Another Record-Setting Spark Summit
by Wayne Chan, Dave Wang, Jules Damji and Denny Lee
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
The lure of San Francisco is indisputable as is its position as the preeminent high-tech hub. On day one of Spark Summit 2016, the largest community event dedicated to Apache Spark, drew more than 2500+ Spark enthusiasts from 720+ companies. Such a draw is a strong testament to Apache Spark’s open source roots, its fast-growing community of users and contributors, and an occasion to share war stories and learn from each other’s experiences.

To capture some of its moments, we’ve put together a quick recap of the keynotes and highlighted talks from Databricks’ speakers for the Spark enthusiasts who could not make it to San Francisco.
Day One: Apache Spark Takes the Spotlight
Apache Spark 2.0 Improvements and the Quickest Way to Learn Spark
In front of 2500+ attendees and another 3000+ watching the live stream, Matei Zaharia - the creator of the Apache Spark project and CTO of Databricks - kicked off the event with a keynote (video | slides) that unveiled the major updates to Apache Spark in the upcoming 2.0 release.
He also shared an exciting statistic with the audience: Apache Spark is now the highest-paying tech skill according to the 2016 Stack Overflow Developer Survey. In the spirit of contributing to Spark community growth, Matei announced the general availability of Databricks Community Edition, a free version of the Databricks platform, contributed to the community, for anyone to learn Apache Spark, and the launch of a series of free Massive Open Online Courses. Michael Armbrust concluded the talk with a live demo that took the audience through an analysis of live tweets on the Databricks Community Edition platform (watch video .
Michael Armbrust concluded the talk with a live demo that took the audience through an analysis of live tweets on the Databricks Community Edition platform (watch video .
Apache Spark’s Role in Machine Learning
The next two keynotes focused on how Spark has become a key component in machine learning innovation. Both Jeff Dean (Senior Fellow at Google) and Andrew Ng (Chief Scientist at Baidu) described Spark’s contributions to large-scale machine learning and enumerated several uses cases in the industry. Noting that Spark’s vast scalability is enabling machine learning to achieve higher levels of accuracy than before, Andrew succinctly summarized the future as: Spark + AI = Superpowers.

Putting Apache Spark to Work
To conclude the keynote sessions, Marvin Theimer, Distinguished Engineer at Amazon, shared his lessons learned from years of running production big data infrastructure. He spoke to the four main challenges of productionization : Scalability, High Availability, Maintainability, and Evolvability. Marvin ended his talk with a brief list of must-haves to satisfy these necessities to put big data in production:

Highlights of Databricks Speakers from Day One
After the keynotes, the attendees dispersed into several talk tracks for the rest of the day. In the Developer Track, Michael Armbrust’s (slides) and Tathagata Das’ (slides) talks dove deeper into the new Streaming DataFrames/Datasets API’s available in Spark 2.0 that optimizes execution plans and simplifies building end-to-end continuous applications.
In the Data Science Track, Xiangrui Meng - Apache Spark committers at Databricks - (slides) reviewed recent efforts by both the Spark and R communities to extend SparkR for scalable predictive analytics and demonstrated MLlib machine learning algorithms that have been ported to SparkR. And in the Use Case & Experience Track, Burak Yavuz and Yu Peng (slides), software engineers at Databricks, gave a “dog fooding” presentation on how Databricks uses Spark throughout the data pipeline for use cases such as ETL, data warehousing, and real-time analysis.
Day Two: Enterprise Adoption of Apache Spark
Databricks CEO and Co-founder Ali Ghodsi explained how the Databricks just-in-time data platform solves the “analytics gap” for today’s “data reality,” where data is spread, stored, and siloed in the cloud, data lakes, and data warehouses. By separating storage and compute, Databricks’ just-in-time platform offers an integrated and secure workspace, can access your data securely no matter where it’s stored, and manages your Spark clusters.
He also announced Databricks Enterprise Security (DBES) that promises to provide holistic security in every aspect of the entire big data lifecycle. With the completion of the first phase of DBES, enterprises gain the ability to control access to Spark clusters on an individual basis, manage user identity with a SAML 2.0 compatible identify management provider service, and end-to-end auditability.

Talks from Leaders in the Apache Spark Ecosystem
Day two also featured presentations from industry leaders who are heavily involved in driving the Spark ecosystem. Joseph Sirosh, Corporate VP of the Data Group at Microsoft and Doug Cutting, Chief Architect and Co-Founder of Apache Hadoop and Cloudera both noted the impact Spark is having across various use cases and highlighted how they are enabling organizations to quickly gain insights via advanced analytics from their data through Spark and their ecosystem of tools. Ziya Ma, VP of Big Data at Intel discussed how they are making Spark faster and more scalable with their forward-thinking innovations in silicon technology; and Rob Thomas, VP of Product Development at IBM Analytics covered how they are using Spark for cognitive analytics to enable real-time decision making.
