Parallelizing Genome Variant Analysis
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
This is a guest post from Deborah Siegel from the Northwest Genome Center and the University of Washington with Denny Lee from Databricks on their collaboration on genome variant analysis with ADAM and Spark.
This is part 2 of the 3 part series Genome Variant Analysis using K-Means, ADAM, and Apache Spark:
- Genome Sequencing in a Nutshell
- Parallelizing Genome Variant Analysis
- Predicting Geographic Population using Genome Variants and K-Means
Introduction
Over the last few years, we have seen a rapid reduction in costs and time of genome sequencing. The potential of understanding the variations in genome sequences range from assisting us in identifying people who are predisposed to common diseases, solving rare diseases, and enabling clinicians to personalize prescription and dosage to the individual.
In this three-part blog, we will provide a primer of genome sequencing and its potential. We will focus on genome variant analysis - that is the differences between genome sequences - and how it can be accelerated by making use of Apache Spark and ADAM (a scalable API and CLI for genome processing) using Databricks Community Edition. Finally, we will execute a k-means clustering algorithm on genomic variant data and build a model that will predict the individual’s geographic population of origin based on those variants.
This post will focus on Parallelizing Genome Sequence Analysis; for a refresher on genome sequencing, you can review Genome Sequencing in a Nutshell. You can also skip ahead to the third post on Predicting Geographic Population using Genome Variants and K-Means.
Parallelizing Genome Variant Analysis
As noted in Genome Sequencing in a Nutshell, there are many steps and stages of the analysis that can be distributed and parallelized in the hopes of significantly improving performance and possibly improving results on very large data Apache Spark is well suited for sequence data because it not only executes many tasks in a distributed parallel fashion, but can do so primarily in-memory with decreased need for intermediate files.
Benchmarks of ADAM + Spark (sorting genome reads and marking duplicate reads for removal) have shown scalable speedups, from 1.5 days on a single node to less than one hour on a commodity cluster (ADAM: Genomics Formats and Processing Patterns for Cloud Scale Computing).
One of the primary issues alluded to when working with current genomic sequence data formats is that they are not easily parallelizable. Fundamentally, the current set of tools and genomic data formats (e.g. SAM, BAM, VCF, etc.) are not well designed for distributed computing environments. To provide context, the next sections provide a simplified background of the workflow from genomic sequence to variant workflow.
Simplified Genome Sequence to Variant Workflow
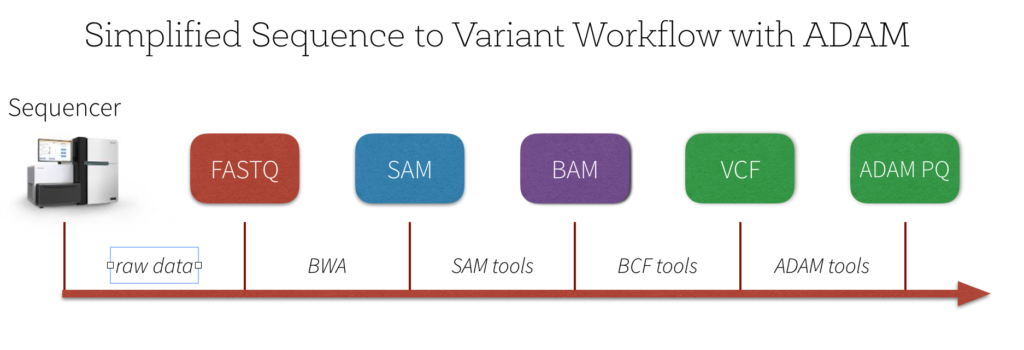
There are a number of quality control and pre-processing steps that must be initially performed prior to analyzing variants. A simplified workflow can be seen in the image below.
