New MLlib Algorithms in Apache Spark 1.3: FP-Growth and Power Iteration Clustering
by Jacky Li, Fan Jiang, Youhua Zhang, Stephen Boesch and Bing Xiao
This is a guest blog post from Huawei’s big data global team.
Huawei, a Fortune Global 500 private company, has put together a global team since 2013 to work on Apache Spark community projects and contribute back to the community. This blog post describes two new MLlib algorithms contributed from Huawei in Apache Spark 1.3 and their use cases: FP-growth for frequent pattern mining and Power Iteration Clustering for graph clustering.
FP-Growth: Scalable Frequent Itemset Mining
As smartphones and the mobile internet become more and more popular, a huge amount of data traffic is transmitted each second on the global internet. In a typical network of millions subscribers, traffic rates can reach terabytes per second, which drives gigabytes of event logs generated per second from the underneath network equipment. At Huawei, we are often interested in analyzing traffic patterns from these logs, so we can leverage usage information to make the network more efficient. A common technique for analyzing network data is frequent pattern mining. Frequent pattern mining can reveal the most frequently visited site in a particular period or find popular routing paths that generate most traffic in a particular region. Finding these patterns allows us to improve utilization of the network; for instance, information on routing hotspots can influence the placement of gateway and routers in the network.
FP-Growth
The FP-growth mining problem models its input as a set of transactions. Each transaction is simply a set of items and the algorithm looks for common subsets of items that appear across transactions. For a subset to be considered a pattern, it must appear in some minimum proportion of all transactions, termed the support. In the case of a telco network, items would be individual network nodes, and a transaction could represent one path of nodes. Then the algorithm would return sub-paths of the network that are frequently traversed.
A naive way to do this is to generate all possible itemsets and count their occurrence, which is not scalable because it quickly becomes a combinatorial explosion problem as the input data size increases. To solve this problem, we chose FP-growth, a classic algorithm that finds all frequent itemsets without generating and testing all candidates. And to make FP-growth work on large-scale datasets, we at Huawei has implemented a parallel version of FP-growth, as described in Li et al., PFP: Parallel FP-growth for query recommendation, and contributed it to Apache Spark 1.3.
Here is a brief description of the algorithm. The algorithm takes an RDD of transactions from user, and works in two steps to output frequent itemsets. In the first step, item frequency is calculated and infrequent items are filtered (because frequent itemsets must consist of frequent items). In the second step, suffix trees (FP-trees) are constructed and grown from the filtered transactions, and then frequent itemsets can be extracted from the suffix trees. The work is distributed based on the suffixes of the filtered transactions, and combineByKey is used to reduce the amount of shuffle data.
Scalability
We have compared MLlib’s FP-growth implementation against Mahout on our production datasets. The results are plotted as below.
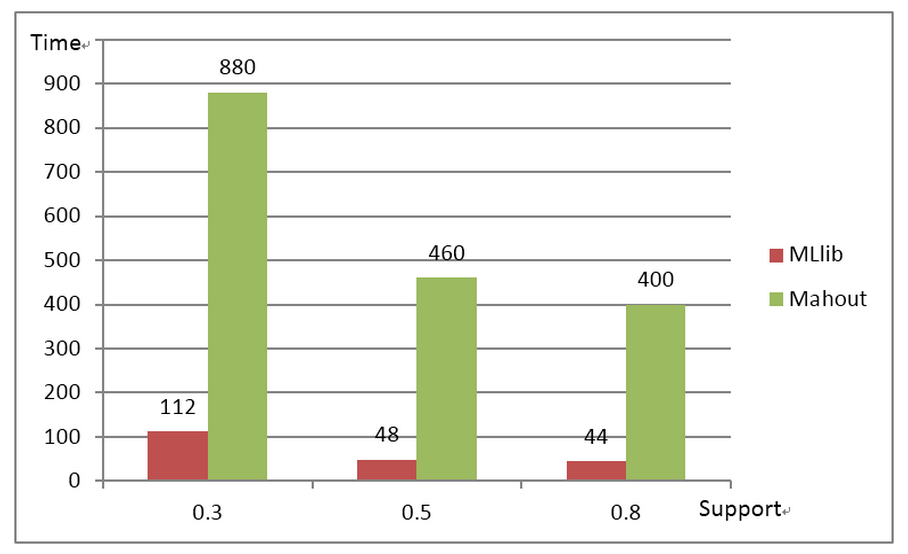
Experiment 1: Running times for different support levels using a 1.5GB data set.
