Apache Spark 2.0: Rearchitecting Spark for Mobile Platforms
by Reynold Xin
Yesterday, to celebrate Apache Spark’s 5 year old birthday, we looked back at the history of the project. Today, we are happy to announce the next major chapter of Spark development: an architectural overhaul designed to enable Spark on mobile devices. Mobile computing is quickly rising to dominance, and by the end of 2017, it is estimated that 90% of CPU cycles will be devoted to mobile hardware. Spark’s project goal can be accomplished only when Spark runs efficiently for the growing population of mobile users. Already today, 100% of Spark’s users have mobile phones.
Designed and optimized for modern data centers and Big Data applications, Spark is unfortunately not a good fit for mobile computing today. In the past few months, we have been prototyping the feasibility of a mobile-first Spark architecture, and today we would like to share with you our findings. This post outlines the technical design of Spark’s mobile support, and shares results from several early prototypes. See also SPARK-6646 for community discussion on the issue.
Requirements
Must Have:
- Support running Spark on Android and iOS
- Facilitate the development of SoLoMo (social, local, mobile) applications
- Maintain source backward compatibility
- Support heterogeneous mobile phones within a single Spark cluster
Nice to Have:
- Support running Spark on Windows phones
- Support feature phones through J2ME
Compilation and Runtime
The Android Runtime (ART) already supports developing applications using Scala, as evidenced by this Scala IDE article on Android development.
iOS, however, has no built-in JVM support. Luckily, we can leverage multiple community efforts here:
- Use RoboVM, an ahead-of-time (AOT) compiler and library for developing iOS applications using Java.
- Use Scala+LLVM to compile Spark’s Scala code into LLVM bytecode. Given Apple’s strong stand behind the LLVM project, we believe this can achieve the highest level of performance.
- Since Swift looks very similar to Scala, we can create a project to automatically translate Scala source code into Swift, and then build the iOS package using XCode.
- Use Scala.js to compile Spark into JavaScript, and execute Spark in the Nitro JavaScript engine (Safari).
Option 4 is preferred because not only does it support iOS, but also all platforms using a single package. On iOS and Android, Spark can be executed by the JavaScript engines. On servers, Spark can be executed in Node.js.
Performance Optimizations
JavaScript engines are one of the hottest areas of innovation, and thus we fully expect JavaScript engines to improve their performance rapidly. However, mobile JavaScript engines seem to lag behind their desktop variants. In particular, there appears to be no SIMD support for mobile JavaScript.
For parts of Spark that might benefit tremendously from SIMD, such as low level matrix operations, we can selectively rewrite those parts to generate LLVM bytecode.
Networking and Wire Protocol
Spark’s network transport builds on Netty, which in turn relies on java.nio or Linux epoll. Android ART appears to support java.nio out of the box, but we might need to rewrite Netty to use kqueue on iOS. Additionally, it is unclear whether low-level networking primitives such as zero-copy can be exposed in JavaScript. We will need to work more closely with Apple and Google to improve networking support in mobile JavaScript.
A viable alternative is to leverage grpc, an open-source high performance RPC library developed by Google. grpc provides out of the box support for all common platforms (Java, Objective C, etc) using HTTP/2.
Given the focus on debuggability, JSON should be the preferred wire serialization protocol over any existing binary formats.
True Locality Scheduling and DAGScheduler
To better support local, social, and mobile features of Spark, we change the locality field of RDDs to GPS coordinates, and locality scheduling can be refactored to support true locality that was never possible on servers.
In order to maintain source compatibility, we keep the old interface, and introduce a new true locality interface.
class RDD {
@deprecate("2.0", "use getPreferredTrueLocations")
def getPreferredLocations(p: Partition): Seq[String]
/**
* Returns the preferred locations for executing task on partition
* p. Concrete implementations of RDD can use this to enable
* locality scheduling.
*/
def getPreferredTrueLocations(p: Partition): Seq[LatLong]
}
The DAGScheduler needs to be updated to compute the geographical proximity of executors.