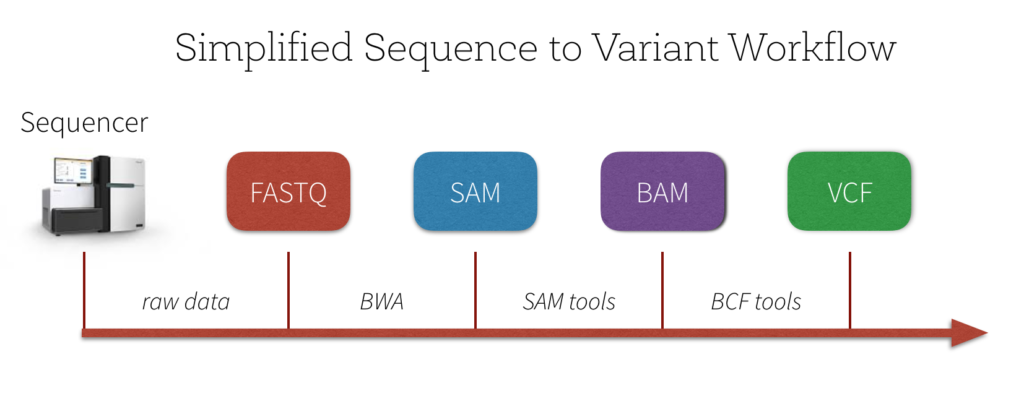
The output of the genome sequencer machine is in FASTQ format - text-based format storing both the short nucleotide sequence reads and their associated quality scores in ASCII format. The image below is an example of the data in FASTQ format.

A typical next step is to use a BWA (Burrows-Wheeler Alignment) sequence alignment tool such as Bowtie to align the large sets of short DNA sequences (reads) to a reference genome and create a SAM file - a sequence alignment map file that stores mapped tags to a genome. The image below (from the Sequence Alignment/Map Format specification) is an example of the SAM format. This specification has a number of terminologies and concepts that are outside the scope of this blog post; for more information, please reference the Sequence Alignment/Map Format specification.
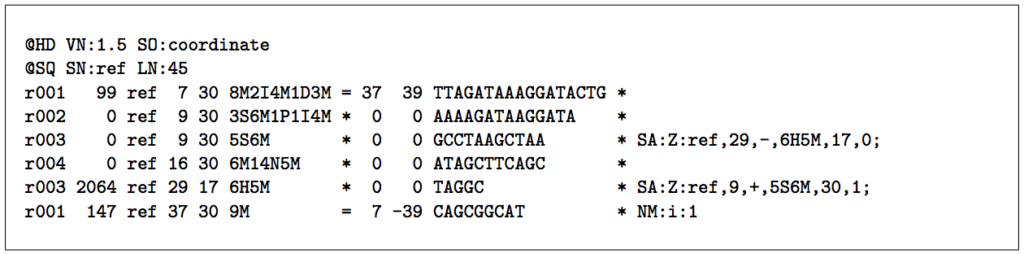
Source: Sequence Alignment/Map Format specification
The next step is to store the SAM into BAM (a binary version of SAM) typically by using SAMtools (a good reference for this process is Dave Tang’s Learning BAM file). Finally, a Variant Call Format (VCF) file is generated by comparing the BAM file to a reference sequence (typically this is done using BCFtools). Note, a great short blog post describing this process is Kaushik Ghose’s SAM! BAM! VCF! What?.
Simplified Overview of VCF
With the VCF file, we can finally start performing variant analysis. The VCF itself is a complicated specification so for a more detailed explanation, please reference the 1000 Genomes Project VCF (Variant Call Format) version 4.0 specification.
