Approximate Algorithms in Apache Spark: HyperLogLog and Quantiles
by Tim Hunter, Hossein Falaki and Joseph Bradley
Introduction
Apache Spark is fast, but applications such as preliminary data exploration need to be even faster and are willing to sacrifice some accuracy for a faster result. Since version 1.6, Spark implements approximate algorithms for some common tasks: counting the number of distinct elements in a set, finding if an element belongs to a set, computing some basic statistical information for a large set of numbers. Eugene Zhulenev, from Collective, has already blogged in these pages about the use of approximate counting in the advertising business.
The following algorithms have been implemented against DataFrames and Datasets and committed into Apache Spark’s branch-2.0, so they will be available in Apache Spark 2.0 for Python, R, and Scala:
- approxCountDistinct: returns an estimate of the number of distinct elements
- approxQuantile: returns approximate percentiles of numerical data
Researchers have looked at such algorithms for a long time. Spark strives at implementing approximate algorithms that are deterministic (they do not depend on random numbers to work) and that have proven theoretical error bounds: for each algorithm, the user can specify a target error bound, and the result is guaranteed to be within this bound, either exactly (deterministic error bounds) or with very high confidence (probabilistic error bounds). Also, it is important that this algorithm works well for the wealth of use cases seen in the Spark community.
In this blog, we are going to present details on the implementation of approxCountDistinct and approxQuantile algorithms and showcase its implementation in a Databricks notebook.
Approximate count of distinct elements
In ancient times, imagine Cyrus the Great, emperor of Persia and Babylon, having just completed a census of all his empire, fancied to know how many different first names were used throughout his empire, and he put his vizier to the task. The vizier knew that his lord was impatient and wanted an answer fast, even if just an approximate.
There was an issue, though; some names such as Darius, Atusa or Ardumanish were very popular and appeared often on the census records. Simply counting how many people were living within the empire would give a poor answer, and the emperor would not be fooled.
However, the vizier had some modern and profound knowledge of mathematics. He assembled all the servants of the palace, and said: “Servants, each of you will take a clay tablet from the census record. For each first name that is inscribed on the tablet, you will take the first 3 letters of the name, called l1, l2 and l3, and compute the following number:
For example, for Darius (D = 3, A = 0, R = 17), you will get N = 16340.
This will give you a number for each name of the tablet. For each number, you will count the number of zeros that end this number. In the case of Hossein (N=17739), this will give you no zero. After each of you does that for each name on his or her tablet, you will convene and you will tell me what is the greatest number of zeros you have observed. Now proceed with great haste and make no calculation mistake, lest you want to endure my wrath!”
At the end of the morning, one servant came back, and said they had found a number with four zeros, and that was the largest they all observed across all the census records. The vizier then announced to his master that he was the master of a population with about 1.3 * 10^4 = 13000 different names. The emperor was highly impressed and he asked the vizier how he had accomplished this feat. To which the vizier uttered one word: “hyper-log-log”.
The HyperLogLog algorithm (and its variant HyperLogLog++ implemented in Spark) relies on a clever observation: if the numbers are spread uniformly across a range, then the count of distinct elements can be approximated from the largest number of leading zeros in the binary representation of the numbers. For example, if we observe a number whose digits in binary form are of the form 0…(k times)...01...1, then we can estimate that there are in the order of 2^k elements in the set. This is a very crude estimate but it can be refined to great precision with a sketching algorithm.
From the example above with the vizier and his servants, this algorithm does not need to perform shuffling, just map (each servant works on a tablet) and combine (the servants can make pairs and decide which one has the greatest number, until there is only one servant). There is no need move data around, only small statistics about each block of data, which makes it very useful in a large dataset setting such as Spark.
Now, in modern times, how well does this technique work, where datasets are much larger and when servants are replaced with a Spark cluster? We considered a dataset of 25 millions online reviews from an online retail vendor, and we set out to approximate the number of customers behind these reviews. Since customers write multiple reviews, it is a good fit for approximate distinct counting.
Here is how to get an approximate count of users in PySpark, within 1% of the true value and with high probability:
users: DataFrame[user: string]
users.select(approxCountDistinct("user", rsd = 0.01)).show()
This plot (fig. 1) shows how the number of distinct customers varies by the error margin. As expected, the answer becomes more and more precise as the requested error margin decreases.
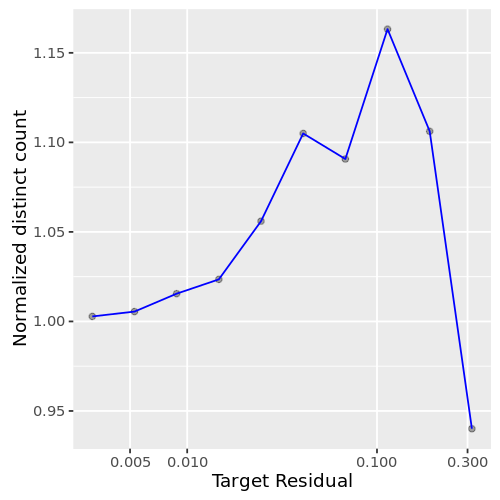
How long does it take to compute? For the analysis above, this plot (fig 2.) presents the running time of the approximate counting against the requested precision. For errors above 1%, the running time is just a minute fraction of computing the exact answer. For precise answers, however, the running time increases very fast and it is better to directly compute the exact answer.
