organization structure in order to accelerate their push into digital learning, education services and emerging markets. I am part of Pearson Higher Education group, which provides textbooks and digital technologies to teachers and students across Higher Education. Pearson's higher education brands include eCollege, Mastering/MyLabs and Financial Times Publishing.
What we wanted to do
We are building a next generation adaptive learning platform which delivers immersive learning experiences designed for the way today’s students read, think, and learn. This learning platform is a scalable, reliable, cloud-based platform providing services to power the next generation of products for Higher Education. With a common data platform, we analyze student performance across product and institution boundaries and deliver efficacy insights to learners and institutions, which we were not able to deliver before. This platform will help Pearson to build new products faster and offer the world's greatest collection of educational content, while delivering most advanced data, analytics, adaptive and personalized capabilities for education.
Why we chose Apache Spark and Spark Streaming
Now to get the deep understanding of millions of learners, we needed a big data approach, and we found that a huge opportunity exists for ground-breaking industry-leading innovation in learner analytics. We have various use cases ranging from Near Real Time services, building Learner Graph, developing a common learner model for performing adaptive learning and recommendation, and different search based analytics etc. We found Apache Spark is one product which can bring all such capabilities into one platform. Spark supports both batch and real time mode of data processing along with graph analytics and machine learning libraries.
Pearson Near Real Time architecture is designed using Spark Streaming. Spark MLLib will be useful for Pearson Machine Learning use cases and Spark Graph Library will be useful for building learner graph in single common platform. Having common APIs and data processing semantics, Spark will help Pearson to build its skills and capabilities in a single platform rather than learning and managing various disparate tools.
Having a single platform and common API paradigm is one of the key reason we have moved our real time stack to Spark Streaming from our earlier solution which was designed using Apache Storm.
What we did
Pearson's stream processing architecture is built using Apache Kafka and Spark Streaming.
Apache Kafka is a distributed messaging infrastructure and in Pearson's implementation, all students' activity and contextual data comes to Kafka cluster from different learning applications. Spark Streaming collects this data from Kafka in near-real-time and perform necessary transformations and aggregation on the fly to build the common learner data model and persists the data in NoSQL store (presently we are using Cassandra). For search related use cases, Spark Streaming consumes messages from Kafka and index them into Apache Blur, which is a distributed search engine on top of HDFS. For both these use cases, we needed a reliable, fault-tolerant Kafka consumer which can consume messages from Kafka topics without any data loss scenarios. Below diagram shows a high level overview of different components in this data pipeline.
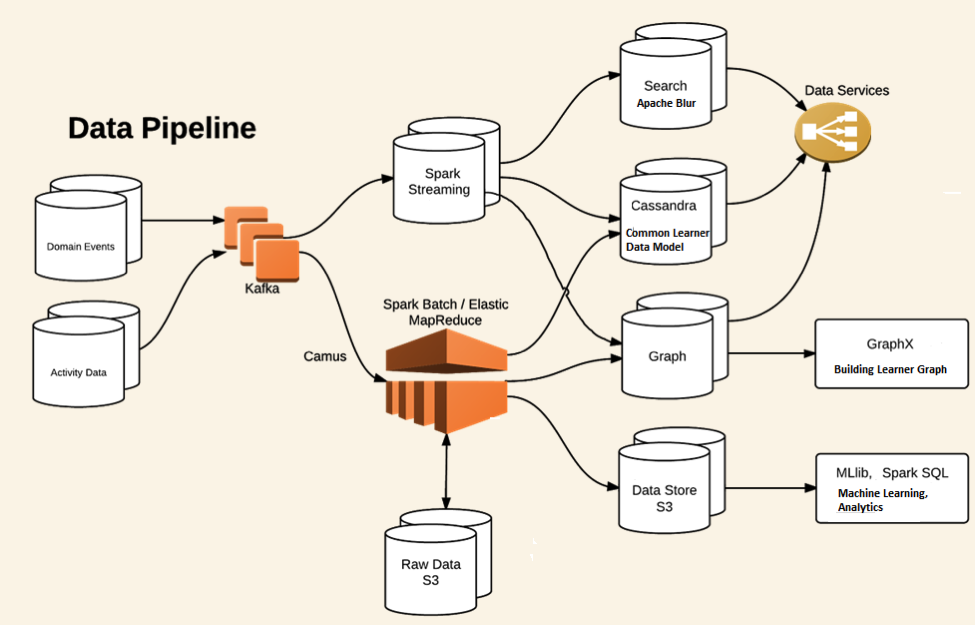
Next figure highlights the functionality of the Spark Streaming application. All the student/instructor activities and domain events from different learning applications are combined together to continuously update the learning model of each student.
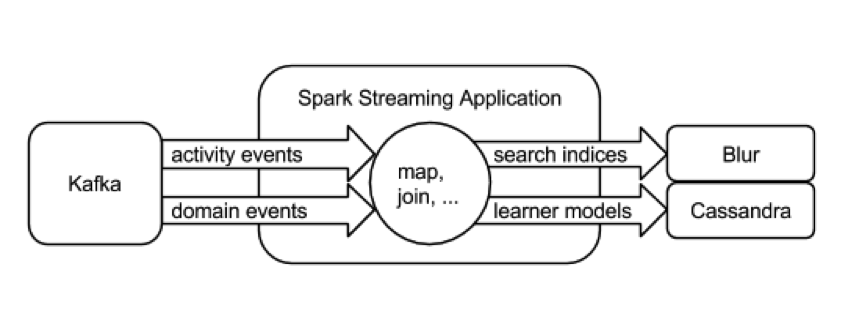
In real time streaming use cases, Kafka is becoming a most adopted platform for distributed messaging system and this prompts various streaming layer like Spark Streaming to have a built-in Kafka Consumer, so that streaming layer can seamlessly fit into this architecture. When we started working on Spark Streaming and Kafka, we wanted to achieve better performance and stronger guarantees than those provided by the built-in high-level Kafka receiver of Spark Streaming. Hence, we chose to write our custom Kafka receiver. This custom Kafka Consumer for Spark Streaming uses the Low Level Kafka Consumer APIs, and is the most robust, high performant Kafka consumer available for Spark. This consumer handles Kafka node failures, leader changes, manages committed offset in ZK and can have tunable data rate throughput. It also solves the data loss scenarios on Receiver failures.
Pearson runs Spark Streaming in Amazon Cloud with YARN managed cluster. The building of common learner data model architecture using Spark Streaming will be in production by end of 2014. The Search based solution will be in production by Q1 2015. Other solutions like Learner Graph or advanced Machine Learning solution will be developed in 2015.
To Learn More:
For more information, please refer to my recent talk (slides) at the Lucene/SolrRevolution conference.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.