Random Forests and Boosting in MLlib
by Joseph Bradley and Manish Amde
Apache Spark 1.2 introduces Random Forests and Gradient-Boosted Trees (GBTs) into MLlib. Suitable for both classification and regression, they are among the most successful and widely deployed machine learning methods. Random Forests and GBTs are ensemble learning algorithms, which combine multiple decision trees to produce even more powerful models. In this post, we describe these models and the distributed implementation in MLlib. We also present simple examples and provide pointers on how to get started.
Ensemble Methods
Simply put, ensemble learning algorithms build upon other machine learning methods by combining models. The combination can be more powerful and accurate than any of the individual models.
In MLlib 1.2, we use Decision Trees as the base models. We provide two ensemble methods: Random Forests and Gradient-Boosted Trees (GBTs). The main difference between these two algorithms is the order in which each component tree is trained.
Random Forests train each tree independently, using a random sample of the data. This randomness helps to make the model more robust than a single decision tree, and less likely to overfit on the training data.
GBTs train one tree at a time, where each new tree helps to correct errors made by previously trained trees. With each tree added, the model becomes even more expressive.
In the end, both methods produce a weighted collection of Decision Trees. The ensemble model makes predictions by combining results from the individual trees. The figure below shows a simple example of an ensemble with three trees.
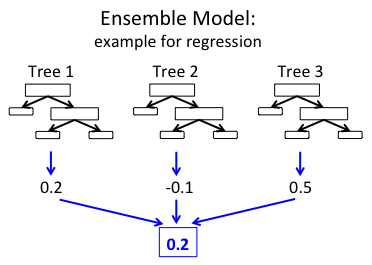
In the example regression ensemble above, each tree predicts a real value. These three predictions are then combined to produce the ensemble's final prediction. Here, we combine predictions using the mean (but the algorithms use different techniques depending on the prediction task).
Distributed Learning of Ensembles
In MLlib, both Random Forests and GBTs partition data by instances (rows). The implementation builds upon the original Decision Tree code, which distributes learning of single trees (described in an earlier blog post). Many of our optimizations are based upon Google's PLANET project, one of the major published works on learning ensembles of trees in the distributed setting.
Random Forests: Since each tree in a Random Forest is trained independently, multiple trees can be trained in parallel (in addition to the parallelization for single trees). MLlib does exactly that: A variable number of sub-trees are trained in parallel, where the number is optimized on each iteration based on memory constraints.
GBTs: Since GBTs must train one tree at a time, training is only parallelized at the single tree level.
We would like to highlight two key optimizations used in MLlib:
- Memory: Random Forests use a different subsample of the data to train each tree. Instead of replicating data explicitly, we save memory by using a TreePoint structure which stores the number of replicas of each instance in each subsample.
- Communication: Whereas Decision Trees are usually trained by selecting from all features at each decision node in the tree, Random Forests often limit the selection to a random subset of features at each node. MLlib’s implementation takes advantage of this subsampling to reduce communication: e.g., if only 1/3 of the features are used at each node, then we can reduce communication by a factor of 1/3.
For more details, see the Ensembles Section in the MLlib Programming Guide.
Using MLlib Ensembles
We demonstrate how to learn ensemble models using MLlib. The following Scala examples show how to read in a dataset, split the data into training and test sets, learn a model, and print the model and its test accuracy. Refer to the MLlib Programming Guide for examples in Java and Python. Note that GBTs do not yet have a Python API, but we expect it to be in the Spark 1.3 release (via Github PR 3951).
Random Forest Example
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.configuration.Strategy
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data =
MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training/test sets
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a RandomForest model.
val treeStrategy = Strategy.defaultStrategy("Classification")
val numTrees = 3 // Use more in practice.
val featureSubsetStrategy = "auto" // Let the algorithm choose.
val model = RandomForest.trainClassifier(trainingData,
treeStrategy, numTrees, featureSubsetStrategy, seed = 12345)
// Evaluate model on test instances and compute test error
val testErr = testData.map { point =>
val prediction = model.predict(point.features)
if (point.label == prediction) 1.0 else 0.0
}.mean()
println("Test Error = " + testErr)
println("Learned Random Forest:n" + model.toDebugString)
Gradient-Boosted Trees Example
import org.apache.spark.mllib.tree.GradientBoostedTrees
import org.apache.spark.mllib.tree.configuration.BoostingStrategy
import org.apache.spark.mllib.util.MLUtils
// Load and parse the data file.
val data =
MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training/test sets
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// Train a GradientBoostedTrees model.
val boostingStrategy =
BoostingStrategy.defaultParams("Classification")
boostingStrategy.numIterations = 3 // Note: Use more in practice
val model =
GradientBoostedTrees.train(trainingData, boostingStrategy)
// Evaluate model on test instances and compute test error
val testErr = testData.map { point =>
val prediction = model.predict(point.features)
if (point.label == prediction) 1.0 else 0.0
}.mean()
println("Test Error = " + testErr)
println("Learned GBT model:n" + model.toDebugString)
Scalability
We demonstrate the scalability of MLlib ensembles with empirical results on a binary classification problem. Each figure below compares Gradient-Boosted Trees ("GBT") with Random Forests ("RF"), where the trees are built out to different maximum depths.