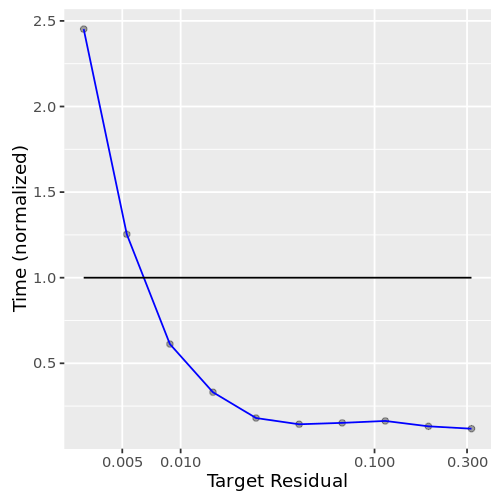
As a conclusion, when using approxCountDistinct, you should keep in mind the following:
- When the requested error on the result is high (> 1%), approximate distinct counting is very fast and returns results for a fraction of the cost of computing the exact result. In fact, the performance is more or less the same for a target error of 20% or 1%.
- For higher precisions, the algorithm hits a wall and starts to take more time than exact counting.
Approximate quantiles
Quantiles (percentiles) are useful in a lot of contexts. For example, when a web service is performing a large number of requests, it is important to have performance insights such as the latency of the requests. More generally, when faced with a large quantity of numbers, one is often interested in some aggregate information such as the mean, the variance, the min, the max, and the percentiles. Also, it is useful to just have the extreme quantiles: the top 1%, 0.1%, 0.01%, and so on.
Spark implements a robust, well-known algorithm that originated in the streaming database community. Like HyperLogLog, it computes some statistics in each node and then aggregates them on the Spark driver. The current algorithm in Spark can be adjusted to trade accuracy against computation time and memory. Based on the same example as before, we look at the length of the text in each review. Most reviewers express their opinions in a few words, but some customers are prolific writers: the longest review in the dataset is more than 1500 words, while there are several thousand 1-word reviews with various degrees of grammatical freedom.
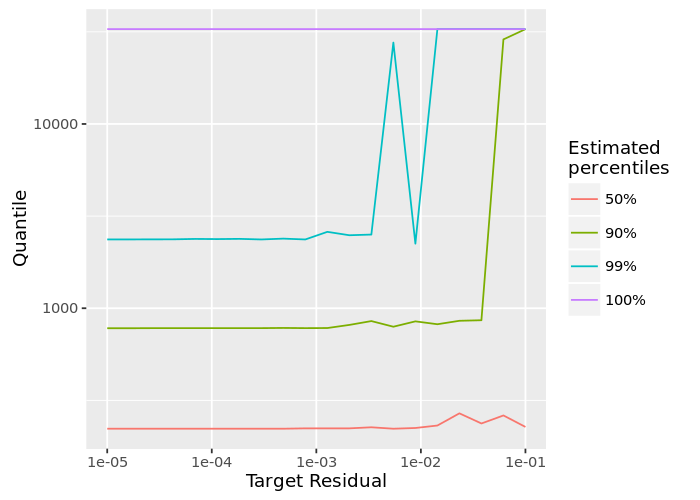
We plot (fig 3.) here the median length of a review (the 50th percentile) as well as more extreme percentiles. This graph shows that there are few very long reviews and that most of them are below 300 characters.
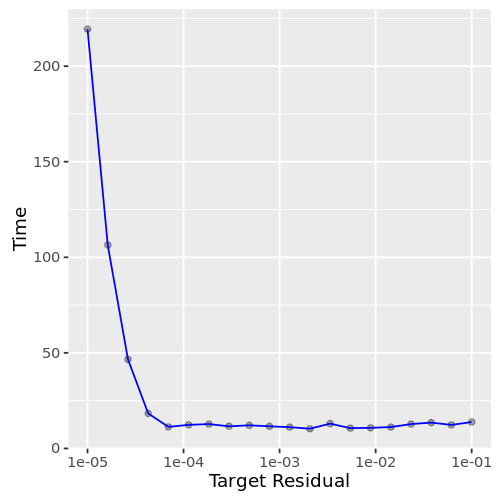
The behavior of approximate quantiles is the same as HyperLogLog: when asking for a rough estimate within a few percent of the exact answer, the algorithm is much faster than an exact computation (fig 4.). For a more precise answer, an exact computation is necessary.
Conclusion
We demonstrated details on the implementation of approxCountDistinct and approxQuantile algorithms. Though Spark is lighting-fast, sometimes exploratory data applications need even faster results at the expense of sacrificing accuracy. And these two algorithms achieve faster execution.
Apache Spark 2.0 will include some state-of-the art approximation algorithms for even faster results. Users will be able to pick between fast, inexact answers and slower, exact answers. Are there some other approximate algorithms you would like to see? Let us know.
These algorithms are now implemented in a Databricks notebook. To try it out yourself, sign up for an account with Databricks here.
Further Reading
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.