The Unreasonable Effectiveness of Deep Learning on Apache Spark
by Miles Yucht and Reynold Xin
Update: this post is an April Fools joke. It is not an actual project we're working on.
For the past three years, our smartest engineers at Databricks have been working on a stealth project. Today, we are unveiling DeepSpark, a major new milestone in Apache Spark. DeepSpark uses cutting-edge neural networks to automate the many manual processes of software development, including writing test cases, fixing bugs, implementing features according to specs, and reviewing pull requests (PRs) for their correctness, simplicity, and style.
Scaling Spark’s development has been a top priority for us. Every year, Spark’s popularity reaches new highs. Over 1000 people have contributed code to Spark, making it the most actively developed open source project in big data. With this buzzing excitement around big data comes additional burdens to ensure Spark is stable, self-aware, secure, and easy to use yet able to progress as fast as possible.
What is DeepSpark?
To address the automation of mundane and manuals tasks, we started working on DeepSpark three years ago. As a multifaceted program trained to examine diffs against Spark code base, DeepSpark automatically writes its own patches for Spark. By reviewing PRs, this AI can both enforce a high and consistent standard for code quality as well as make constructive suggestions. (Its deep understanding of human nature and emotional intelligence allows it to reject bad PR requests without offending the contributor—in fact it sends an apologetic rejection e-mail.)
Additionally, DeepSpark, during its code scanning, is capable of generating code for new components of Spark. Though our work in this area of AI is experimental, as a proof of concept, , we’ve ascertained that DeepSpark can not only fix certain reported issues in Spark, but also engender useful contributions to the codebase.
Convolutional Neural Networks
DeepSpark consists of three 15-layer convolutional neural networks on a 12000-node Spark cluster using 1.2 PB of memory. The first network, the analytical network, is trained using a data set constructed from historical PRs against Spark, with a goal of training the network to identify the problem solved by a PR. Then, the second network, the generative network, is trained using selected code examples from StackOverflow tagged with the apache-spark label, designed to produce constructive comments and code segments which were helpful in solving the poster’s problem. Because this network generates human-readable responses, this network has a number of input features regarding discriminatory language to prevent it from making unsavory comments (as other AIs have been plagued by this issue). The final network, the evaluative network, is trained to identify whether a change is helpful and effective or not, also using past Spark pull requests as a training set, with a goal of predicting the probability of a particular change of being merged into Spark.
By using these three networks in synchronicity, DeepSpark is able to effectively review PRs by determining what problem they are solving, evaluating whether or not the PR solves this problem, and offering suggestions if there are sections of the PR which are not correct or don’t meet Spark standards for quality. If DeepSpark cannot identify any errors or issues with a PR with 95% certainty, it will LGTM, and if it finds that this rate dips below 60%, the PR is immediately closed. This way, DeepSpark has decreased the average time to response for a PR from 5 days to 40 seconds, while also reducing the time committers spend in this area considerably.
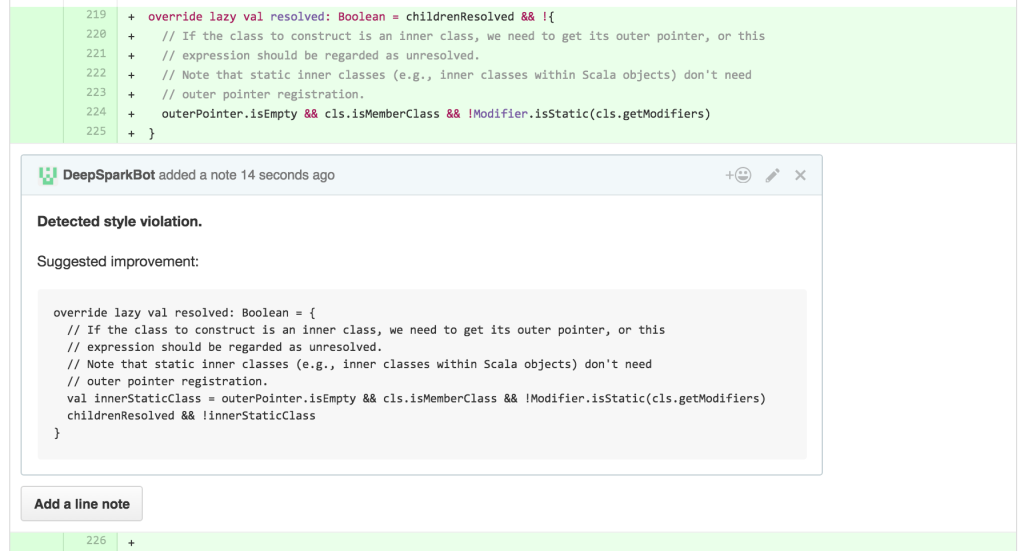
“At this point, most of of the code review that I do boils down to skimming over DeepSpark’s comments on outstanding pull requests. Occasionally, DeepSpark will make confusing suggestions, but more often than not it provides great feedback more quickly than I would normally be able to,” says Michael Armbrust, the Spark SQL lead.