Extending TaskContext to the Mobile Platform
The TaskContext provides the contextual information for Spark tasks (e.g., job IDs, attempt IDs, etc.). While this was sufficient for running on server, the mobile platform has many other contextual information like GPS location, ongoing calls, etc. Such contextual information may be useful to optimize the processing of tasks without affecting the user experience of the smartphone/tablet user. For example, if a phone call is active, a new task may be paused until the call is over so that the call quality is not affected.
Basic Engine on iPhone and Androids
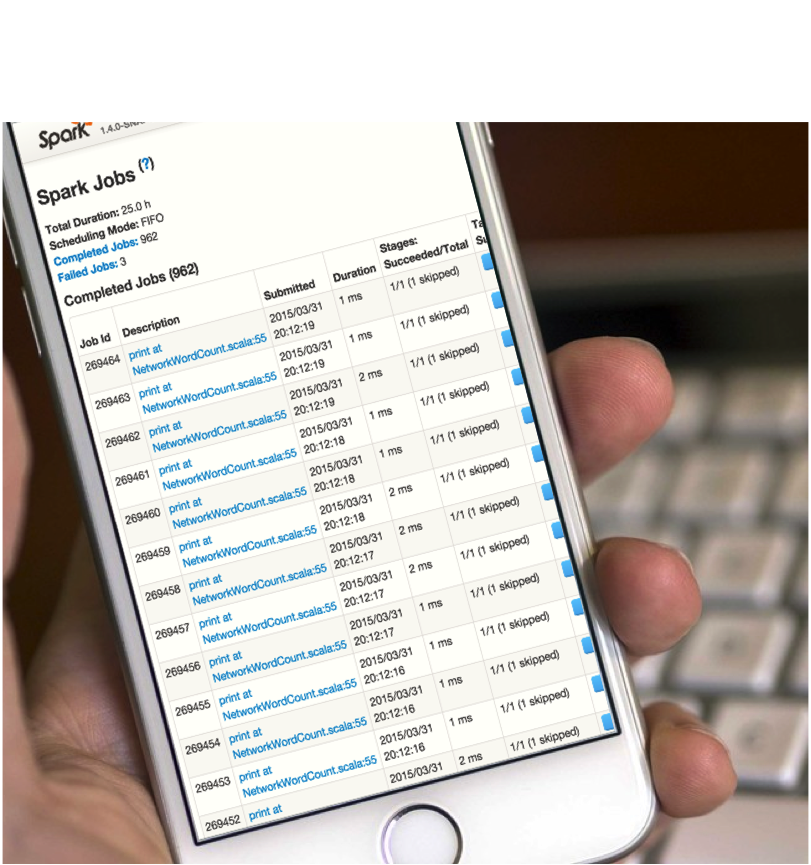
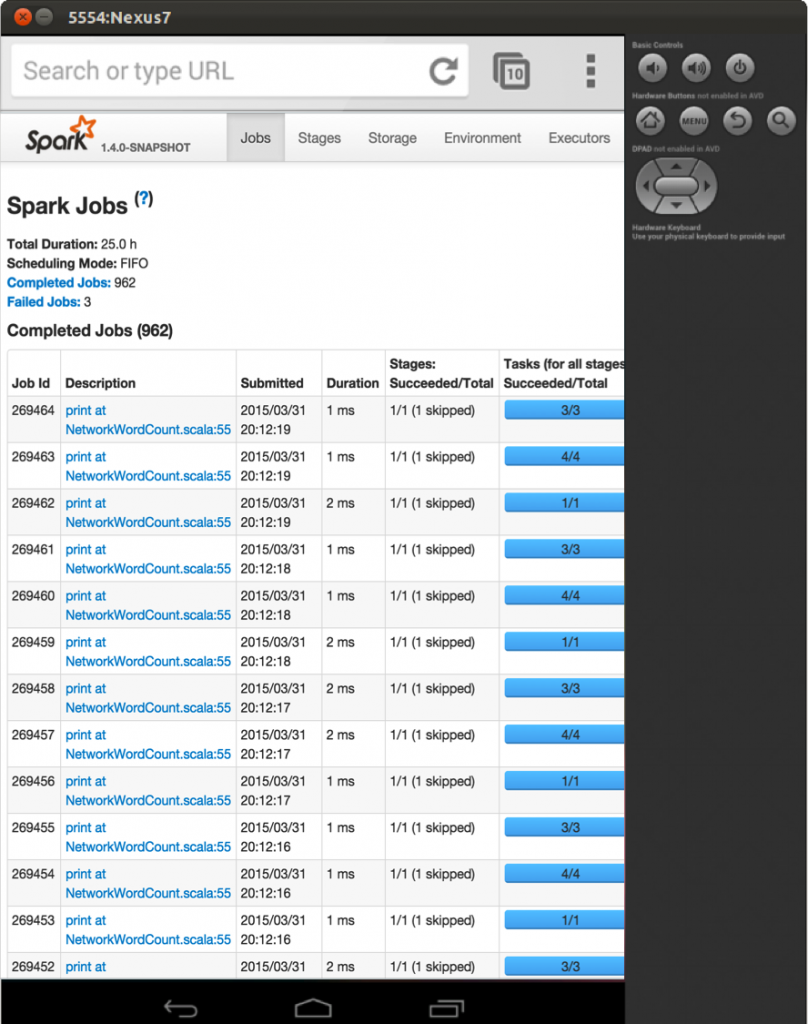
We have already built a few proof-of-concepts using iPhones to better understand the complexities of the mobile platform. Here are some screenshots from our prototype.
The screenshot at the beginning of the blog post shows a Spark Streaming NetworkWordCount example running on an iPhone. It is receiving data using sockets from a server running on Amazon EC2. We are also prototyping it on Android. Here is some early screenshots on the Android device emulator.
Prototyping Machine Learning Application