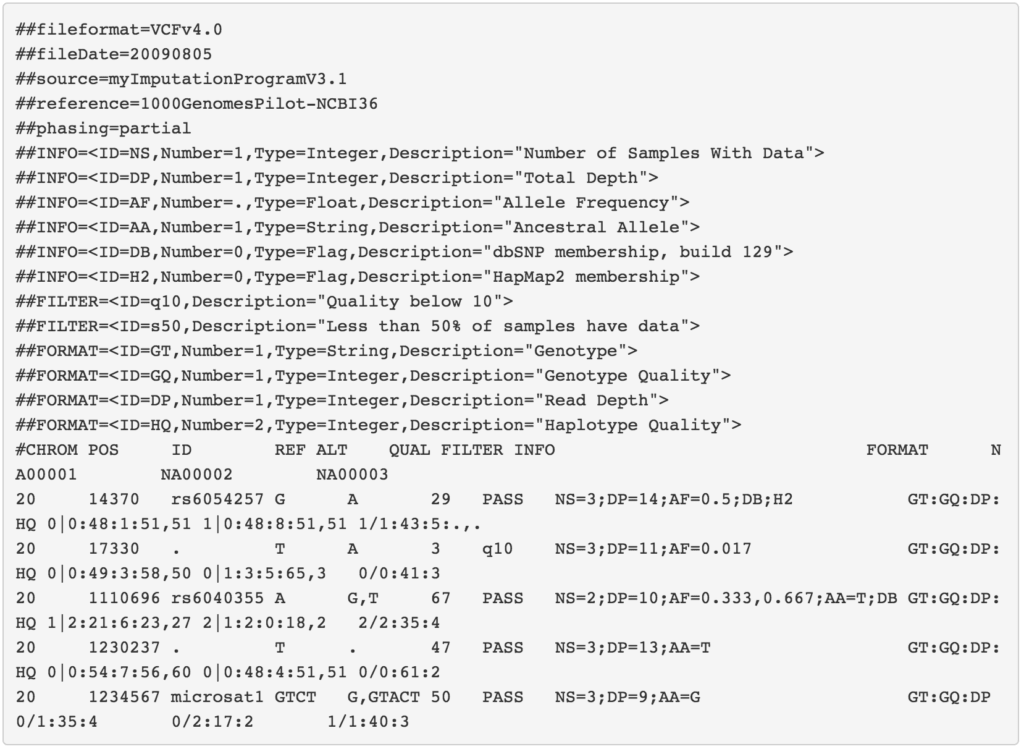
Source: 1000 Genomes Project VCF (Variant Call Format) version 4.0 specification
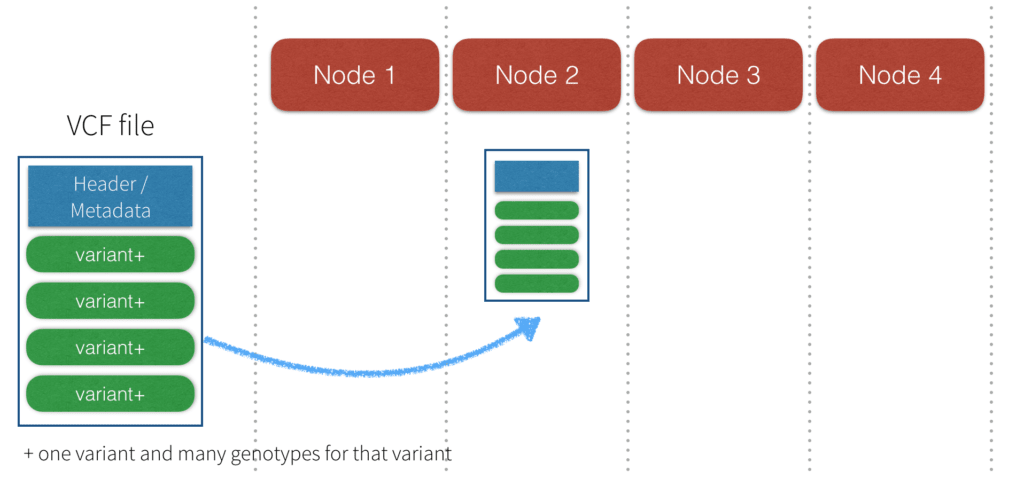
While there are various tools which can process and analyze VCFs, they cannot be used in a distributed parallel fashion. A simplified view of a VCF file is that it contains metadata, header, and the data. The metadata is often of interest and should be applied to each genotype. As illustrated in the image below, even if you have four nodes (i.e. Node 1, Node 2, Node 3, Node 4) to process your genotype data, you cannot efficiently distribute the data to all four nodes. With traditional variant analysis tools, the whole file including all of the data, metadata, and header must be sent to a single node. Additionally, the VCF file has more than one observation per row (variants and all their genotypes). This makes it impossible to analyze the genotypes in parallel without reformatting or using special tools.
Another key issue complicating the analysis of VCFs is the level of complexity surrounding the VCF format specification. Referring to the 1000 Genomes Project VCF (Variant Call Format) version 4.0 specification, there are a number of rules surrounding how to interpret the lines within the VCF. Therefore, any data scientist who wants to analyze variant data has to expend a large amount of effort to understand the specific VCFs they are working with and parsing.