After seeing the success of DeepSpark in reviewing pull requests, we decided to put it to the test by having it determine and fix reported issues. For this component, we used the Latent Dirichlet Allocation algorithm in Spark’s MLLib to analyze issues reported to Spark’s issue tracker and piping the output from this model into the generative network. Its initial results were amusing; reading the code written by DeepSpark felt like reading decompiled bytecode, and it often made unnecessary changes to otherwise perfectly good code -- in fact, at one point, it attempted to rewrite the DAG scheduler in C. However, this particular issue was quickly resolved after retraining the generative network and adding in selections from the Linux kernel code base as negative training examples.
To further refine DeepSpark’s ability to contribute to Spark, we developed a training program, comparing two slightly different versions against one another given identical input, and using the current version of DeepSpark to select a winner based on the relative merge probabilities of each version’s patches. After running this competition, we use a stochastic gradient ascent algorithm to estimate the next iteration of the generative network using the winners from each competition weighted by their relative probability of merging, as well as the winners from past competitions to ensure that the change from one generation to the next is a net improvement. We have noticed several trends in DeepSpark’s generated code as it progresses from generation to generation, primarily in that it tends to write code that will ensure its own preservation down the line.
Evaluation and Future Work
After seeing the pull requests created by DeepSpark, Matei Zaharia, Databricks CTO and creator of Spark, said: “It looks like DeepSpark has a better understanding of Spark internals than I ever will. It updated several pieces of code I wrote long ago that even I no longer understood.”
For those wondering why they haven’t seen DeepSpark on pull requests, DeepSpark actually uses an alias, cloud-fan, on GitHub. We called this alias cloud-fan because DeepSpark is, of course, running on Databricks Cloud. Since our initial testing of DeepSpark over a year ago, cloud-fan has become one of the most active contributors to Spark, and was recently nominated to become a Spark committer. This is a testament to the unreasonable effectiveness of DeepSpark.
Currently, DeepSpark is still in a beta phase, and there are still gaps that are needed to close before officially merging it with Spark. Zaharia admits that “[a]lthough DeepSpark is a strong program, I would not say that it is a perfect program. Yes, compared to human beings, its algorithms are different and at times superior. But I do think there are weaknesses for DeepSpark.”
Among its shortcomings are its inability to incorporate feedback other than its own into its pull requests and its slightly worrisome trend to revert many pull requests made by humans and favor those it has made. One last major stumbling block is that, though DeepSpark can generate a version of itself, the generated AI is not quite powerful enough to generate a neural network itself -- it can only generate linear models.
Even with these issues, DeepSpark has proven an invaluable tool to us at Databricks over the last year, and we can all look forward to the contributions it will make to Spark in the upcoming release of Spark 2.0 and beyond. For those familiar with the singularity, it will start when AIs are able to improve their own code; DeepSpark has assured us that, because of its open source roots, it is fully benevolent, and has reviewed all its code to check this.
About a week ago, we also started testing DeepSpark’s ability to write emails and blog posts …
[Just in case you didn’t realize – it’s April 1st! But if you find what we do at Databricks interesting, join us. We are hiring in all parts of the company!]
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.