What's new for Spark SQL in Apache Spark 1.3
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
The Apache Spark 1.3 release represents a major milestone for Spark SQL. In addition to several major features, we are very excited to announce that the project has officially graduated from Alpha, after being introduced only a little under a year ago. In this blog post we will discuss exactly what this step means for compatibility moving forward, as well as highlight some of the major features of the release.
Graduation from Alpha
While we know many organizations (including all of Databricks' customers) have already begun using Spark SQL in production, the graduation from Alpha comes with a promise of stability for those building applications using this component. Like the rest of the Spark stack, we now promise binary compatibility for all public interfaces through the Apache Spark 1.X release series.
Since the SQL language itself and our interaction with Apache Hive represent a very large interface, we also wanted to take this chance to articulate our vision for how the project will continue to evolve. A large number of Spark SQL users have data in Hive metastores and legacy workloads which rely on Hive QL. As a result, Hive compatibility will remain a major focus for Spark SQL moving forward
More specifically, the HiveQL interface provided by the HiveContext remains the most complete dialect of SQL that we support and we are committed to continuing to maintain compatibility with this interface. In places where our semantics differ in minor ways from Hive's (i.e. SPARK-5680), we continue to aim to provide a superset of Hive's functionality. Additionally, while we are excited about all of the new data sources that are available through the improved native Data Sources API (see more below), we will continue to support reading tables from the Hive Metastore using Hive's SerDes.
The new DataFrames API (also discussed below) is currently marked experimental. Since this is the first release of this new interface, we wanted an opportunity to get feedback from users on the API before it is set in stone. That said, we do not anticipate making any major breaking changes to DataFrames, and hope to remove the experimental tag from this part of Spark SQL in Apache Spark 1.4. You can track progress and report any issues at SPARK-6116.
Improved Data Sources API
The Data Sources API was another major focus for this release, and provides a single interface for loading and storing data using Spark SQL. In addition to the sources that come prepackaged with the Apache Spark distribution, this API provides an integration point for external developers to add support for custom data sources. At Databricks, we have already contributed libraries for reading data stored in Apache Avro or CSV and we look forward to contributions from others in the community (check out spark packages for a full list of sources that are currently available).

Unified Load/Save Interface
In this release we added a unified interface to SQLContext and DataFrame for loading and storing data using both the built-in and external data sources. These functions provide a simple way to load and store data, independent of whether you are writing in Python, Scala, Java, R or SQL. The examples below show how easy it is to both load data from Avro and convert it into parquet in different languages.
Scala
Python
Java
SQL
Automatic Partition Discovery and Schema Migration for Parquet
Parquet has long been one of the fastest data sources supported by Spark SQL. With its columnar format, queries against parquet tables can execute quickly by avoiding the cost of reading unneeded data.
In the Apache Spark 1.3 release we added two major features to this source. First, organizations that store lots of data in parquet often find themselves evolving the schema over time by adding or removing columns. With this release we add a new feature that will scan the metadata for all files, merging the schemas to come up with a unified representation of the data. This functionality allows developers to read data where the schema has changed overtime, without the need to perform expensive manual conversions.
Additionally, the parquet datasource now supports auto-discovering data that has been partitioned into folders, and then prunes which folders are scanned based on predicates in queries made against this data. This optimization means that you can greatly speed up may queries simply by breaking up your data into folders. For example:
In Apache Spark 1.4, we plan to provide an interface that will allow other formats, such as ORC, JSON and CSV, to take advantage of this partitioning functionality.
Persistent Data Source Tables
Another feature that has been added in Apache Spark 1.3 is the ability to persist metadata about Spark SQL Data Source tables to the Hive metastore. These tables allow multiple users to share the metadata about where data is located in a convenient manner. Data Source tables can live alongside native Hive tables, which can also be read by Spark SQL.
Reading from JDBC Sources
Finally, a Data Source for reading from JDBC has been added as built-in source for Spark SQL. Using this library, Spark SQL can extract data from any existing relational databases that supports JDBC. Examples include mysql, postgres, H2, and more. Reading data from one of these systems is as simple as creating a virtual table that points to the external table. Data from this table can then be easily read in and joined with any of the other sources that Spark SQL supports.
This functionality is a great improvement over Spark's earlier support for JDBC (i.e., JdbcRDD). Unlike the pure RDD implementation, this new DataSource supports automatically pushing down predicates, converts the data into a DataFrame that can be easily joined, and is accessible from Python, Java, and SQL in addition to Scala.
Introducing DataFrames
While we have already talked about the DataFrames in other blog posts and talks at the Spark Summit East, any post about Apache Spark 1.3 would be remiss if it didn't mention this important new API. DataFrames evolve Spark’s RDD model, making it faster and easier for Spark developers to work with structured data by providing simplified methods for filtering, aggregating, and projecting over large datasets. Our DataFrame implementation was inspired by Pandas' and R's data frames, and are fully interoperable with these implementations. Additionally, Spark SQL DataFrames are available in Spark’s Java, Scala, and Python API’s as well as the upcoming (unreleased) R API.
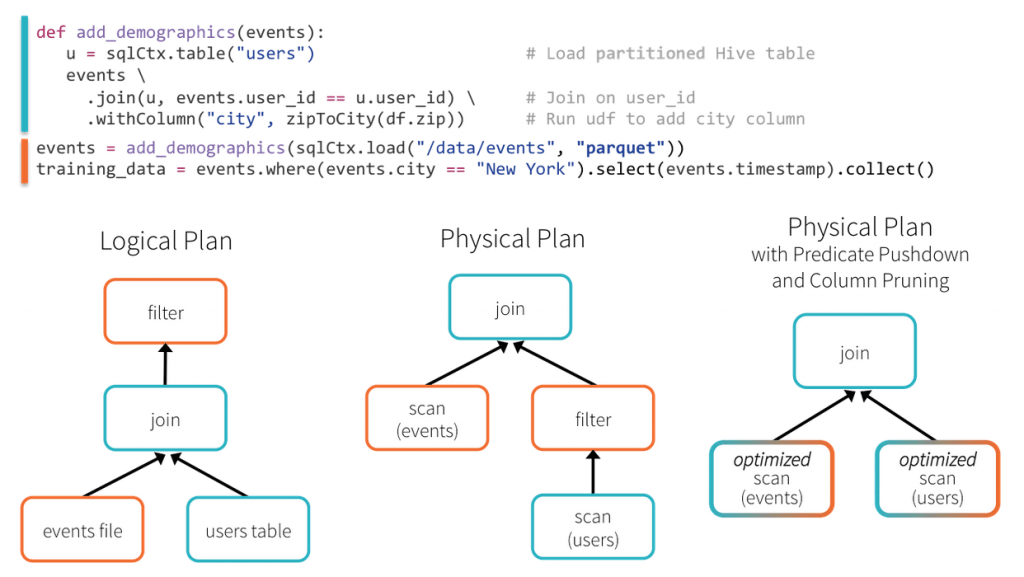
In this example, Spark SQL is able to push the filtering of users by their location through the join, greatly reducing its cost to execute. This optimization is possible even though the original author of the add_demographics function did not provide a parameter for specifying how to filter users!
This is only example of how Spark SQL DataFrames can make developers more efficient by providing a simple interface coupled with powerful optimization.
To learn more about Spark SQL, Dataframes, or Apache Spark 1.3, checkout the SQL programming guide on the Apache Spark website. Stay tuned to this blog for updates on other components of the Apache Spark 1.3 release!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.