These tests were on a regression task of predicting song release dates from audio features (the YearPredictionMSD dataset from the UCI ML repository). We used EC2 r3.2xlarge machines. Algorithm parameters were left as defaults except where noted.
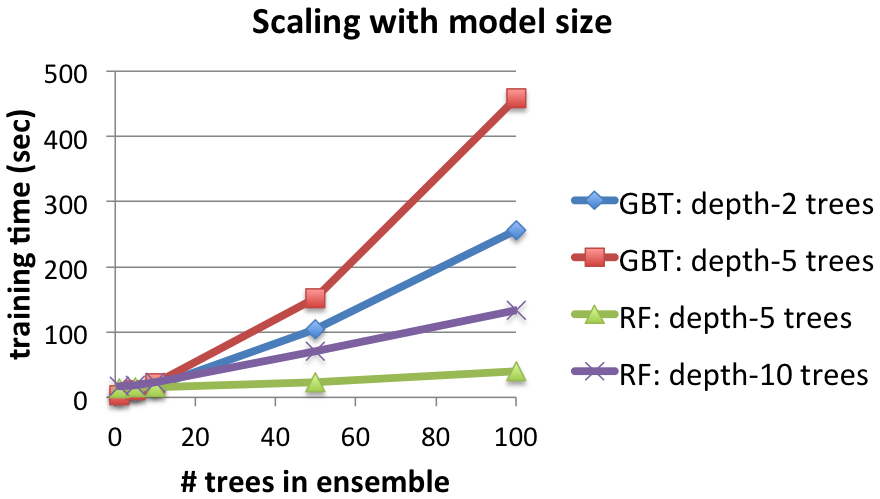
Scaling model size: Training time and test error
The two figures below show the effect of increasing the number of trees in the ensemble. For both, increasing trees require more time to learn (first figure) but also provide better results in terms of test Mean Squared Error (MSE) (second figure).
Comparing the two methods, Random Forests are faster to train, but they often require deeper trees than GBTs to achieve the same error. GBTs can further reduce the error with each iteration, but they can begin to overfit (increase test error) after too many iterations. Random Forests do not overfit as easily, but their test error plateaus.
Below, for a basis for understanding the MSE, note that the left-most points show the error when using a single decision tree (of depths 2, 5, or 10, respectively).
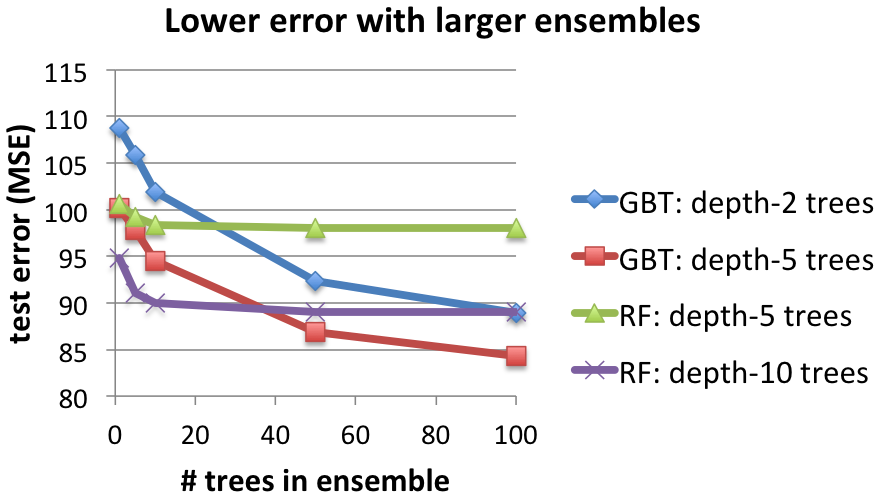
Details: 463,715 training instances. 16 workers.
Scaling training dataset size: Training time and test error
The next two figures show the effect of using larger training datasets. With more data, both methods take longer to train but achieve better test results.