Introducing ADAM
Big Data Genomics ADAM project was designed to solve problems around distributing sequence data and parallelizing the processing of sequence data as noted in the technical report ADAM: Genomics Formats and Processing Patterns for Cloud Scale Computing. ADAM is comprised of a CLI (tool kit for quickly processing genomics data), numerous APIs (interfaces to transform, analyze, and query genomic data), schemas, and file formats (columnar formats that allow for efficient parallel access to data).
bdg-formats Schemas
To address the complexities of parsing common types of sequence data - such as reads, reference oriented data, variants, genotypes, and assemblies - ADAM utilizes , a set of extensible Apache Avro schemas that are built around data types themselves rather than a file format. In other words, the schemas allows ADAM (or other any tools) to more easily query data instead of building custom code to parse each line of data depending on the file format. These data formats are highly efficient - they are easily serializable, and the information about each particular schema, such as data types, does not have to be sent redundantly with each batch of data. The nodes in your cluster are made aware of what the schema is in an extensible way (data can be added with an extended schema, and analyzed together with data under the old schema).
Parallel distribution via ADAM Parquet
ADAM Parquet files (when compared to binary or text VCF files) enable fast processing because they support parallel distribution of sequence data. In the earlier image of the VCF file, we saw that the entire file must be sent to one node. With ADAM Parquet files, the metadata and header are incorporated into the data elements and schema, and the elements are “tidy” in that there is one observation per element (one genotype of one variant).
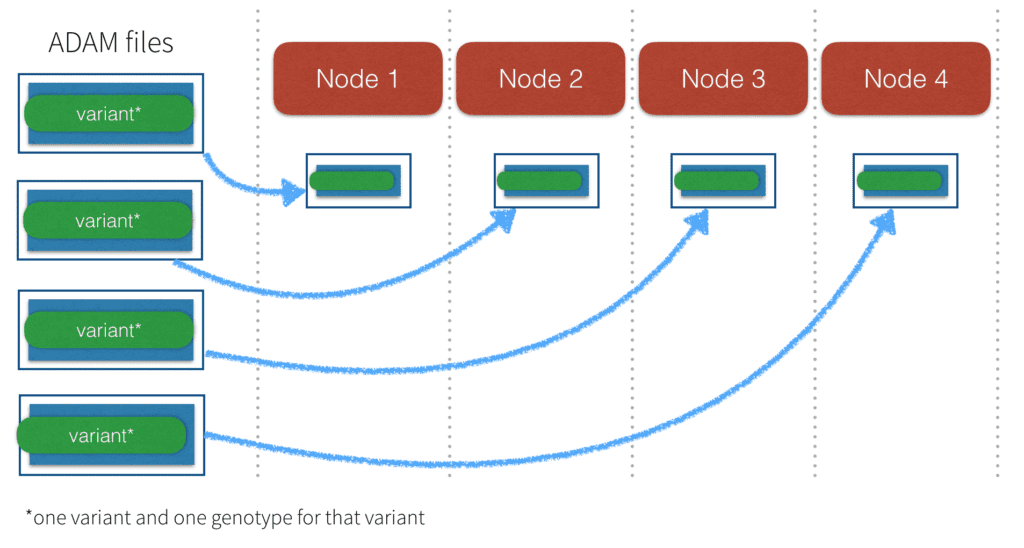
This enables the files to be distributed across multiple nodes. It also makes it simple to filter elements for just the data you want, such as genotypes for a certain panel, without using special tools. ADAM files are stored in the Parquet columnar storage format which is designed for parallel processing. As of GATK4, the Genome Analysis Toolkit is also able to read and write ADAM Parquet formatted data.
Updated Simplified Genome Sequence to Variant Workflow
With defined schemas (bdg-format) and ADAM’s APIs, data scientists can focus on querying the data instead of parsing the data formats.
Next Steps
In the next blog we will run a parallel bioinformatic analysis example Predicting Geographic Population using Genome Variants and K-Means. You can also review a primer on genome sequencing: Genome Sequencing in a Nutshell.
Attribution
We wanted to give a particular call out to the following resources that helped us create the notebook
- ADAM: Genomics Formats and Processing Patterns for Cloud Scale Computing (Berkeley AMPLab)
- Andy Petrella’s Lightning Fast Genomics with Spark and ADAM and associated GitHub repo.
- Neil Ferguson Population Stratification Analysis on Genomics Data Using Deep Learning.
- Matthew Conlen Lightning-Viz project.
- Timothy Danford’s SlideShare presentations (on Genomics with Spark)
- Centers for Mendelian Genomics uncovering the genomic basis of hundreds of rare conditions
- NIH genome sequencing program targets the genomic bases of common, rare disease
- The 1000 Genomes Project
As well, we’d like to thank for additional contributions and reviews by Anthony Joseph, Xiangrui Meng, Hossein Falaki, and Tim Hunter.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.