Enterprise Track Features Databricks Impact
Databricks has been deployed by hundreds of organizations around the world. The enterprise track included talks from three organizations using Databricks. One of the largest video game companies in the world - Riot Games - utilized Databricks to improve the player experience for League of Legends (their flagship title with 67+ million active players monthly). Riot was able to improve game balance, network performance, and personalization with Databricks.
DNV GL, a global classification and technical assurance company, talked about using advanced analytics to predict energy usage through the analysis of prevailing weather condition data and sensor data collected from millions of smart meters. With Databricks, DNV GL was able to streamline data pipeline processing - allowing them to accelerate time-to-value by nearly 100 times compared to previous methods. To learn more, read the case study.
AIMIA, an enterprise technology company, shared their journey with Spark from attending local meetups to learn more about Spark to partnering with Databricks as the data platform geared to accelerate application development through machine learning and rapid product prototyping.
Highlight of Databricks Speakers from Day Two
Apache Spark Component Deep-Dives
Andrew Or and Yin Huai - Apache Spark committers at Databricks - kicked off the developer track with two deep-dive sessions. Andrew’s presentation gave the audience an inside look at Spark memory management and its performance & usability implications for the end user (slides). Yin provided an in-depth look at the Catalyst optimizer, the underpinning of all major APIs in 2.0 (slides). Joseph Bradley - an Apache Spark committer who primarily works on MLlib- discussed three key improvements in Apache Spark 2.0: persisting models for production, customizing Pipelines, and the latest models and APIs improvements for data science (slides).
Tips on Making Apache Spark Applications Faster, More Reliable, and Easier to Debug
Miklos Christine - a solution architect at Databricks - gave operational tips and best practices based on his extensive experience working with Databricks customers. He shared his learnings on how system design influences performance, what he does to configure Apache Spark clusters for optimal performance, and common misconfigurations that prevent users from getting the most of Apache Spark (slides).
Surprising Findings on Apache Spark Usage
Hossein Falaki - a data scientist at Databricks - performed a quantitative study of Databricks Community Edition beta users’ usage patterns and came up with some surprising conclusions (slides):
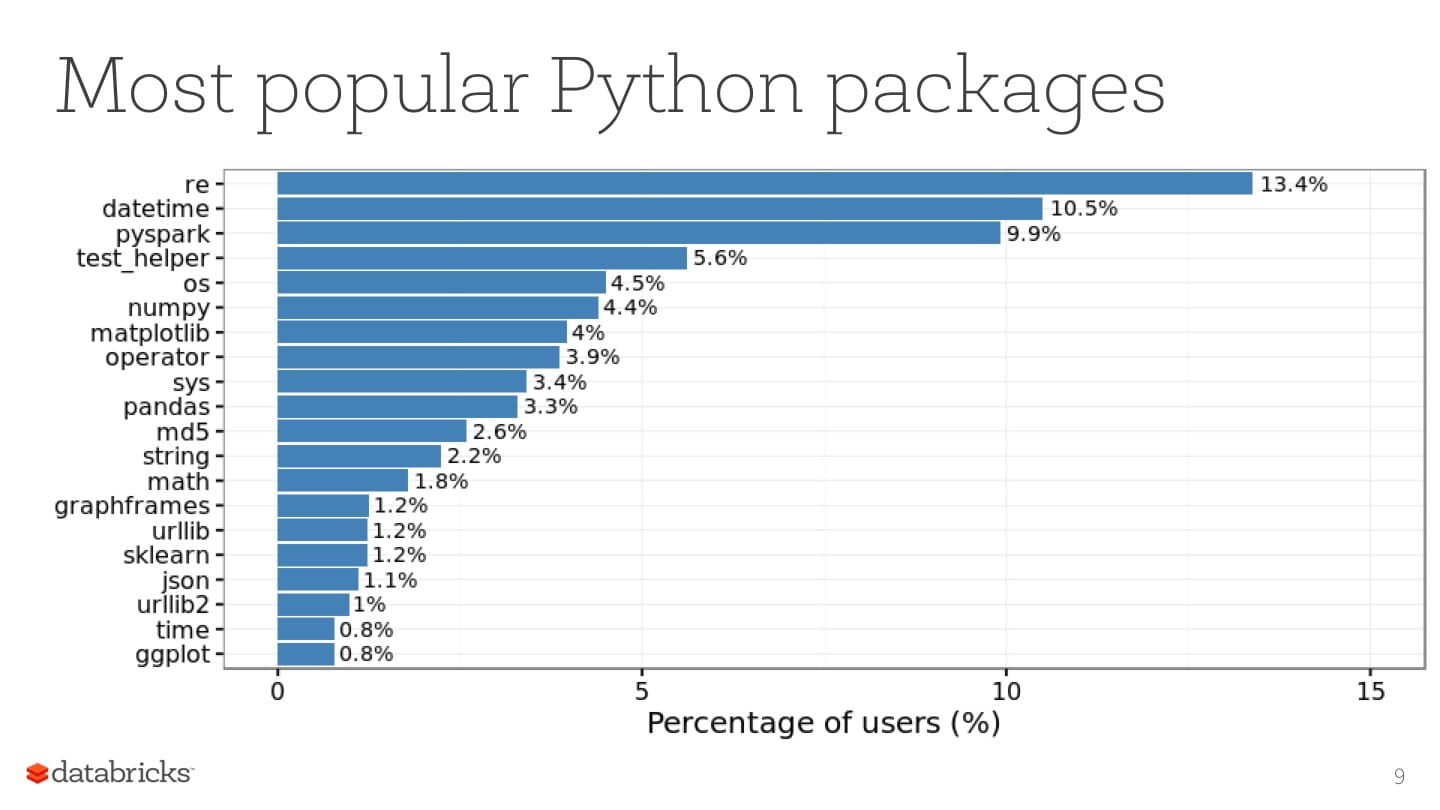
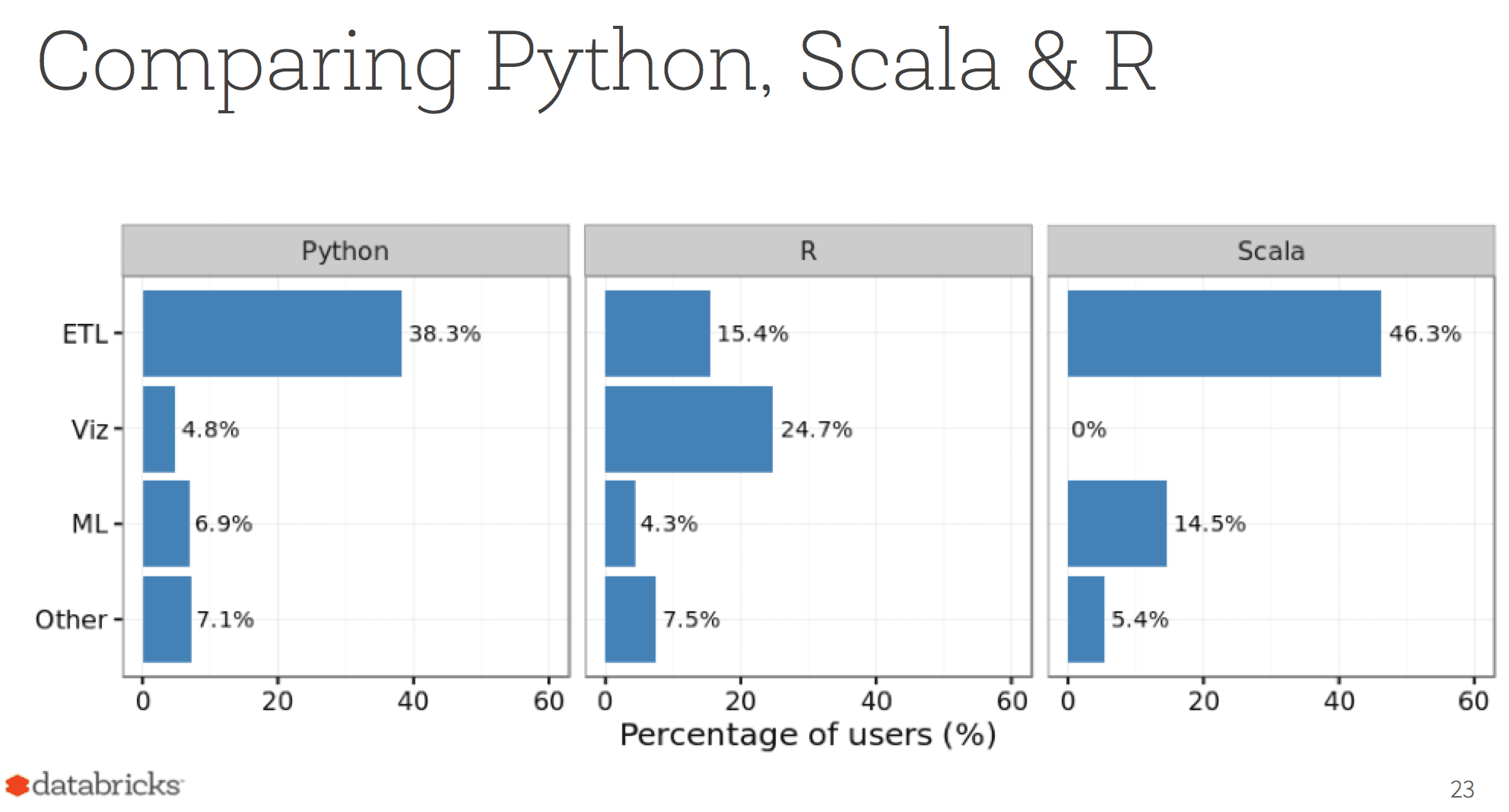
What's next?
Videos and slides of all talks have been posted on the Spark Summit website.
Follow Databricks on Twitter or subscribe to our newsletter to stay up to date with Apache Spark and Databricks news.
P.S. for Spark enthusiasts in Europe: The Summit is coming to Brussels October 25th. The call for papers is open, submit your idea today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.