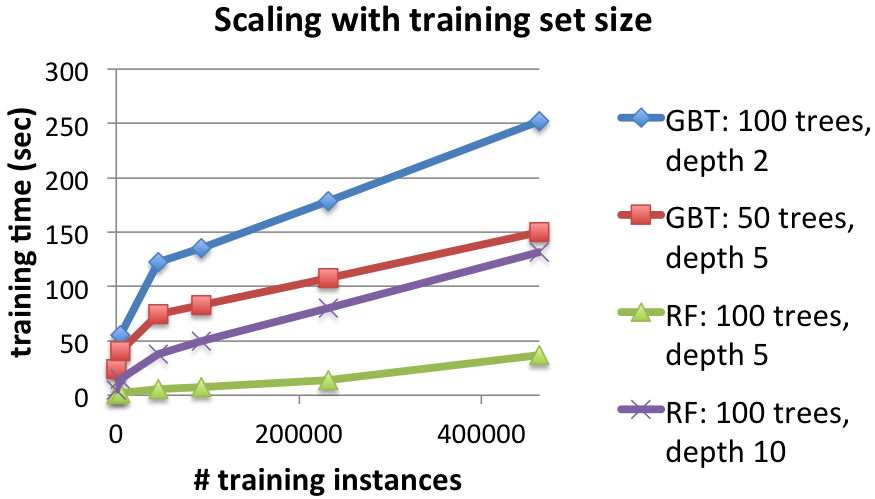
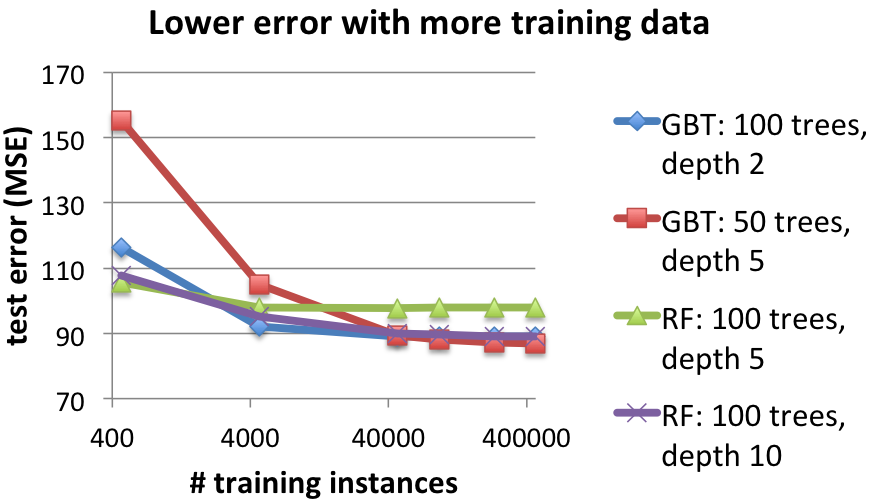
Details: 16 workers.
Strong scaling: Faster training with more workers
This final figure shows the effect of using a larger compute cluster to solve the same problem. Both methods are significantly faster when using more workers. For example, GBTs with depth-2 trees train about 4.7 times faster on 16 workers than on 2 workers, and larger datasets produce even better speedups.
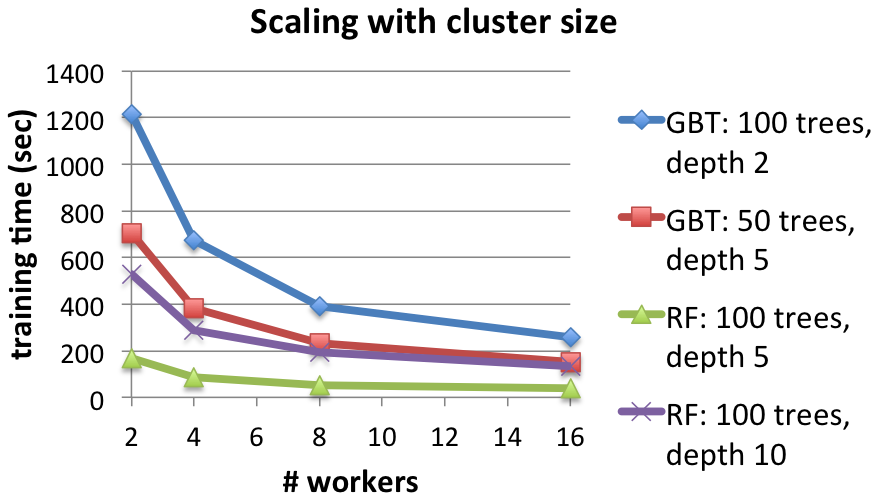
Details: 463,715 training instances.
What’s Next?
GBTs will soon include a Python API. The other top item for future development is pluggability: ensemble methods can be applied to almost any classification or regression algorithm, not only Decision Trees. The Pipelines API introduced by Spark 1.2’s experimental spark.ml package will allow us to generalize ensemble methods to be truly pluggable.
To get started using decision trees yourself, download Spark 1.2 today!
Further Reading
- See examples and the API in the MLlib ensembles documentation.
- Learn more background info about the decision trees used to build ensembles in this previous blog post.
Acknowledgements
MLlib ensemble algorithms have been developed collaboratively by the authors of this blog post, Qiping Li (Alibaba), Sung Chung (Alpine Data Labs), and Davies Liu (Databricks). We also thank Lee Yang, Andrew Feng, and Hirakendu Das (Yahoo) for help with design and testing. We will welcome your contributions too!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.