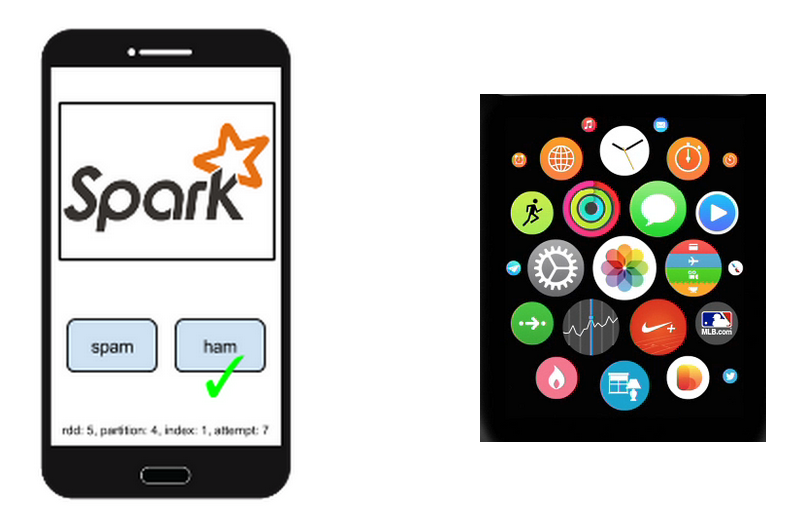
In real-world machine learning, labels are always hard and expensive to obtain. This won’t be an issue with Spark on Mobile. In the pipeline API for machine learning, we will provide a transformer that produces human tags.
tagger = HumanTagger(tags=[“spam”, “ham”], retries=10)
labeled = tagger.transform(images)
model = LogisticRegression().fit(labeled)
During transformation, images are displayed along with possible tags and users choose the correct tag for each image. To make sure the transformation is fault tolerant, we will randomize the ordering and retry 10 times for each record. Yes, RDDs are always deterministic. And of course, we support tagging with multi-labels, even on a wearable device:
In conclusion, this design doc proposes architectural changes to Spark to allow efficient execution on mobile platforms. Whether it is an octa-core x86 processor or a quad-core ARM processor, Spark should be the one unifying computing platform. We look forward to collaborating with the community to realize this effort, and hearing your feedback on the JIRA ticket: SPARK-6646.
[Just in case you didn't realize - it's April 1st!]
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.