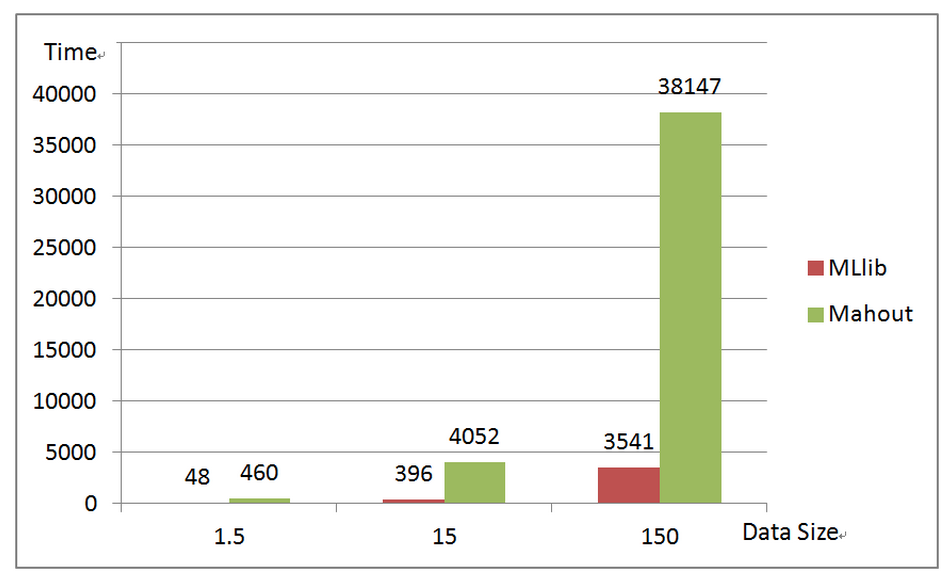
Experiment 2: Running times for different data sizes (GB).
As shown in the figures, MLlib is about 7~9 times faster than Mahout on a 1.5GB dataset, and MLlib achieves good scalability as the dataset grows 10 times and 100 times. In the largest test, MLlib is about 11 times faster than Mahout.
Examples
MLlib’s FP-growth is available in Scala/Java in Apache Spark 1.3. Its Python API was merged recently and it will be available in 1.4. Following example code demonstrates its API usage:
import org.apache.spark.mllib.fpm.FPGrowth
// the input data set containing all transactions
val transactions = sc.textFile("...").map(_.split(" ")).cache()
// run the FP-growth algorithm
val model = new FPGrowth()
.setMinSupport(0.5)
.setNumPartitions(10)
.run(transactions)
// print the frequent itemset result
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
For more information about MLlib’s FP-growth, please visit its user guide and check out full examples in Scala on GitHub.
Power Iteration Clustering: Spectral Clustering on GraphX
Communication service providers like Huawei must manage, operate, and optimize increasingly dynamic traffic workloads on heterogeneous networks. Among various algorithms being used in this effort, unsupervised learning including clustering plays an important role, for example, in identifying similar behaviors among users or network clusters. Graph clustering algorithms are commonly used in the telecom industry for this purpose, and can be applied to data center management and operation.
Power Iteration Clustering
We have implemented Power Iteration Clustering (PIC) in MLlib, a simple and scalable graph clustering method described in Lin and Cohen, Power Iteration Clustering. PIC takes an undirected graph with similarities defined on edges and outputs clustering assignment on nodes. PIC uses truncated power iteration to find a very low-dimensional embedding of the nodes, and this embedding leads to effective graph clustering.
PIC is a graph algorithm and it can be easily described in a graph language. So it was natural to implement PIC using GraphX in Spark and take advantage of GraphX’ graph processing APIs and optimization. MLlib’s PIC is among the first MLlib algorithms built upon GraphX. In particular, we store the normalized similarity matrix as a graph with normalized similarities defined as edge properties. The edge properties are cached and remain static during the power iterations. The embedding of nodes is defined as node properties on the same graph topology. We update the embedding through power iterations, where aggregateMessages is used to compute matrix-vector multiplications, the essential operation in a power iteration method. Finally, k-means is used to cluster nodes using the embedding.
Examples
MLlib’s PIC is available in Scala/Java in Apache Spark 1.3. Its Python support will be added in a future release. The following example code demonstrates its API usage:
import org.apache.spark.mllib.clustering.PowerIterationClustering
// pairwise similarities
val similarities: RDD[(Long, Long, Double)] = ...
val pic = new PowerIteartionClustering()
.setK(3)
.setMaxIterations(20)
val model = pic.run(similarities)
model.assignments.collect().foreach { a =>
println(s"${a.id} -> ${a.cluster}")
}
A more concrete example can be found at PowerIterationClusteringExample, and the following is a clustering assignment produced by it with five circles:
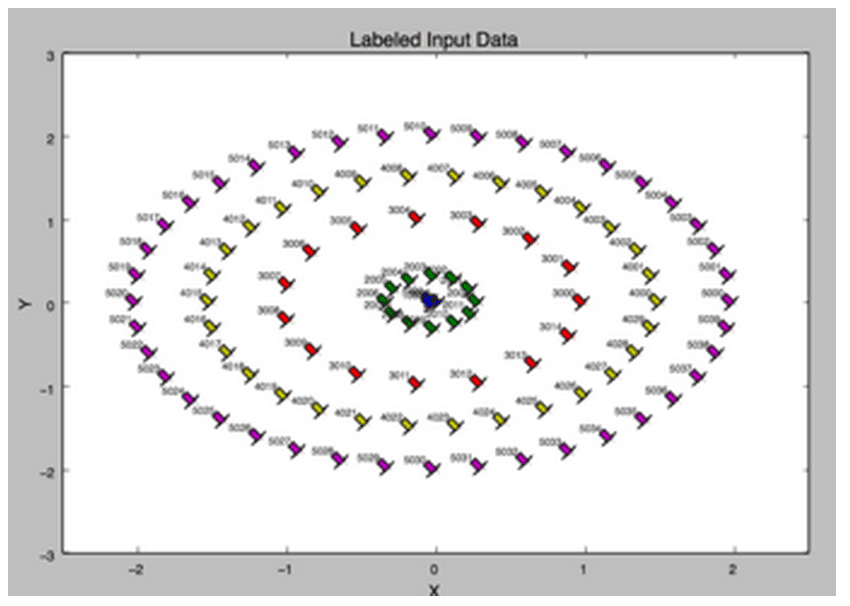
What we notice is that PIC is able to distinguish clearly the degree of similarity – as represented by the Euclidean distance among the points – even though their relationship is non-linear. For more information about PIC in MLlib, please visit its user guide.
Summary
Both FP-growth and PIC are included in Apache Spark 1.3. So you can download it now and try them out. At Huawei, our team is working on improving MLlib’s FP-growth implementation further and exploring possible enhancements to PIC. In addition, we plan to work on MLlib’s pipeline API, such as model persistence and re-deployment of the models, and share use cases of MLlib algorithms from our customers.
Acknowledgement
Xiangrui Meng at Databricks provided tremendous help to us, including design discussions and code reviews. We also want to thank all community members who helped code reviews and expanded the work, e.g., adding Python support and model import/export.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.